Clear Sky Science · en
PreprintToPaper dataset: connecting bioRxiv preprints with journal publications
Why early research matters to all of us
Long before a scientific discovery appears in a glossy journal, it often shows up as a “preprint” – an early, freely shared version of the work. During the COVID‑19 pandemic, these preprints shaped news headlines, public debates, and even health policies. Yet it has been surprisingly hard to track which early studies later became formal journal articles, and which never did. This paper presents the PreprintToPaper dataset, a large, carefully checked map that links life‑science preprints on the bioRxiv server to their eventual journal publications, giving the public, journalists, and researchers a clearer view of how early findings travel through the scientific system.
Following the journey from draft to paper
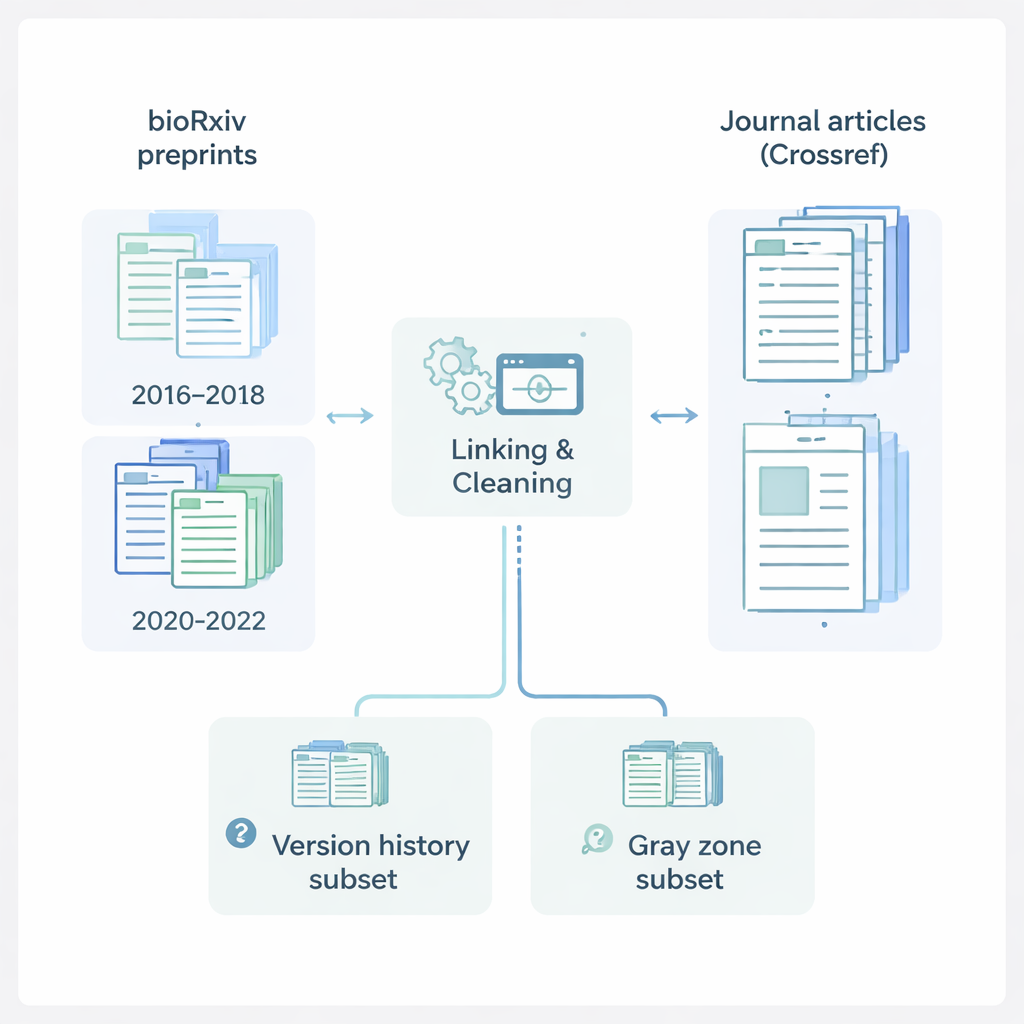
The authors focused on bioRxiv, a major online server where life‑science researchers post preprints. They collected information on 145,517 preprints from two key time windows: 2016–2018, before the COVID‑19 pandemic, and 2020–2022, during the pandemic’s intense publishing rush. For each preprint, they recorded details such as the title, abstract, authors, institutions, subject area, license, and submission dates. They then drew on Crossref, a central registry of journal articles, to fetch matching information about published papers: journal names, publication dates, and complete author lists. By combining these sources, they constructed a rich, unified record that follows a study from its first public appearance as a preprint to its final form in a scientific journal.
Sorting preprints into clear groups
To make sense of this large collection, the team sorted each preprint into one of three groups. “Published” preprints had a clear digital link from bioRxiv to a journal article. “Preprint Only” items were posted on the server but showed no sign of having been published elsewhere. The most intriguing group, called the “Gray Zone,” contains cases that look like they may have been published in a journal but lack an official link on bioRxiv. To capture how preprints change over time, the researchers also built a separate version‑history file listing every available version for preprints that had an original version and at least one later update. This allows others to study how titles, author lists, and other details evolve between the first draft and the last preprint version.
Detecting hidden matches and checking them by hand
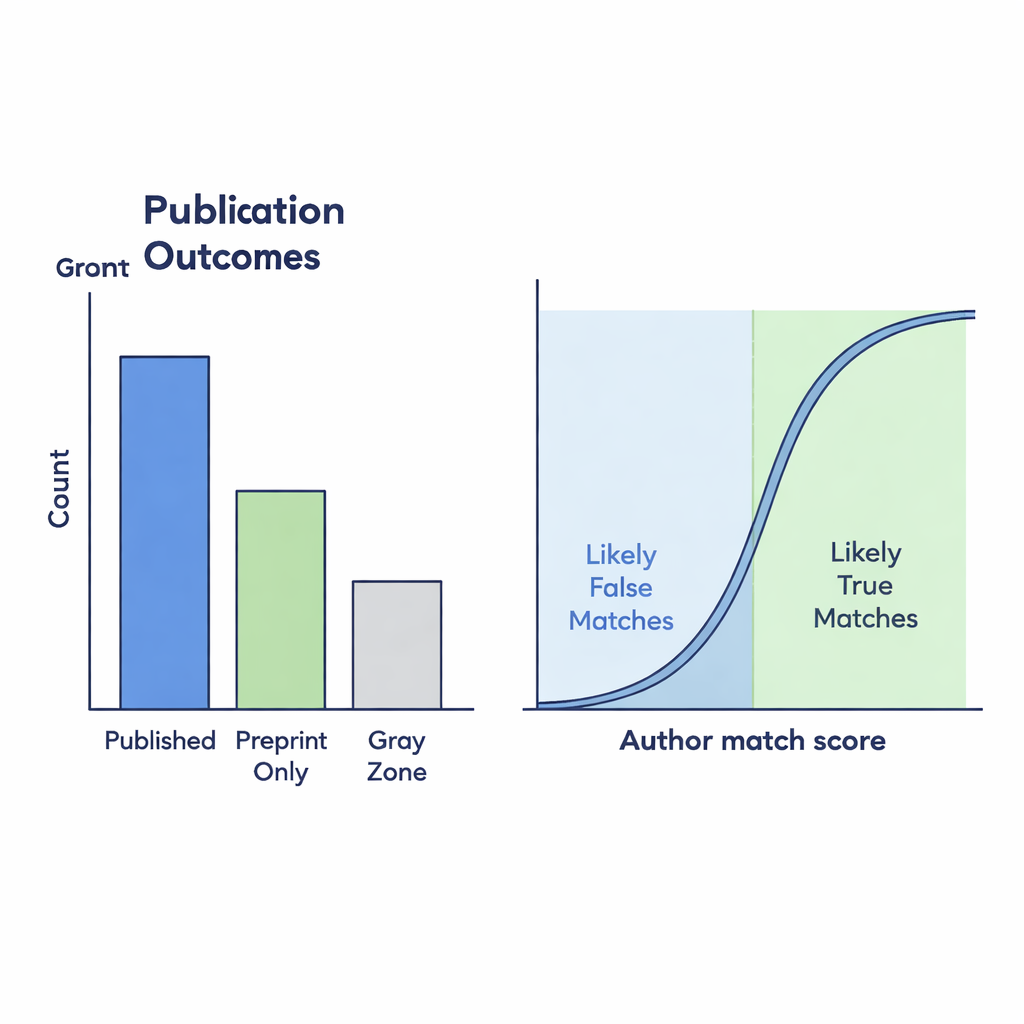
Many preprints that are in fact published never receive a proper link back on bioRxiv, creating blind spots for anyone trying to track scientific output. To uncover these missing connections, the authors compared preprint titles and author lists with Crossref’s journal records. They used a similarity score between 0 and 1 to measure how closely two titles match; potential Gray Zone links needed a score of at least 0.75. They then refined these candidates with author‑based measures: how different the author counts were and how similar the names appeared. To test whether these automated rules were trustworthy, two human annotators manually examined 299 borderline cases. Their judgments agreed strongly, and a statistical model showed that when author lists matched well, a supposed link was very likely to be genuine.
What the numbers reveal about scientific output
The finished dataset shows how preprinting and publishing patterns shifted before and during the pandemic. Overall, it contains over 90,000 clearly published preprints, more than 35,000 that appear to remain only on the server, and about 19,000 Gray Zone cases where the link to a journal article needed detective work. When only the officially linked “Published” group is counted, it seems that a much smaller share of preprints are turning into journal papers over time. But when likely Gray Zone matches—those with strong author similarity—are included, the drop in publication rates is far less dramatic. This suggests that missing links in the underlying infrastructure can mislead us about how the scientific landscape is changing.
Why this resource is useful beyond specialists
For non‑specialists, the main message is that early scientific results do not just vanish into a black box. With the PreprintToPaper dataset, it becomes possible to see which rapid‑fire findings eventually survive peer review, how long that journey takes, and what kinds of studies never leave the preprint stage. Policymakers can use this information to judge how well open‑science practices are working; journalists can better gauge how solid a given result is; and researchers can build tools that sift and summarize an overwhelming flow of papers. In short, this dataset turns a chaotic flood of early research into a more traceable, accountable record of how ideas move from first posting to polished publication.
Citation: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Keywords: preprints, scientific publishing, open science, COVID-19 research, bibliometrics