Clear Sky Science · en
A hybrid intelligent assessment model for English translation education with improved BERT and SVM
Why smarter translation grading matters
Every year, language teachers spend countless hours marking students’ translations. Deciding whether a sentence is “good enough” is slow, subjective, and can vary widely from one teacher to another. This paper explores whether artificial intelligence can share that load—offering quick, consistent scores and hints about what went wrong—without replacing the teacher. It presents a new computer model, called BERT-SVM EduScore, designed specifically to judge the quality of English translations in an educational setting.
From rough word matching to deeper understanding
For decades, computers have judged translations mainly by counting how many words or short phrases match a reference answer. Well-known tools such as BLEU or METEOR do this very quickly, but they struggle with natural language flexibility: two sentences can express the same meaning with quite different wording. In the classroom, where students experiment with synonyms and varied sentence structures, these old-style metrics can unfairly punish valid paraphrases and provide little guidance about specific mistakes. Researchers have therefore turned to newer methods that compare meanings rather than surface words, using powerful language models trained on huge text collections.
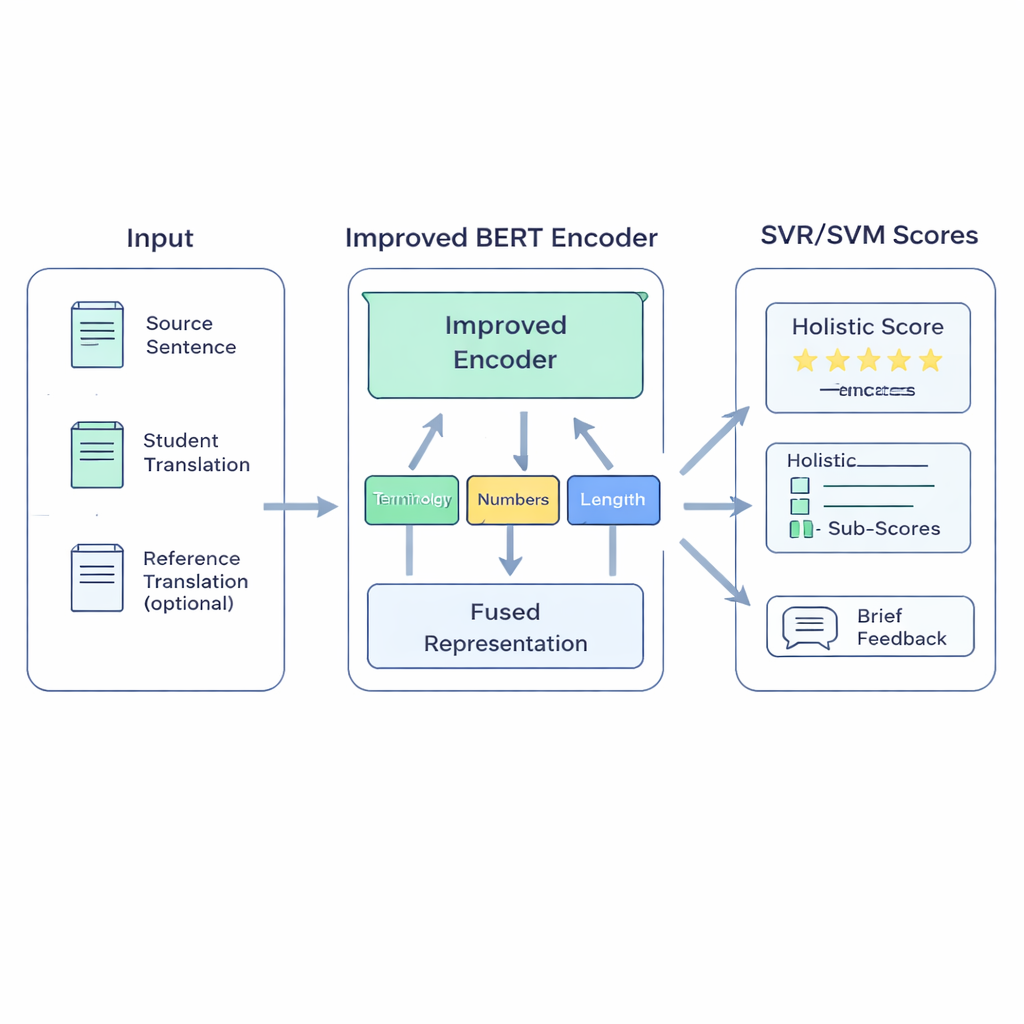
A hybrid model built for classrooms
The proposed BERT-SVM EduScore system combines two ideas: deep language understanding and classic, robust statistics. First, it uses an enhanced version of the BERT language model to read three pieces of text: the original sentence, the student’s translation, and, when available, a reference translation. BERT turns these into a rich numerical summary that reflects not only which words are present, but how well the meanings line up. On top of this, the system adds a small set of hand-crafted checks that teachers care about—such as whether technical terms are translated consistently, numbers and units are preserved, punctuation is sensible, and the length of the translation matches the original.
How the system learns to score like a teacher
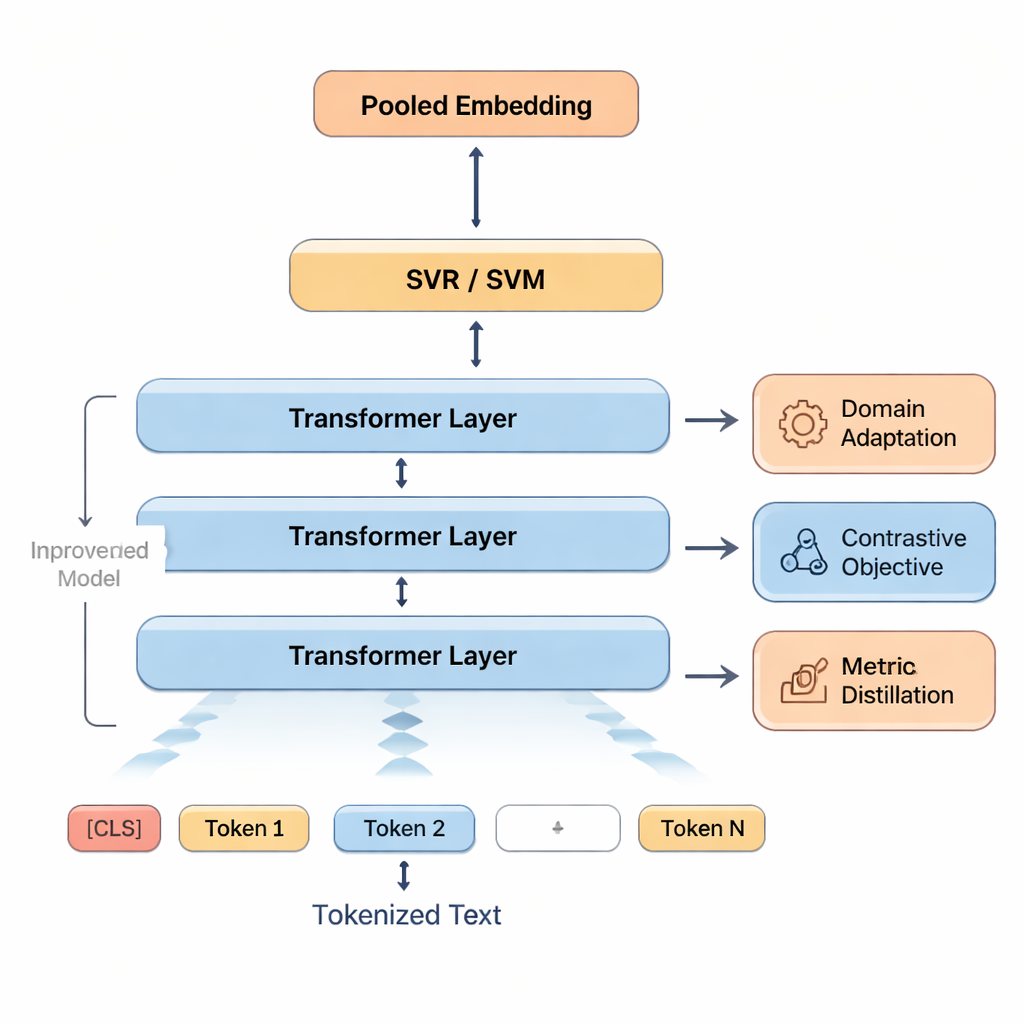
These signals are then fed into Support Vector Machines, a family of algorithms known for working well with limited data. One part predicts an overall score; other parts can produce separate scores for areas like accuracy or fluency, or sort translations into quality bands. To help the model adapt to classroom-style language, the authors first retrain BERT on texts similar to student work—an approach called domain adaptation. They further sharpen BERT’s sense of similarity and difference by having it practice telling apart good and slightly edited bad versions of sentences. Finally, when high-quality automatic metrics such as COMET or BLEURT are available, the system learns to imitate some of their judgments, borrowing their strengths while staying tuned to human ratings.
Putting the model to the test
The researchers evaluate BERT-SVM EduScore on a large public dataset containing English–Chinese machine translations scored by humans. Although these are not student assignments, their sentence-level ratings resemble classroom grading and provide a realistic stress test. The new system is compared with traditional word-based scores, newer meaning-based scores, and several strong neural models. It not only lines up more closely with human judgments—showing higher agreement and smaller average errors—but also runs quickly enough to process roughly 44 sentences per second on standard graphics hardware. Careful experiments show that adapting BERT to the right kind of text brings the biggest boost, while the extra learning tricks provide steady, smaller gains without noticeably slowing the system down.
What this could mean for teachers and students
In plain terms, the study shows that a carefully designed hybrid of deep learning and classic methods can grade translations more reliably than existing automatic tools, while remaining fast enough for real-time classroom use. BERT-SVM EduScore is not yet a plug-in replacement for human teachers: it has only been tested on machine translations, not real student work, and it has not gone through classroom trials or fairness checks. But the results suggest that such a system could soon help teachers by offering stable scores and highlighting likely problems—such as mistranslated terminology or missing numbers—so that human feedback can focus on deeper, more creative aspects of translation.
Citation: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
Keywords: translation assessment, language education, BERT, support vector machines, quality estimation