Clear Sky Science · en
Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images
Why missing safety gear still slips through
Hard hats, vests, masks, gloves, and sturdy shoes are supposed to be non‑negotiable on construction sites, yet lapses still happen—and they can be deadly. Many projects now rely on cameras and artificial intelligence to flag workers who are missing required gear, but these systems struggle because real violations are rare and hard to capture on film. This study explores a way to train smarter detection systems by borrowing examples from ordinary street photos, making automated safety checks more reliable without waiting for accidents—or violations—to pile up.
Turning everyday photos into safety lessons
The core idea is simple: people in public places or offices rarely wear construction gear, so photos from those settings are full of examples of "what not to wear" on a job site. The challenge is that these scenes look very different from actual construction work—backgrounds, lighting, and camera angles all change the way people appear. The author treats these two worlds as different "domains": a source domain with abundant non‑PPE examples from general images, and a target domain with fewer but more realistic construction‑site images, many filmed from cameras mounted on workers’ helmets. The paper shows that by carefully aligning what the computer learns from both domains, the system can spot missing gear on real sites far more accurately than if it were trained on construction data alone.
How the new safety checker sees a scene
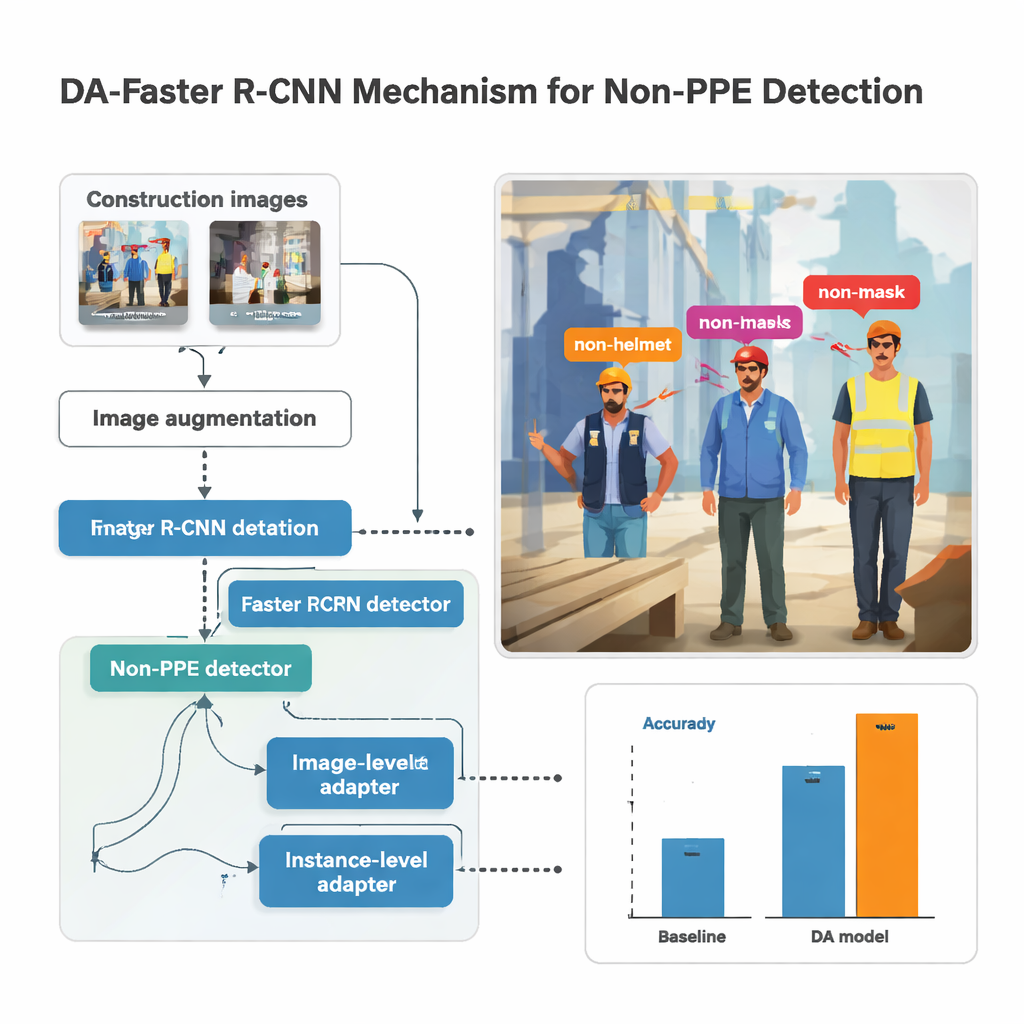
The research builds on a popular object‑detection system called Faster R‑CNN, which scans an image, proposes regions likely to contain people or body parts, and then classifies what it sees inside each box. Here, the detector is trained to recognize five kinds of missing gear: non‑helmet, non‑mask, non‑glove, non‑vest, and non‑shoes. Before images are fed to the model, they are heavily augmented—brightened or darkened, rotated, blurred, and distorted—to mimic shaky cameras, harsh sunlight, and awkward angles that are common on busy sites. This synthetic variety helps the model remain stable when real‑world footage is less than perfect, as it often is when captured from body‑worn cameras.
Teaching the system to ignore the background
Simply mixing street photos with construction shots is not enough; the model might learn to associate missing gear with city sidewalks instead of with people. To prevent that, the study introduces "domain adaptation" modules that gently push the system to focus on people and clothing rather than on the scene around them. One module looks at the image as a whole, nudging the network so that construction and non‑construction photos produce similar overall patterns, despite different lighting or equipment. Another works at the level of each detected person, making sure that the visual signature of, say, an unprotected head looks similar whether it appears on a scaffold or in a shopping street. These modules are trained in an adversarial way: a small classifier tries to tell which domain an image came from, while the main network learns to hide that information, keeping its focus on protective gear instead.
Putting the method to the test
The author assembled a sizable dataset by combining body‑worn camera footage from five construction sites in South Korea with several public image collections. After manual labeling of every instance of missing helmets, masks, gloves, vests, and safety shoes, the study trained hundreds of models with different neural‑network backbones and parameter settings. The best performer used a deep network called ResNet‑152 together with strong image augmentation and the domain‑adaptation modules. On previously unseen construction images, this setup achieved a mean Average Precision—an overall score for detection quality—of about 86.8 percent, while still running at roughly 33 frames per second, fast enough for near real‑time monitoring. Compared to more conventional supervised systems, the adapted model improved accuracy by up to 14 percentage points, and by as much as 39 points over a simpler baseline.
What this means for safer sites
For non‑specialists, the takeaway is that smarter training, not just bigger datasets, can make automated safety monitoring far more dependable. By learning from both everyday photos and real job sites, and by teaching the system to ignore unimportant background details, the proposed approach spots missing helmets, vests, gloves, masks, and safety shoes with high reliability, even when true violations are scarce. While the current work focuses on five types of gear and one main construction dataset, it offers a practical blueprint for future systems that could track harnesses, ropes, and other safety equipment across many sites, helping supervisors catch problems early and keep workers safer without staring at video screens all day.
Citation: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Keywords: construction safety, personal protective equipment, computer vision, domain adaptation, object detection