Clear Sky Science · en
A large-scale dataset of choice and response-time data in intertemporal choice
Why waiting versus now matters
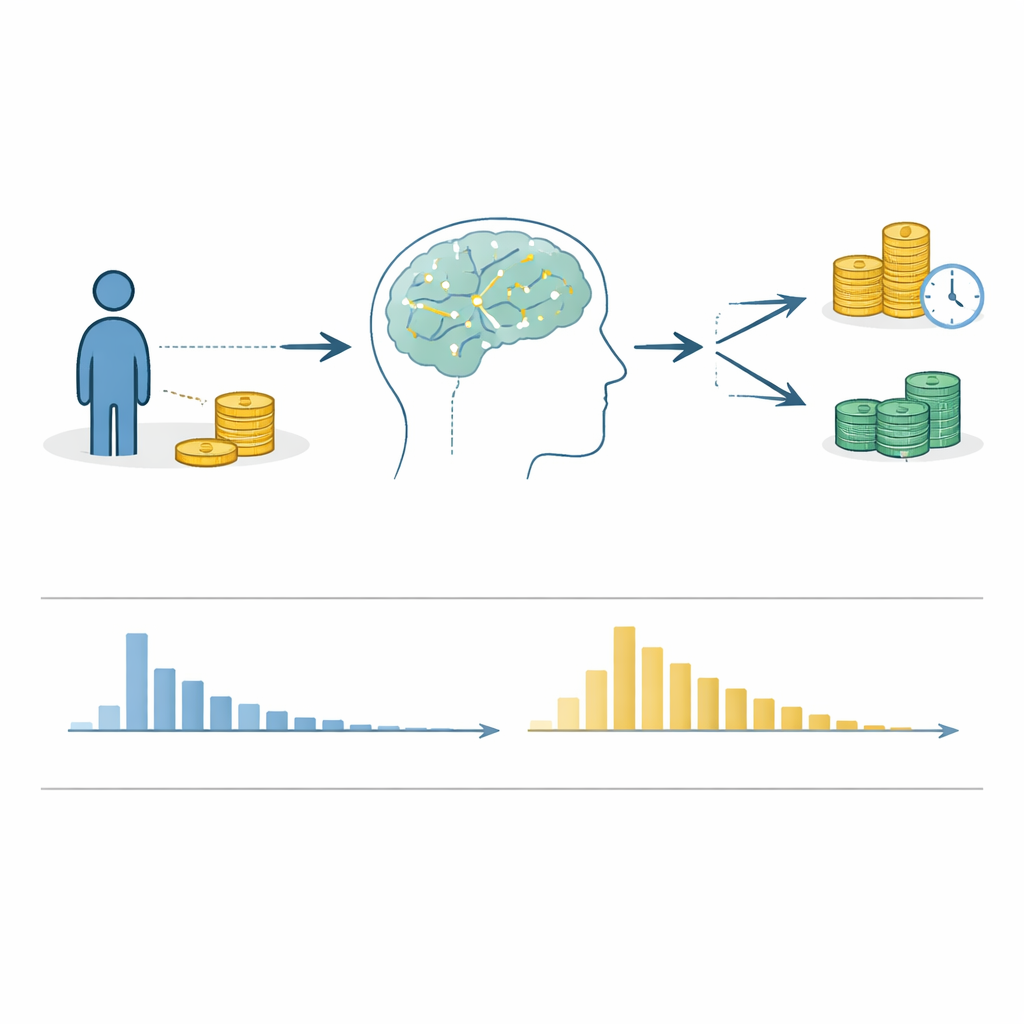
Everyday life is full of choices between a smaller reward now and a larger reward later: spend money today or save for retirement, eat dessert or stick to a diet. How we make these “now versus later” decisions—known as intertemporal choices—shapes our health, finances, and relationships. Yet scientists still debate what is happening in our minds during these decisions. This article introduces a massive new open dataset that brings together detailed records of how nearly twelve thousand people made such choices, including not only what they chose but also how long they took to decide.
Bringing scattered studies under one roof
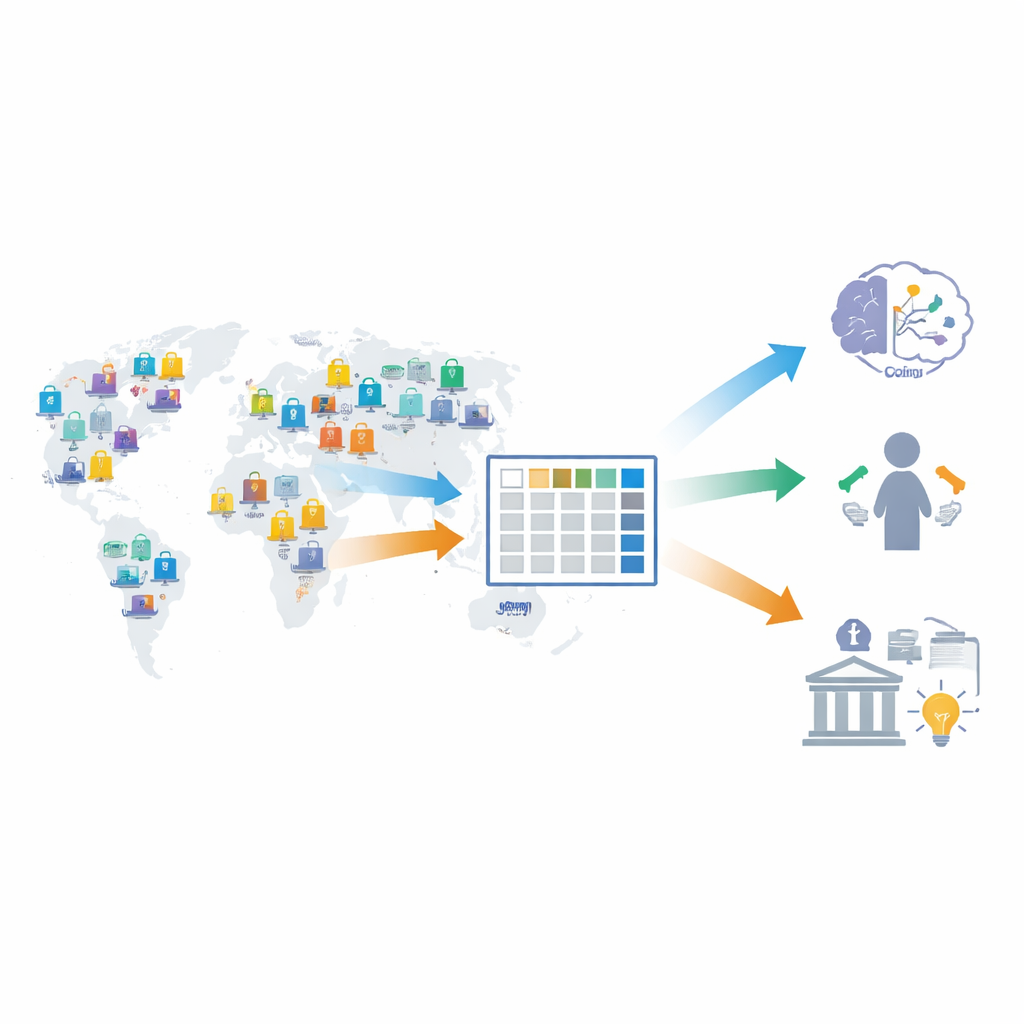
For decades, economists and psychologists have run experiments in which people choose between, for example, a smaller sum of money soon and a larger sum later. Many of these studies focused only on the final choice, ignoring the decision process itself. The authors argue that this misses an important source of insight: response times—how many seconds people take to decide. Response times can reveal how easy or difficult a choice feels and help test theories about how the brain weighs immediate versus future rewards. To move beyond isolated findings, the authors gathered raw trial-by-trial data from 100 separate studies, together covering 11,852 participants and 1,172,644 individual decisions.
Hunting down and unifying the data
The team first performed a large, systematic search of the scientific literature in two major databases to find any published experiment that used a standard computer-based intertemporal choice task with clearly defined money amounts and waiting times. From over four thousand initial hits, they applied strict criteria to exclude studies that did not fit the task, were not peer-reviewed, used non-human subjects, were not in English, or lacked primary data. This winnowing left 1,709 potentially suitable papers. For each of these, the researchers either located existing open data files or contacted authors directly, ultimately sending more than 1,600 formal data requests to obtain the underlying trial-level information.
What the combined dataset looks like
From this effort, the authors obtained 112 datasets from 98 publications and, after final permissions and quality checks, released 100 datasets from 87 papers. Each line of the combined file corresponds to a single choice trial and includes what was offered (a smaller-sooner and larger-later amount), which option was chosen, and how long the person took to respond. Additional fields describe the participant (such as age and country), how the task was run (online versus in-lab, whether choices were paid out for real, whether there was time pressure), and how data should be filtered (for example, trials with missing values). All data are provided in common formats and share the same variable structure, making it easy for other researchers to analyze them with different software tools.
Checking the data behind the scenes
Because the dataset combines many independent studies, the authors carried out extensive technical checks to ensure that the numbers make sense. They compared the reported sample sizes and trial counts in each paper with what actually appears in the files, documented any mismatches, and inspected patterns of missing responses. They verified that the smaller-sooner option really was smaller and sooner than the larger-later one and followed up with original authors when something looked off. They also tested whether people’s choices behaved sensibly—for instance, whether larger rewards and shorter waits generally increased the chance that an option was picked. For response times, they screened for impossible values, such as negative times or decisions that were improbably fast or slow, and examined whether most participants showed the typical pattern of many quick responses and fewer slow ones.
A living resource for future insights
The authors have released a static snapshot of this large-scale dataset, tied to the article, as well as a living online database that will continue to grow as more researchers contribute their data. Alongside the master combined file, all individual datasets are also available as separate downloads where permissions allow. Although the original raw processing scripts are not shared in all cases, the resulting data are documented and licensed for broad reuse in non-commercial work. This resource opens the door for scientists to test new models of how people juggle present and future rewards, to probe why results sometimes differ across settings and groups, and to design more reliable theories of decision making. For the lay reader, the key takeaway is that researchers now have a powerful, shared foundation for understanding why waiting for a better tomorrow can be so hard—and how that difficulty varies from person to person and situation to situation.
Citation: Pongratz, H., Schoemann, M. A large-scale dataset of choice and response-time data in intertemporal choice. Sci Data 13, 323 (2026). https://doi.org/10.1038/s41597-026-06947-4
Keywords: intertemporal choice, delay discounting, response times, decision making, open dataset