Clear Sky Science · en
Image prediction algorithm for foggy road scenes based on improved transformer
Why Seeing Through Fog Matters
Driving through thick fog can feel like staring into a white wall. For human drivers and self-driving cars alike, poor visibility turns ordinary roads into dangerous places. This study explores a new way for computers to "see" more clearly through fog by transforming blurry street scenes into sharper, more informative images. The goal is not just prettier pictures, but safer decisions for autonomous vehicles that must detect lanes, cars, and obstacles in all kinds of weather.
From Blurry Roads to Clearer Views
Fog degrades images by scattering light, washing out colors, softening edges, and hiding distant objects. Traditional approaches try to reverse this by relying on hand-crafted rules about how fog behaves, or by enhancing contrast in a broad, one-size-fits-all way. Newer deep learning methods improve on this, but many struggle to capture long-range patterns in a scene, such as how far-off lane markings or vehicles relate to what is close to the camera. They also tend to be heavy and slow, which is a problem for cars that must react in real time.
A Smarter Vision Engine for Foggy Roads
To tackle these limits, the authors design a specialized vision system based on a modern AI architecture known as a Transformer—originally created to understand language, but now adapted to images. Their network takes a single foggy road image and predicts a clearer version along with an estimate of how far ahead the driver can see. It breaks the image into overlapping pieces at several sizes, allowing it to focus both on fine details such as lane edges and traffic signs, and on the broader layout of the road. These pieces are then processed in multiple parallel branches tuned to different fog densities, so that light mist and heavy haze are handled differently rather than being forced through the same pipeline.
Following Structure Instead of Noise
Inside this system, the key innovation is a streamlined attention mechanism that lets the network weigh relationships between distant parts of an image without an explosion in computation. The authors approximate a costly internal calculation so it behaves similarly but runs faster, turning a slow, quadratic step into a much more efficient one. This helps the model concentrate on important structures—like the alignment of lane markings and the outlines of vehicles—while ignoring much of the random fog noise. Additional attention modules then refine which feature channels matter most and which spatial regions deserve focus, further sharpening relevant edges and shapes critical for navigation.
Testing on Real and Synthetic Fog
The researchers assemble three road-scene datasets that mix computer-generated fog with real-world foggy images from cities and highways, covering light, medium, and heavy fog. They train their system to produce both a de-fogged image and a visibility estimate, and then compare it to a strong physics-guided method and several leading dehazing models. Their approach recovers more road details in many cases—especially distant lane markers and vehicle contours—while using far fewer parameters than some popular alternatives. Importantly, it runs fast enough for real-time use on graphics hardware similar to what might be installed in a modern car, maintaining dozens of frames per second even at higher resolutions.
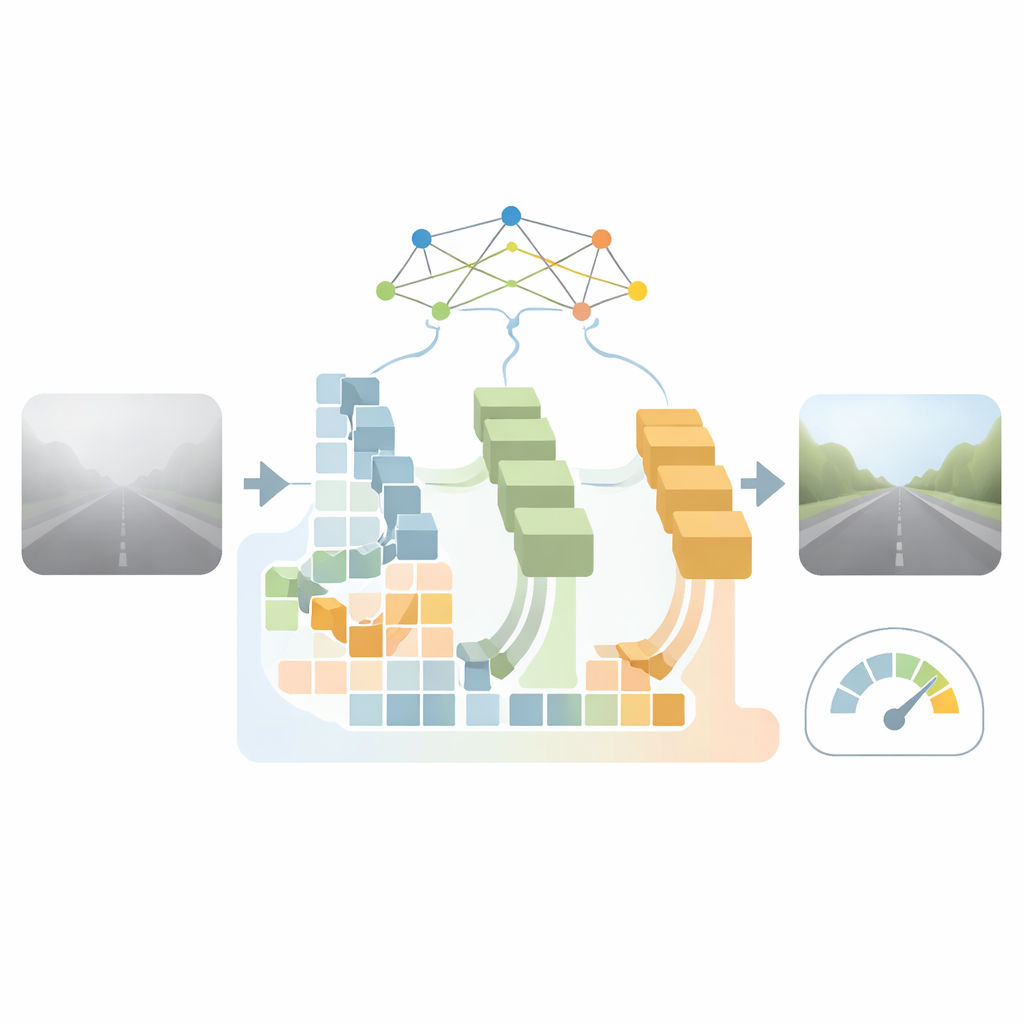
Clearer Pictures for Safer Decisions
In everyday terms, this work offers a lightweight "digital defogger" that helps automated driving systems see more of the road under adverse weather. While not perfect—color shifts and artifacts can still appear in very dense or complex scenes—it strikes a practical balance between image quality and speed. By combining multi-scale views, specialized branches for different fog levels, and an efficient attention mechanism, the method provides clearer, more informative road images without overwhelming onboard computers. This makes it a promising step toward safer autonomous driving in the kind of murky, low-visibility conditions that challenge both humans and machines.
Citation: Zhang, BT., Zhao, AY. & Xiong, P. Image prediction algorithm for foggy road scenes based on improved transformer. Sci Rep 16, 9579 (2026). https://doi.org/10.1038/s41598-025-25974-6
Keywords: foggy road vision, image dehazing, autonomous driving, transformer-based imaging, adverse weather perception