Clear Sky Science · en
A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis
Why Blood Cell Pictures Matter
Every routine blood test hides a microscopic world of cells that can reveal infections, anemia, or even blood cancers long before symptoms become obvious. Doctors traditionally inspect these cells by eye under a microscope, a careful but time-consuming craft. This study introduces a very large, carefully labeled collection of blood cell images designed to teach computers to recognize these cells automatically. The goal is to make future blood tests faster, more consistent, and more widely accessible by giving artificial intelligence the visual experience it needs to help doctors read blood smears accurately.
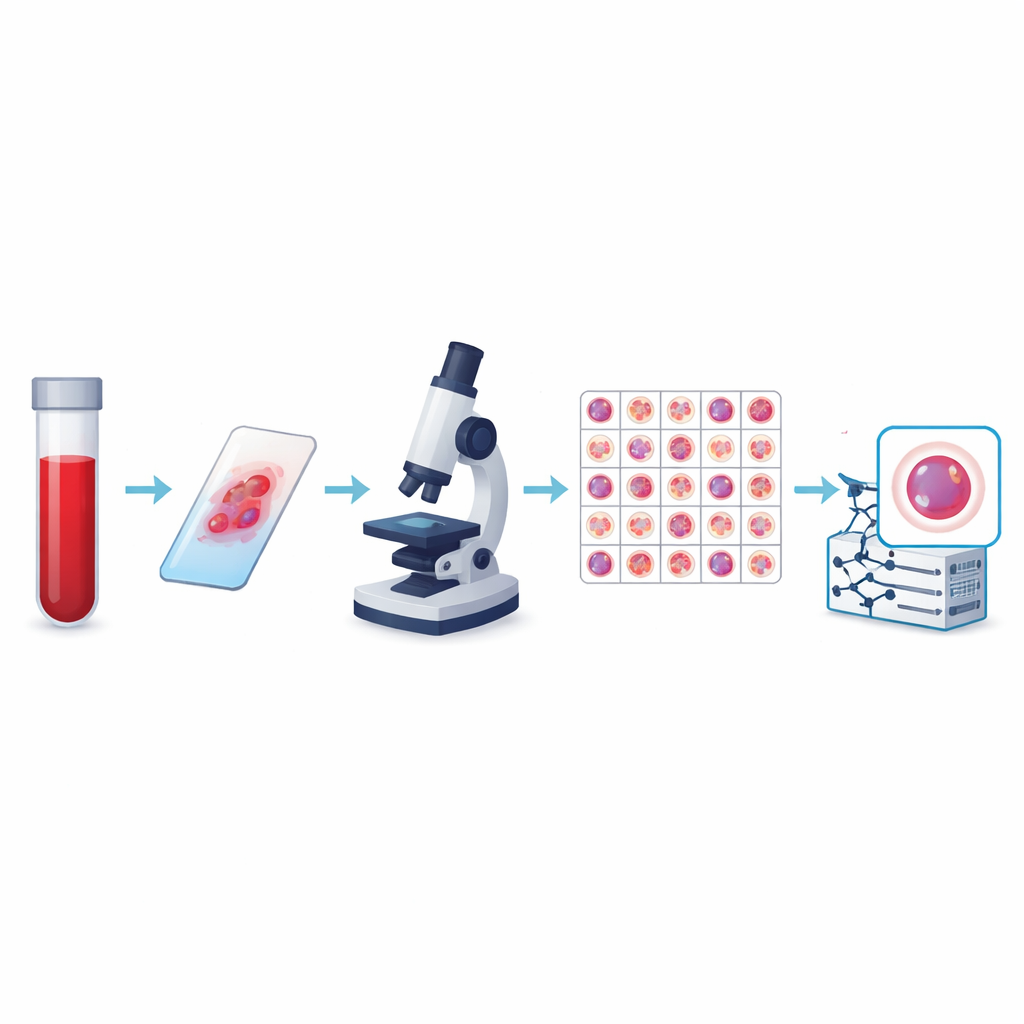
From Simple Counts to Smart Imaging
White blood cells are key defenders in our immune system, and their mix and appearance provide crucial clues about our health. A rise in some cell types can signal infection or allergy, while the sudden presence of immature “blast” cells can warn of leukemia. Labs already use automated machines to count cells, but subtle shape changes still often require an expert’s eye. Human reviewers can disagree, and examining slides one by one takes time. As medicine leans more on digital imaging and artificial intelligence, there is a growing need for large, trustworthy image collections that can train computers to spot these telltale cell patterns as reliably as a seasoned hematologist.
Building a Huge Library of Blood Cells
The authors created what is currently the largest public collection of peripheral blood cell images, called the KU-Optofil PBC dataset. It contains 31,489 high-resolution pictures of individual cells spread across 13 groups, including common defenders like lymphocytes and segmented neutrophils, as well as rarer but medically critical types such as blasts, myelocytes, and reactive lymphocytes. All images come from stained blood smears prepared under standardized conditions at a single hospital using the same imaging system. This consistency means that computers learning from the data see a stable, well-controlled view of each cell type instead of a patchwork of incompatible pictures.
Expert Eyes and Careful Curation
To make the dataset trustworthy, each image was labeled independently by two experienced laboratory technicians, with a third expert resolving any disagreements. Statistical checks showed very strong agreement between reviewers for every major cell type, including perfect agreement for some. The team also applied strict rules to decide which images to keep, discarding blurry, overlapping, or poorly stained cells. The final images are all the same size and color format, and they are organized into training, validation, and test folders so that other researchers can fairly compare algorithms. Additional files link each image to an anonymous patient, allowing studies that test whether a model truly generalizes from one person to another.
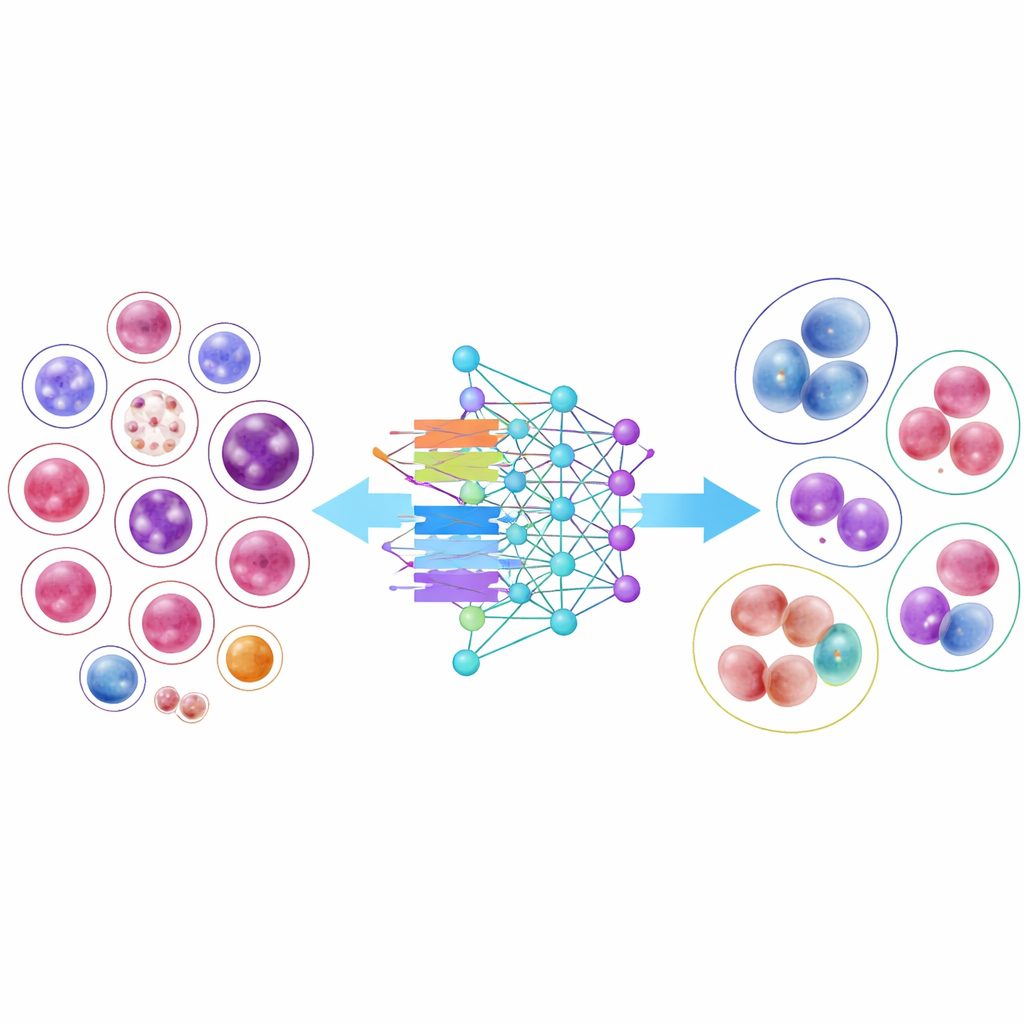
Putting AI Models to the Test
To demonstrate how useful this library can be, the researchers trained 14 modern image-recognition models, from classic convolutional neural networks to newer transformer-based designs. Several compact, efficient models performed surprisingly well, and one architecture, DenseNet-121, correctly classified cells more than 95 percent of the time on average. However, the results also highlighted an important real-world difficulty: common cell types with thousands of examples were recognized almost perfectly, while very rare cells with only a few dozen images remained much harder to classify. Even when the researchers adjusted the training to “pay more attention” to these scarce classes, overall accuracy dropped, and the gains for rare types were modest, underscoring the challenge of learning from limited examples.
What This Means for Future Blood Tests
For non-specialists, the key message is that this work provides the raw visual experience that computer systems need to become trustworthy partners in reading blood smears. By assembling a large, diverse, and carefully checked library of blood cell images and showing that many different AI models can learn from it, the authors lay the groundwork for tools that could speed diagnosis, reduce human error, and extend expert-level analysis to clinics with fewer specialists. At the same time, the mixed results on rare cell types remind us that even big datasets have blind spots, and that improving care for patients with unusual or early-stage diseases will require expanding and refining these image collections further.
Citation: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Keywords: blood cell imaging, medical AI, hematology, deep learning, medical datasets