Clear Sky Science · en
Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation
Why tiny traces of gold matter
When geologists hunt for new gold deposits, they often work with soil samples that contain only a few parts per billion of the precious metal. Those ultra-low values are so close to the detection limits of laboratory instruments that many measurements come back simply as “below detection.” If these near-invisible traces are handled poorly, promising mineral zones can be missed or mapped inaccurately. This study introduces a smarter way to recover information from those censored values, helping explorers see clearer patterns in the subsurface from limited and noisy data.
Hidden signals in imperfect measurements
Soil and rock chemistry is a key tool for mineral exploration because small chemical changes can signal buried ore bodies. But instruments cannot measure infinitely small amounts. For gold in this study, any sample below a few parts per billion was treated as censored: the lab could say only that the true value was somewhere under that limit. Common quick fixes simply replace all such results with a constant number, like half the detection limit. While convenient, this practice flattens natural variation, blurs subtle anomalies and distorts how gold relates to other elements such as copper. The authors argue that to truly read the Earth’s chemical fingerprints, we must keep the uncertainty in those low values rather than overwrite them.
From geology map to cleaner background
The research focuses on a copper–gold prospect in the Northern Dalli area of central Iran, where 165 soil samples were collected on a tight grid over a known porphyry system. Gold was measured along with 29 other elements, and 14 samples fell below an assumed 5 parts per billion detection limit. Instead of feeding all the data straight into a model, the team first used a "fractal" concentration–number method to separate background values from stronger anomalies. By analyzing how the number of samples changes with increasing gold concentration on a log–log plot, they identified thresholds that divide background, weak anomalies and strong anomalies. Only the background population—including the censored values—was used to build the prediction models, reducing the risk that a few high-grade samples would dominate learning.
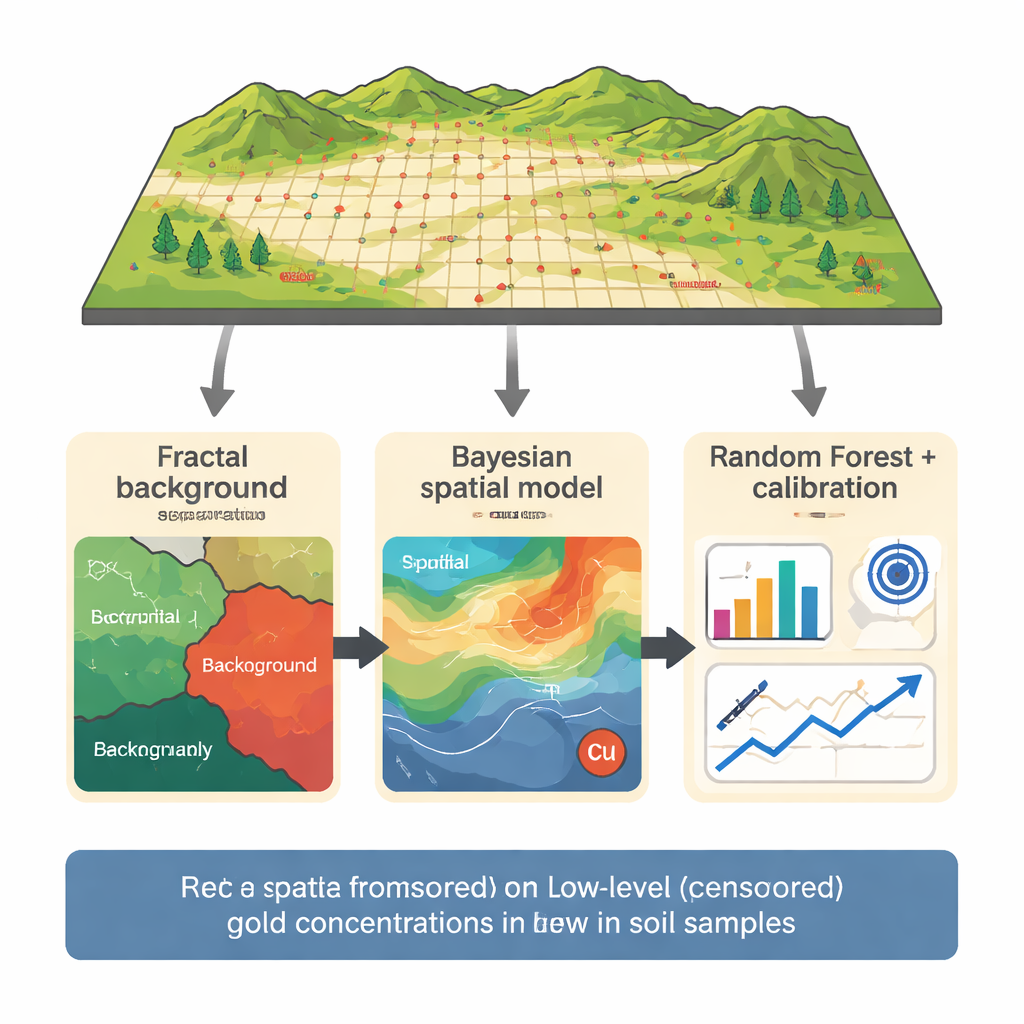
A probabilistic map guided by copper
To estimate the true gold content of censored samples, the authors then applied a Bayesian Gaussian Random Field model, a probabilistic spatial approach. This model treats gold concentration as a smoothly varying field across the map, influenced both by location and by copper content, which is strongly linked to gold in this porphyry setting. Instead of guessing a single number for each censored point, the model produces a full probability curve that respects the fact that the true value must lie below the detection limit. The result is a set of best estimates and uncertainty ranges for the 14 censored samples that are consistent with nearby measurements and with the gold–copper partnership observed in the rocks.
Machine learning, tuned where it matters most
Those probabilistic estimates then feed into a Random Forest model, a machine-learning method that combines many decision trees. The model uses gold, copper, iron, nickel, titanium and boron from the background population to learn patterns, with careful cross-validation so that each sample is tested only against models that have not seen it before. Initial predictions still tended to be a bit too high near the detection limit, a common issue when few very low values are available. To correct this, the authors performed a targeted calibration focused specifically on the 5–8 parts per billion range and then applied a simple scaling step to ensure that adjusted predictions stayed within physically meaningful bounds. This three-step chain—fractal separation, Bayesian spatial estimation and calibrated Random Forest—produced predictions that matched the actual low gold values far better than standard approaches.
Beating the old shortcuts
The study compared the new framework against both a basic Random Forest and two classic substitution rules that replace censored results with fixed fractions of the detection limit. Across several error measures, the calibrated and scaled hybrid model was the most accurate and the least biased, particularly for samples near the detection limit where small errors matter most. It also preserved realistic variation and maintained reasonable relationships between gold and copper, whereas substituting a single constant for all censored values destroyed that structure. In some higher-end censored samples, the new method’s relative error was hundreds of times smaller than that of traditional substitutions.
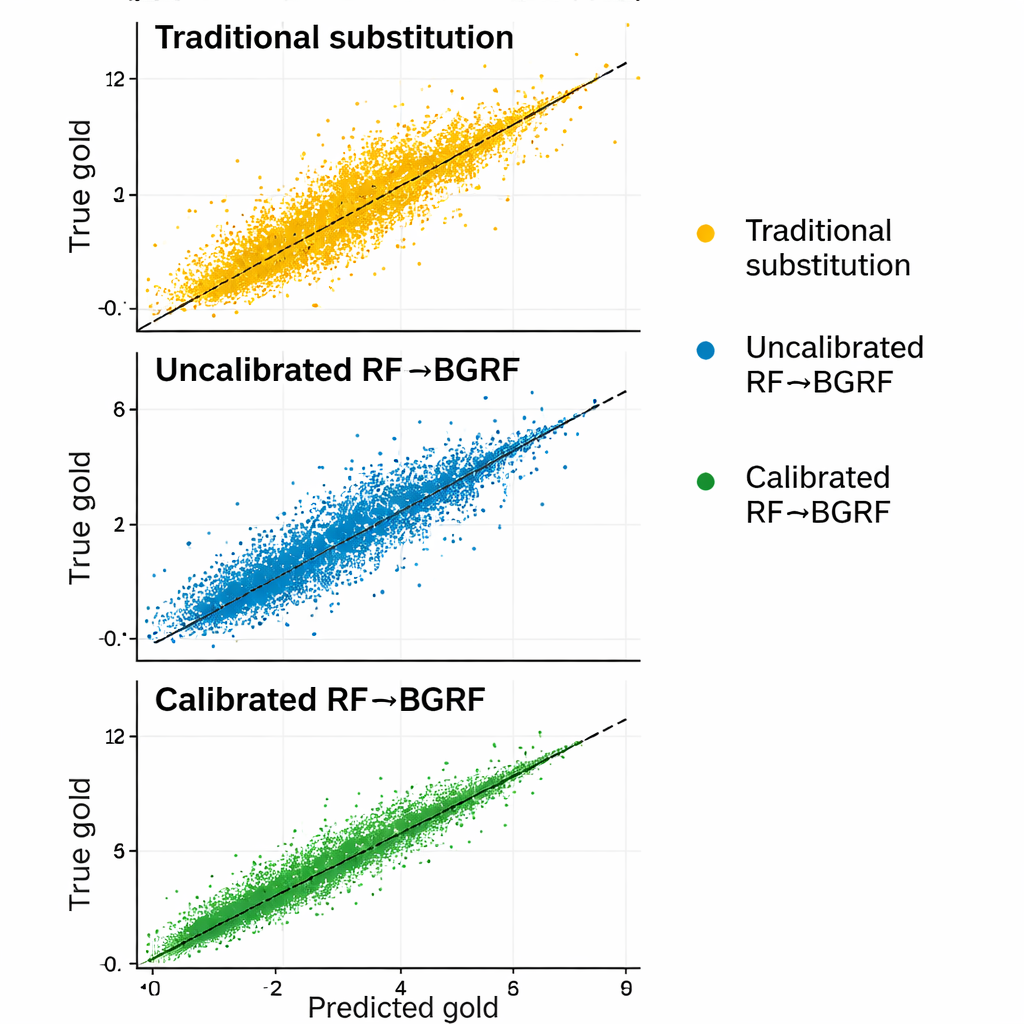
Clearer chemical pictures for exploration
For non-specialists, the takeaway is that how we treat “below detection” values in geochemical data can make or break the search for new mineral deposits. Rather than erasing uncertainty with crude replacements, this work shows that combining probabilistic spatial modeling, machine learning and simple calibration can recover much of the hidden information in low-level measurements. The result is cleaner maps of subtle gold patterns, more trustworthy anomaly detection and, ultimately, a better chance of finding ore bodies using fewer drill holes and more honest data.
Citation: Mahdiyanfar, H. Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation. Sci Rep 16, 4763 (2026). https://doi.org/10.1038/s41598-026-34999-4
Keywords: geochemical exploration, censored data, gold anomalies, Bayesian spatial modeling, machine learning in geology