Clear Sky Science · en
Multi-TPC: A Multimodal Dataset for Three-Party Conversations with Speech, Motion, and Gaze
Why how we move and look while talking matters
When people talk face-to-face, they do much more than trade words. We lean forward, nod, glance at each other, and pause in just the right places. These subtle moves become even more important when three people are talking together, as attention and speaking turns constantly shift. Yet until now, scientists and engineers have had very little high-quality data showing how speech, body motion, and eye gaze work together in small-group conversations. This paper introduces a new dataset designed to fill that gap and help build more natural virtual assistants, social robots, and tools for studying everyday human interaction.
A new window into three-person conversations
The authors present Multi-TPC, a publicly available collection of three-person conversations recorded in a laboratory using motion capture, eye trackers, and individual microphones. Unlike many earlier resources that focus on a single speaker or on conversations between just two people, Multi-TPC captures spontaneous discussions among three strangers who stand in a triangle and talk about any topic they like. Over 5.3 hours of recordings from 21 young adult participants are included, separated into 24 sessions. For every moment in these conversations, the dataset provides detailed information about how each person speaks, moves their body, and where they direct their gaze.
How the conversations were captured
To build this dataset, the team created a hybrid recording setup. Each participant wore a full-body motion capture suit dotted with reflective markers so an array of eight cameras could track their posture, head movement, and gestures in three dimensions. Lightweight eye-tracking glasses, similar in feel to normal eyewear, measured where each person was looking in their visual field. Wireless microphones clipped near the neck recorded each speaker’s voice on a separate audio track. Before recording, participants were calibrated in the system and instructed to remain at fixed spots forming an equilateral triangle about one meter apart. A clapboard, visible to the cameras, the eye trackers, and the microphones, provided a precise cue to align all devices in time, ensuring that motion, gaze, and speech could be matched frame by frame.
Cleaning, organizing, and enriching the data
Collecting raw signals was only the first step. The researchers carefully processed the motion data, labeling all markers and filling small gaps using mathematical interpolation while cross-checking nearby marker positions. Audio recordings were cleaned with noise reduction methods and then fed into speech-recognition software to produce word-by-word transcripts, which were later manually corrected. Gaze points measured in camera pixels were converted into 3D angles showing where each person was looking in space. All signals were down-sampled to 60 frames per second and synchronized, then stored in simple, open formats. The final dataset is organized by modality—motion, gaze, audio, words, and prosodic features such as loudness and pitch—with clear file naming rules so that researchers can easily trace any instant in time across all three participants.
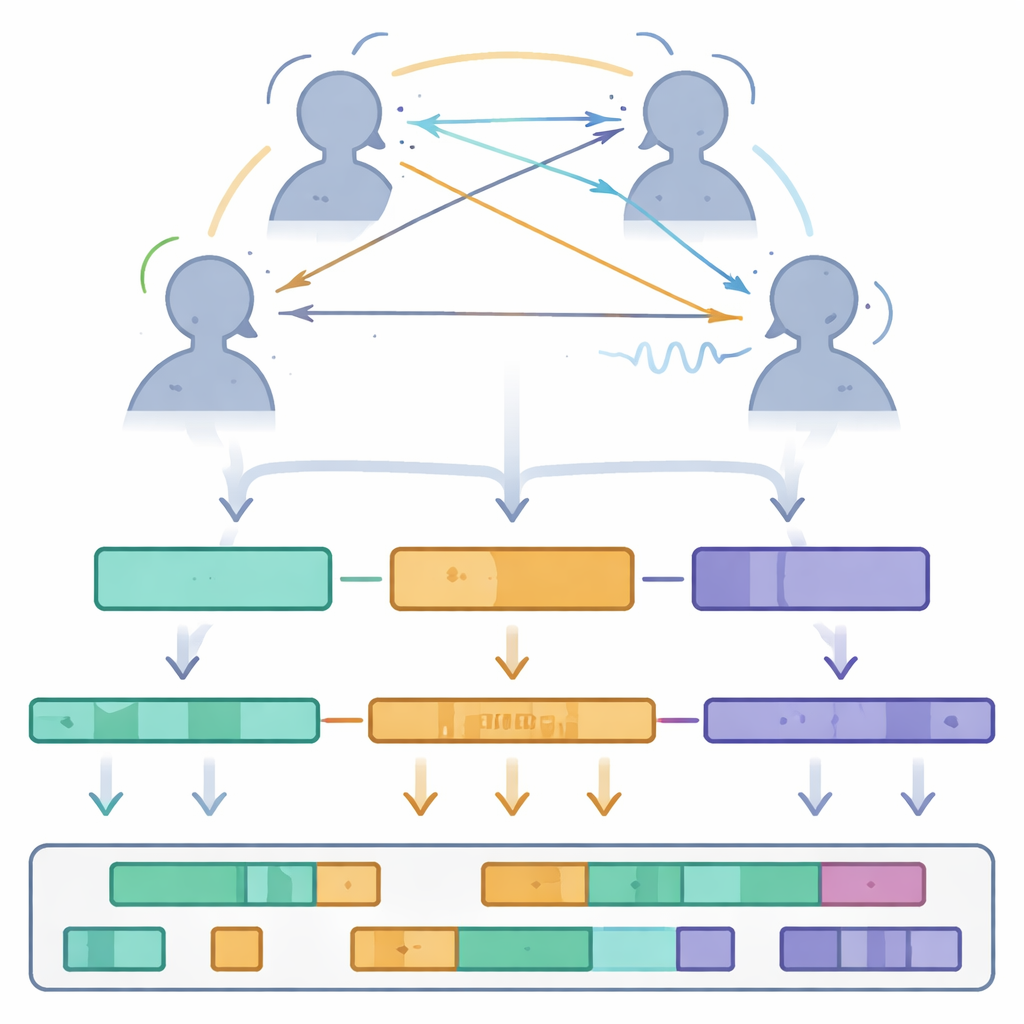
What the dataset reveals about group talk
Using Multi-TPC, the authors performed an initial statistical tour of how three-person conversations unfold. They measured speaking turns and silences, finding that a typical speaking turn lasts about 2.7 seconds, separated by pauses of just over one second. They also examined head nods and shakes as a form of listener feedback, detecting roughly a quarter of a nod or shake per second on average—evidence that listeners are constantly signaling attention and attitude without saying a word. Gaze analysis showed that people rarely fixate directly on another’s face for long. Instead, they often look slightly away, and their gaze patterns shift depending on who is speaking, whether there is a pause, or whether more than one person talks at once. During overlapping speech, participants’ gaze becomes more evenly spread or drifts away from both partners, hinting at uncertainty about who holds the conversational floor.
Why this resource matters for future technology
By packaging all these layers of information into a well-documented, shareable dataset, Multi-TPC offers a new foundation for studying how small groups manage turn-taking, attention, and feedback through both words and movement. For everyday readers, the takeaway is that the dance of conversation—who speaks when, who looks where, and how subtle nods shape the flow—is now captured in fine detail. For scientists and developers, this opens the door to building virtual characters and social robots that respond more like real people in group settings, as well as to deeper studies of how we coordinate with each other through voice, body, and gaze.
Citation: Lee, MC., Deng, Z. Multi-TPC: A Multimodal Dataset for Three-Party Conversations with Speech, Motion, and Gaze. Sci Data 13, 429 (2026). https://doi.org/10.1038/s41597-026-06819-x
Keywords: multimodal conversation, gesture and gaze, social interaction dataset, turn-taking, virtual agents