Clear Sky Science · en
High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks
Why Faster Internet Roads Matter
Every photo you share, video you stream, or message you send has to pass through a maze of digital crossroads called routers. Each router must quickly decide where to send every data packet next. As global Internet use explodes, these decisions are happening billions of times per second, and even tiny delays can ripple into slower browsing or congested networks. This paper explores a new way to speed up one of the most time‑consuming steps in that decision process by harnessing the massive parallel power of graphics processors, the same chips that drive video games and AI, to keep future networks fast and scalable.
The Hidden Address Book of the Internet
At the heart of every router is a giant address book, called a forwarding table, that maps ranges of IP addresses to the next hop on the journey. When a packet arrives, the router must look up which entry best matches the packet’s destination, using a "longest prefix match" rule: among all partial address matches, it chooses the most specific one. Traditional software methods store these prefixes in tree‑like structures and walk them step by step. This works, but as tables grow to tens or hundreds of thousands of entries, the process becomes slower and more memory‑hungry, especially on ordinary central processors that only handle a limited number of tasks at once.
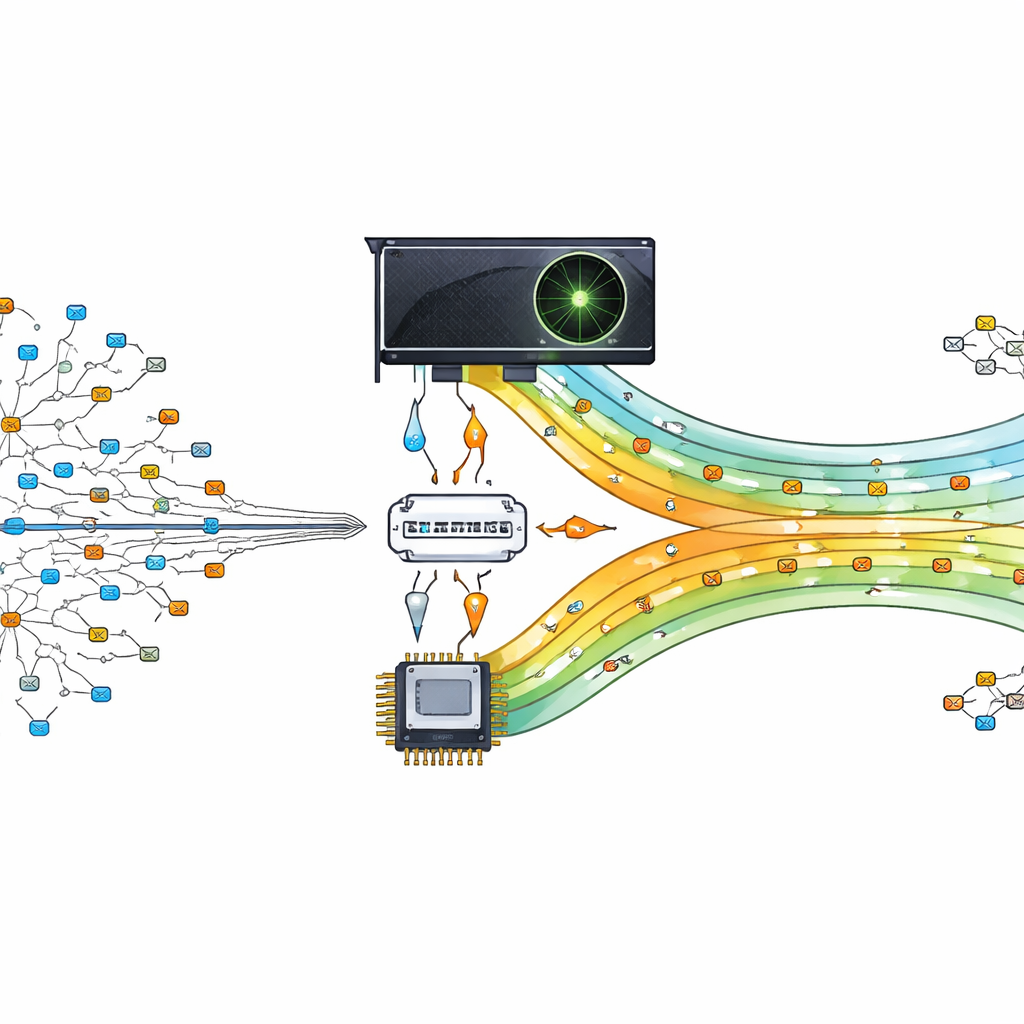
Turning a Graphics Chip into a Traffic Cop
The authors propose offloading this heavy lookup work to a graphics processing unit (GPU), a chip designed to run thousands of tiny tasks in parallel. Their design treats the GPU as a helper to the main processor. The central processor prepares and organizes the routing table, then sends compact versions of the data to the GPU. When packets arrive, their destination addresses are split and shipped to the GPU, where many threads simultaneously search for the best match. By letting hundreds or thousands of lookups happen in parallel, the router can keep pace with modern, data‑driven communication demands.
Shrinking Addresses to Speed Decisions
A key insight of the work is that shorter addresses are faster to search. Instead of using raw IP addresses, the authors compress them using a lossless method called Huffman coding, which assigns shorter codes to the most common address patterns. This reduces the average number of bits needed to represent each entry, cutting both memory use and the height of the underlying search structure. They then store the prefixes in a "multibit" tree that examines several bits at a time, rather than just one, further reducing the number of steps required. To fit the GPU’s strengths, they transform this tree into simple one‑dimensional arrays, replacing complex pointer chasing with regular index calculations that thousands of threads can execute efficiently.
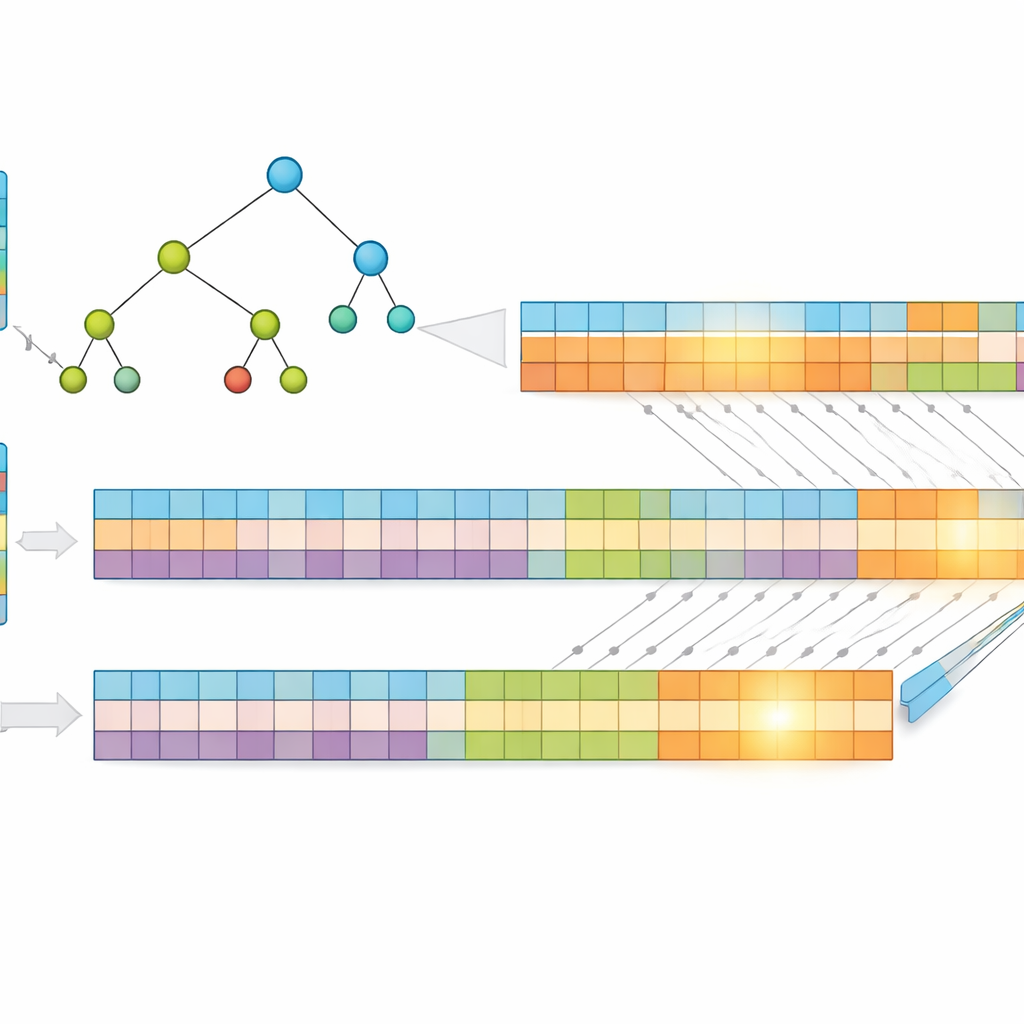
Splitting the Problem for Massive Parallelism
To push performance further, the researchers split each compressed address into two equal halves and build two separate trees—one for the first half, one for the second. When a packet arrives, the GPU searches both trees in parallel. Each search returns a small set of possible matches, and the final answer comes from intersecting these sets to find the shared, most specific prefix. Because the work is divided and processed simultaneously, the time taken depends mainly on the maximum prefix length and the number of bits examined per step, not on how many entries the table contains. Tests using real Internet routing data show that this design maintains a nearly constant lookup time even as the table grows.
What the Experiments Reveal
The team compared their GPU‑based method to a variety of well‑known approaches, including classic binary trees, compressed trees, and other GPU‑accelerated schemes such as hashing and binary search trees. On real routing datasets, their system delivered dramatic gains: around 83–91 percent faster than popular central‑processor‑based tree methods, and 89–97 percent faster than previous GPU methods. Compression also cut memory usage by roughly one‑third on average, easing pressure on limited on‑chip memory and helping keep the GPU’s search structures shallow and efficient. Importantly, the method’s performance stayed stable across different routing table sizes, underscoring its suitability for growing networks.
What This Means for Everyday Users
For a non‑specialist, the bottom line is that the authors show how to turn a graphics chip into a highly efficient traffic officer for Internet data, using clever shrinking and splitting of address information. By combining compression, smarter tree layouts, and massive parallel search, their approach finds the best route for each packet far more quickly than many existing techniques, without being slowed down as the Internet’s address books expand. While the work is demonstrated mainly for today’s address system, the same ideas could be extended to tomorrow’s larger address space, helping keep future online services responsive as our appetite for data continues to grow.
Citation: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Keywords: GPU routing, IP lookup, network scalability, packet forwarding, parallel computing