Clear Sky Science · en
Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence
Why word meaning matters for fair grading
When students answer questions in their own words, computers that help teachers grade those answers must understand more than just shared keywords. A small word like “not” can flip the meaning of a sentence, and if automated systems miss that flip, students may be graded unfairly. This paper tackles that problem by designing a new way for computers to compare the meanings of sentences while paying special attention to how negation words change what is being said.
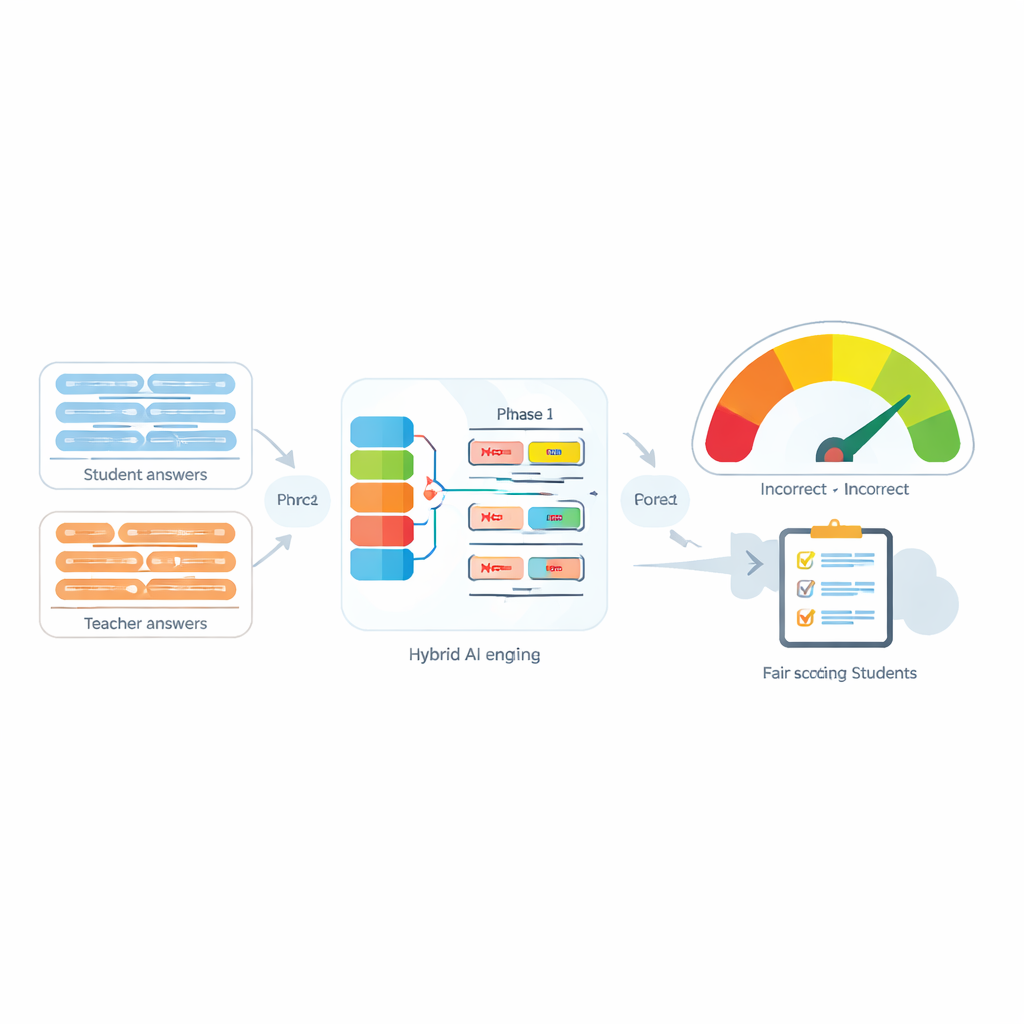
The challenge of tiny words with big impact
Automatic Evaluation Systems are increasingly used to ease teachers’ workloads by comparing a student’s response with an instructor’s model answer. Many modern tools do this by turning each sentence into a numerical “fingerprint” and then measuring how close those fingerprints are. These tools work reasonably well when there is no negation, but they often fail when words like “not”, “never”, or “no” appear. For example, “The method is accurate” and “The method is not accurate” can end up looking surprisingly similar to the computer, even though they mean opposite things. The authors show that not only the presence of negation, but also how many negation words appear and where they are placed in a sentence, can completely change the intended meaning.
Building a dataset that teaches nuance
To train a system that really understands negation, the authors first needed data that highlights these tricky cases. They created the Negation-Sentence-Similarity Dataset, containing 8,575 pairs of sentences from four computer science domains: operating systems, databases, computer networks, and machine learning. For each pair, humans assigned a similarity score that already takes negation into account. The dataset also records how many negation words each sentence uses and what kind of negation pattern it follows, such as a single “not”, an even or odd number of negations, or more complex cases where negation interacts with connecting words like “because” or “but”. This detailed labeling gives the model explicit hints about how negation is shaping meaning.
A hybrid engine that fuses many viewpoints
The heart of the proposed system, called the Negation-Aligned Similarity Scorer, is a two-phase engine. In the first phase, the system passes each sentence through several different language models, each of which captures slightly different aspects of meaning. Their outputs are stitched together and then passed through a bidirectional recurrent network that looks at the sentence as a whole, taking word order and local context into account. This produces a compact summary of each sentence that is better tuned to subtle phrasing, including where negation words sit relative to other words.
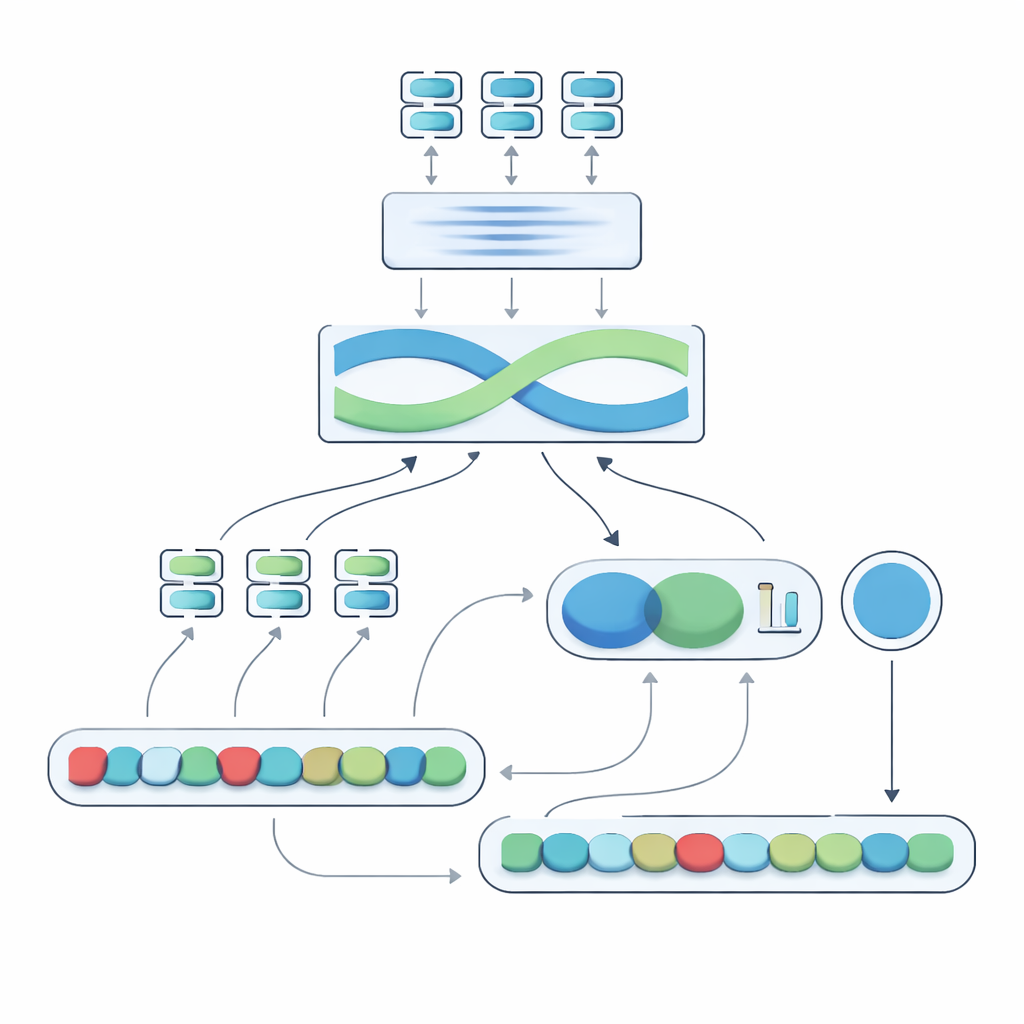
Teaching the model to feel the flip of negation
In the second phase, the system compares the two sentence summaries and adds explicit information about negation. It looks at how much the summaries differ, how much they overlap, and combines those signals with three simple features: the difference in the number of negation words, whether the sentences have odd or even counts of negation (which can reverse or cancel negative meaning), and whether negation appears in roughly corresponding positions. All of these clues are blended in a small prediction network that outputs a similarity score from 0 to 100. Trained end-to-end on the curated dataset, this score becomes sensitive to the way negation reshapes meaning rather than treating “not” as just another word.
How well the new scorer performs in practice
To test their approach, the authors evaluate it both on their custom dataset and on a widely used benchmark of sentence similarity. Compared with strong transformer-based baselines that use standard methods, the new scorer achieves lower prediction error and much higher classification quality, with an F1-score close to 0.97. In carefully chosen examples, it gives low similarity scores when negation clearly reverses meaning and high scores when double negation effectively cancels out, while competing models still tend to overestimate similarity. An ablation study confirms that both key ingredients—the sequence-aware recurrent layer and the explicit negation features—are important for this performance boost.
What this means for students and future tools
For a lay reader, the takeaway is straightforward: the way we say “not” matters, and machines can be taught to notice. By blending multiple language models, contextual processing, and simple counts and positions of negation words, the proposed scorer offers a fairer and more reliable way to judge when two sentences really mean the same thing. This can help automated grading systems avoid serious mistakes, such as treating “is not allowed” as if it were “is allowed”. Although the method is more computationally demanding and still focused on technical domains, it points toward future tools that better capture the fine-grained logic of everyday language, making automated language technologies both smarter and more trustworthy.
Citation: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Keywords: sentence similarity, negation in language, automated grading, natural language processing, deep learning models