Clear Sky Science · en
A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis
Why this research matters
Oral cancer can hide in plain sight, starting as a small sore in the mouth and turning into a life‑threatening disease. Doctors rely on microscope images of tissue to decide how severe a tumor is and how likely it is to return or spread, but reading these images is slow, demanding work. This study introduces a rich new image collection designed to help artificial intelligence (AI) systems read these slides alongside pathologists, with the long‑term goal of giving patients faster, more accurate answers about their disease and treatment options.
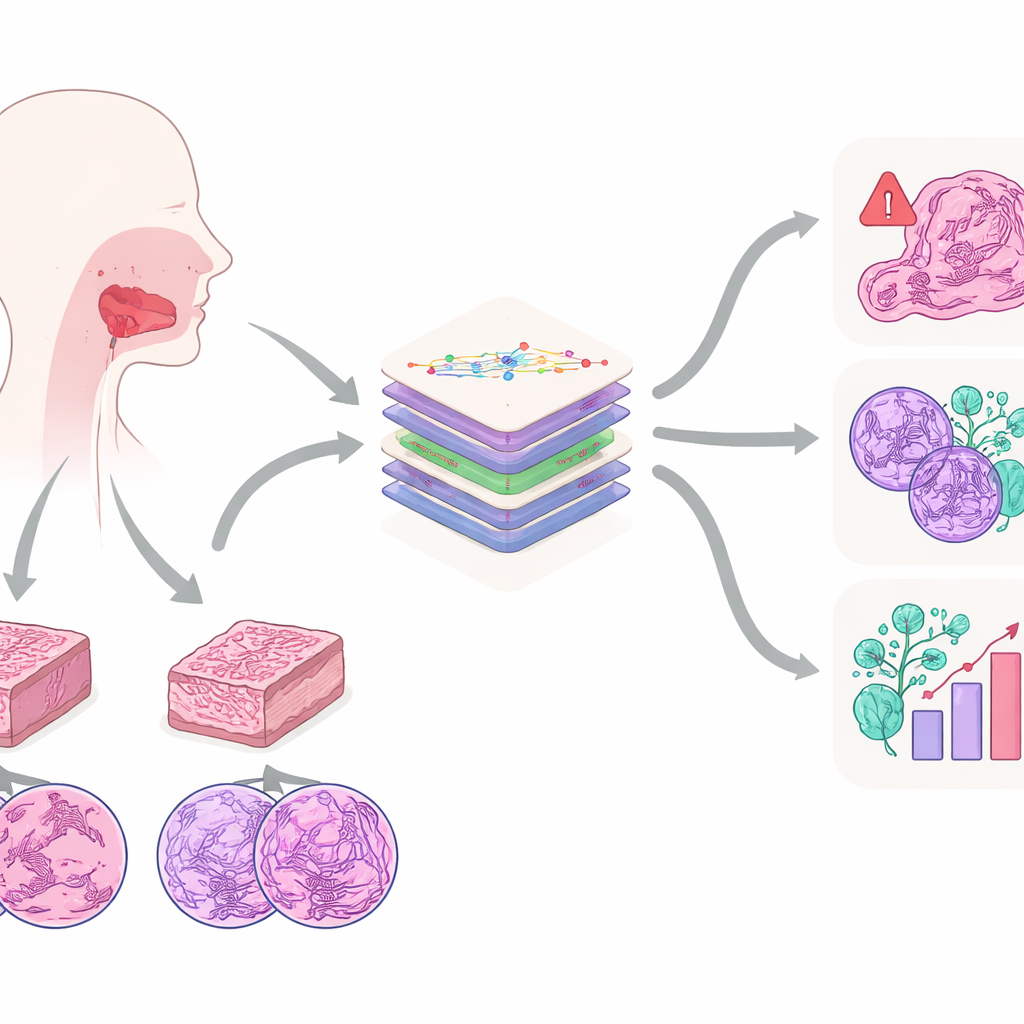
A closer look at a common mouth cancer
The work focuses on oral squamous cell carcinoma, one of the most frequent and aggressive cancers of the mouth. It often arises in people with histories of tobacco or alcohol use and can spread into nearby tissues and lymph nodes in the neck. Today, the gold standard for diagnosis is still the pathologist’s eye on stained tissue slices under a microscope. From these slices, experts judge how abnormal the cells look, how deeply the tumor has grown, whether it has invaded nerves or blood vessels, and many other features that influence survival. The authors argue that these microscopic patterns contain far more information than any human can easily track, making them an ideal target for modern AI.
Building a richer picture from tissue images
To unlock this information, the team created the Multi‑OSCC dataset: microscope images from 1,325 patients treated for oral cancer at a single hospital between 2015 and 2022. For each patient, pathologists prepared two tissue blocks—one from the center of the tumor and one from its invasive edge—then captured high‑resolution images at three zoom levels, similar to looking at a city from an airplane, a rooftop, and a street corner. This produced six carefully chosen images per patient, each containing key structures such as cancer cell nests, whorls of keratin, and highly abnormal cell nuclei. Alongside the images, the researchers collected detailed medical records and long‑term follow‑up to see which tumors came back or spread.
Six questions doctors really care about
What sets Multi‑OSCC apart is that it mirrors real clinical questions instead of focusing on a single label. Each patient in the dataset is annotated for six important outcomes. One is whether the tumor recurred within two years after surgery, a critical window when most relapses occur. Another is whether cancer cells had already reached neck lymph nodes, which guides decisions about extensive neck surgery. Four additional labels capture how well‑differentiated the tumor cells are, how deeply the tumor invades, and whether it has entered blood vessels or grown along nerves—subtle but powerful clues to how dangerous the cancer is. This design allows AI models to learn not just “cancer versus normal,” but a fuller portrait of risk and severity.
Teaching AI to read complex slides
The researchers then benchmarked how different AI strategies handle this demanding dataset. They compared several modern image‑recognition backbones, including both classic convolutional networks and newer transformer‑based models, and found that transformers pre‑trained specifically on pathology images performed best overall. They tested ways of combining information from the six images per patient and discovered that a simple strategy—extracting features from each image and then concatenating them—outperformed more elaborate fusion schemes. They also examined how color standardization of the stains affected performance, revealing that keeping original color was vital for predicting recurrence, while gentle color normalization helped for the other diagnostic tasks.
Limits, surprises, and what comes next
One surprise was that training a single AI model to handle all six questions at once did not yet beat models trained separately for each task. Another was that detailed microscope patches, while rich in cellular detail, still lack the broad architectural view that full‑slide images provide. Even so, models trained on Multi‑OSCC’s images clearly outperformed models that used only clinical data such as age, habits, and medical history, especially for predicting tumor recurrence. The authors position Multi‑OSCC as a starting point: a public, well‑documented dataset that others can use to develop and compare methods. For patients, the long‑term promise is that future tools built on this resource could help doctors more reliably spot which oral cancers are likely to return or spread, leading to more tailored treatments and, ultimately, better odds of survival.
Citation: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Keywords: oral cancer, histopathology images, artificial intelligence, deep learning, medical imaging datasets