Clear Sky Science · en
A Chinese Traditional Opera Video Super-Resolution Dataset Based on the “Real-world+” Degradation Fusion
Bringing Old Opera Films Back to Life
Many recordings of Chinese traditional opera exist only in fragile, low-quality video form. Time, dust, and repeated copying have blurred faces, dulled costumes, and filled scenes with visual noise. This paper introduces a new way to digitally "clean" and sharpen such videos, not by fixing each film by hand, but by building a specialized training collection for artificial intelligence. The goal is to help computers learn how to turn blurry, aged footage into clearer, more vivid images, preserving an important part of the world’s cultural memory.
Why Old Opera Videos Look So Bad
Chinese traditional opera, including famous styles such as Peking Opera and Kunqu, has been recognized by UNESCO as part of humanity’s shared cultural heritage. Yet many of the surviving videos of these performances have been through a long and harsh journey. First, the original filming equipment adds blur and camera noise. Then, storage on film, tape, or disks introduces scratches, warping, and data loss. Finally, repeated copying, compression for the internet, and unstable network transmission add blocky artifacts, flicker, and frame drops. The result is not just a simple blur, but a tangled mix of many different kinds of damage, making it very hard for restoration methods to guess what the original scene should look like.
Building Pairs of Blurry and Clear Frames
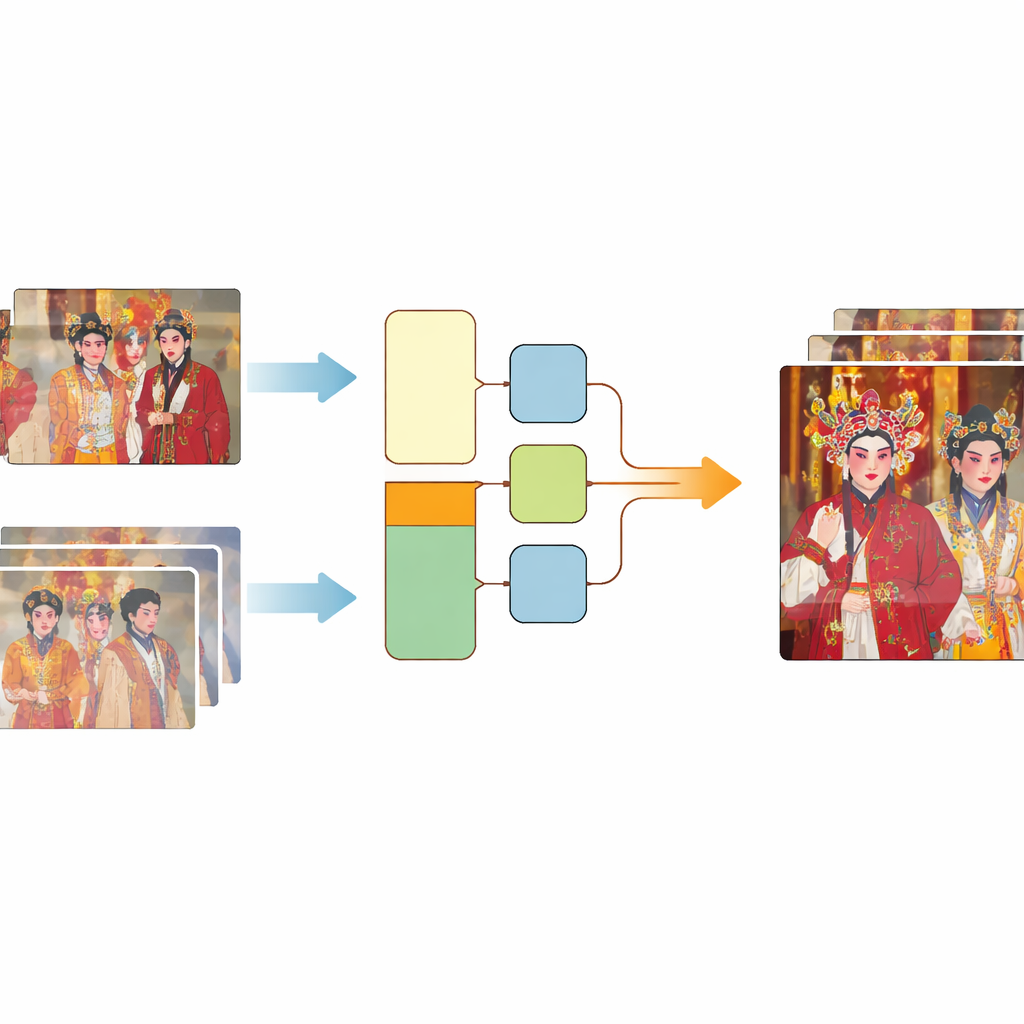
Modern video “super-resolution” methods train computers to predict a sharp, detailed frame from a low-quality one. To learn this skill, they need many examples where a blurry frame is perfectly matched to the exact same scene in high quality. Existing training collections usually rely either on simplified, artificial damage or on real footage that is not precisely aligned between low- and high-quality versions. The authors created a new resource called CTOVSR by starting from four traditional opera films that had been professionally restored from original reels, reaching very high resolution. They then found matching, standard-definition versions of the same performances released online. These lower-quality copies had gone through the full real-world aging process, making them ideal “before” images.
Aligning Every Frame with Care
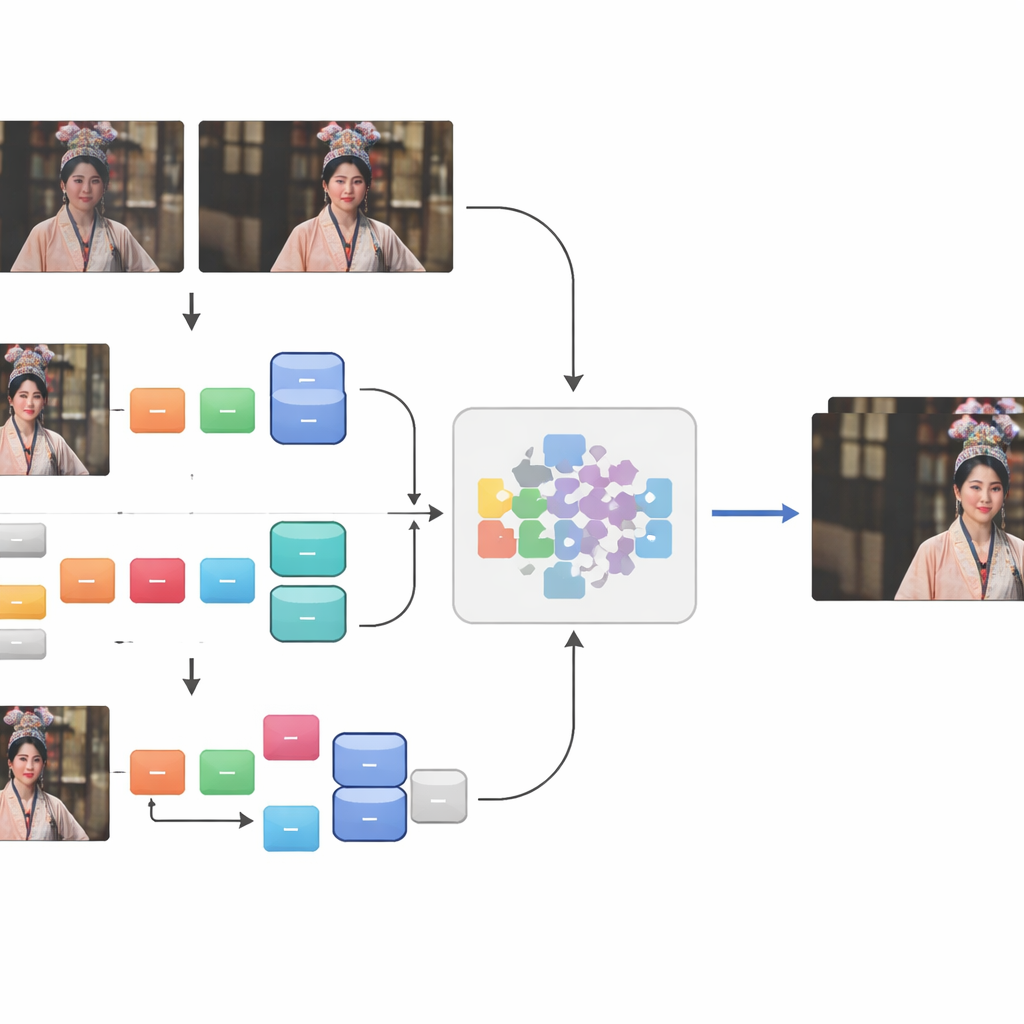
Matching the restored and the aged videos was far from straightforward. Differences in frame rate, missing shots, added watermarks, black borders, and shifting aspect ratios meant that simple automatic methods did not work. The team extracted usable segments and then carried out a careful, three-step alignment. First, they used a custom tool, eye_comparer, to manually fix timing problems such as frame loss, out-of-order frames, and “ghost” frames at scene transitions. Next, they handled spatial mismatches by overlaying frames in image-editing software, precisely aligning the content and cropping away borders, logos, and subtitles while preserving as much of the scene as possible. Finally, they ran an automatic check using a similarity measure, keeping only frame pairs that were nearly identical in structure. This process produced 250 high-quality real-world sequence pairs covering hundreds of thousands of frames.
Blending Real Damage with Simulated Wear
Although these carefully aligned pairs captured true, real-world decay, they were still too few to cover the full variety of ways video can break down. To broaden the training material, the authors added a second ingredient: synthetic damage applied to 41 additional high-definition opera videos. They simulated spatial damage—such as blur and noise—through a two-stage chain of degradation steps, and temporal damage by compressing the videos with a widely used older standard that reflects how many online clips were historically encoded. By fusing this synthetic portion with the “Real-world+” pairs, they assembled the CTOVSR dataset, which contains 900 strictly aligned low–high quality video pairs, each lasting 100 frames and showcasing a wide range of operas, scenes, and lighting conditions.
Proving the Value of the New Collection
To test whether CTOVSR truly helps computers restore old videos, the authors trained several state-of-the-art super-resolution models using only this dataset. They compared the outputs to simple resizing methods and found that the trained models produced much clearer images, with sharper costume details, more legible facial makeup, and fewer visible artifacts. An ablation study showed that combining real and synthetic damage was markedly better than using either alone. The researchers also tried their trained models on completely new footage: aged opera clips found online and even performance videos from other cultures, such as Italian opera and Indian classical dance. Human viewers rated the enhanced frames significantly higher than the originals or basic upscaled versions, suggesting that models trained on CTOVSR can generalize beyond the specific material it contains.
Saving Heritage Through Smarter Data
In simple terms, this work does not introduce yet another restoration algorithm; instead, it offers the carefully prepared “practice material” those algorithms need to learn. By painstakingly pairing damaged and high-quality versions of traditional opera footage and then enriching them with realistic simulated wear, the CTOVSR dataset gives artificial intelligence a far better feel for how old videos decay and how they should look when restored. This approach provides a practical path not only for breathing new visual life into Chinese traditional opera, but also for protecting many other forms of irreplaceable historical video from fading into digital oblivion.
Citation: Xi, W., Qin, B., Zhang, Y. et al. A Chinese Traditional Opera Video Super-Resolution Dataset Based on the “Real-world+” Degradation Fusion. Sci Data 13, 387 (2026). https://doi.org/10.1038/s41597-026-06776-5
Keywords: video super-resolution, digital heritage preservation, Chinese traditional opera, image restoration, degraded video datasets