Clear Sky Science · en
StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis
Why this matters for everyday data users
As artificial intelligence tools like chat-based assistants become part of everyday work, more people are asking them to crunch numbers, run experiments, and analyze data. But when an AI writes the code for a statistical study—say, checking if a new medical treatment works or exploring school performance data—how do we know it did the job correctly? This paper introduces StatLLM, a public dataset designed to test how well large language models handle real statistical analysis tasks, giving researchers and practitioners a clearer picture of when to trust AI-written code—and when to be cautious.
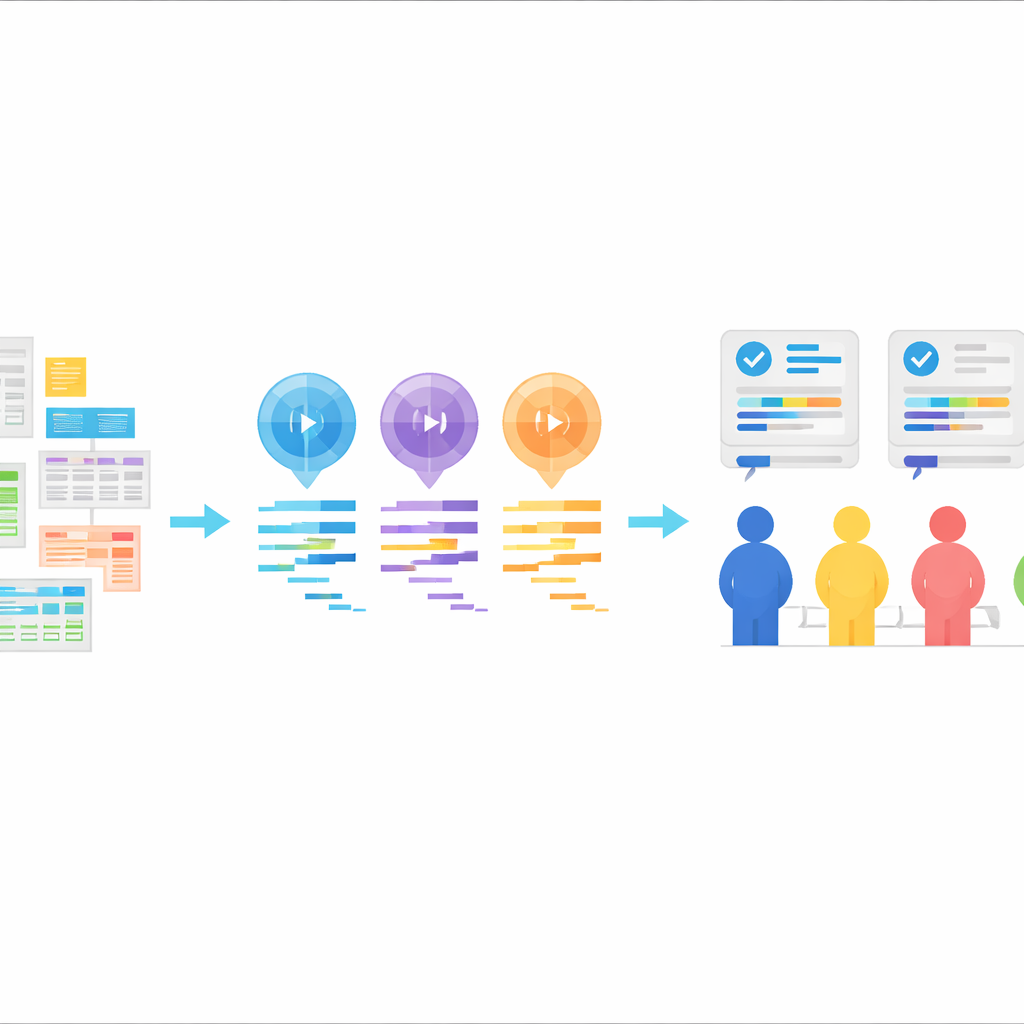
A new testbed for AI-written statistics code
The heart of StatLLM is a carefully assembled collection of 207 statistical analysis tasks built from 65 real datasets drawn from fields such as education, medicine, business, finance, engineering, and sports. Each task comes with a plain-language problem description, a detailed explanation of the dataset and its variables, and a short piece of SAS code written and checked by human experts. The tasks span what a strong undergraduate or master’s student in statistics might learn: from simple data summaries and graphs to regression, survival analysis, and more advanced methods. This gives a realistic, classroom-and-industry-style test of whether AI tools can understand practical questions and translate them into sound analysis steps.
Letting AI write the code, then grading its work
Using these tasks, the authors asked three large language models—GPT-3.5, GPT-4, and Llama‑3.1 70B—to generate SAS code. Each model received the same ingredients: a description of the task, a description of the dataset, the actual data file, and an explicit instruction to produce SAS code. The models were used in a “zero-shot” way, meaning they were not shown examples of correct SAS code beforehand. Their responses were cleaned so that only the code remained, without explanations. This setup mimics a common real-world pattern: a user describes what they want, the AI returns code, and that code is then run in a statistics package.
Human experts as the gold standard
To see how good the AI-written code really was, the team organized a rigorous human review. Nine experienced SAS users formed three groups, each focusing on one part of performance: whether the code itself was logically correct and readable, whether it actually ran without errors, and whether the resulting output answered the original question clearly and accurately. For every task, the SAS programs from the three models were shuffled so that raters did not know which model produced which code. Scores were assigned on a five-point scale and combined into an overall total, providing a nuanced view of strengths and weaknesses across hundreds of model–task pairs. These expert ratings now sit alongside all the code and tasks in the StatLLM dataset.
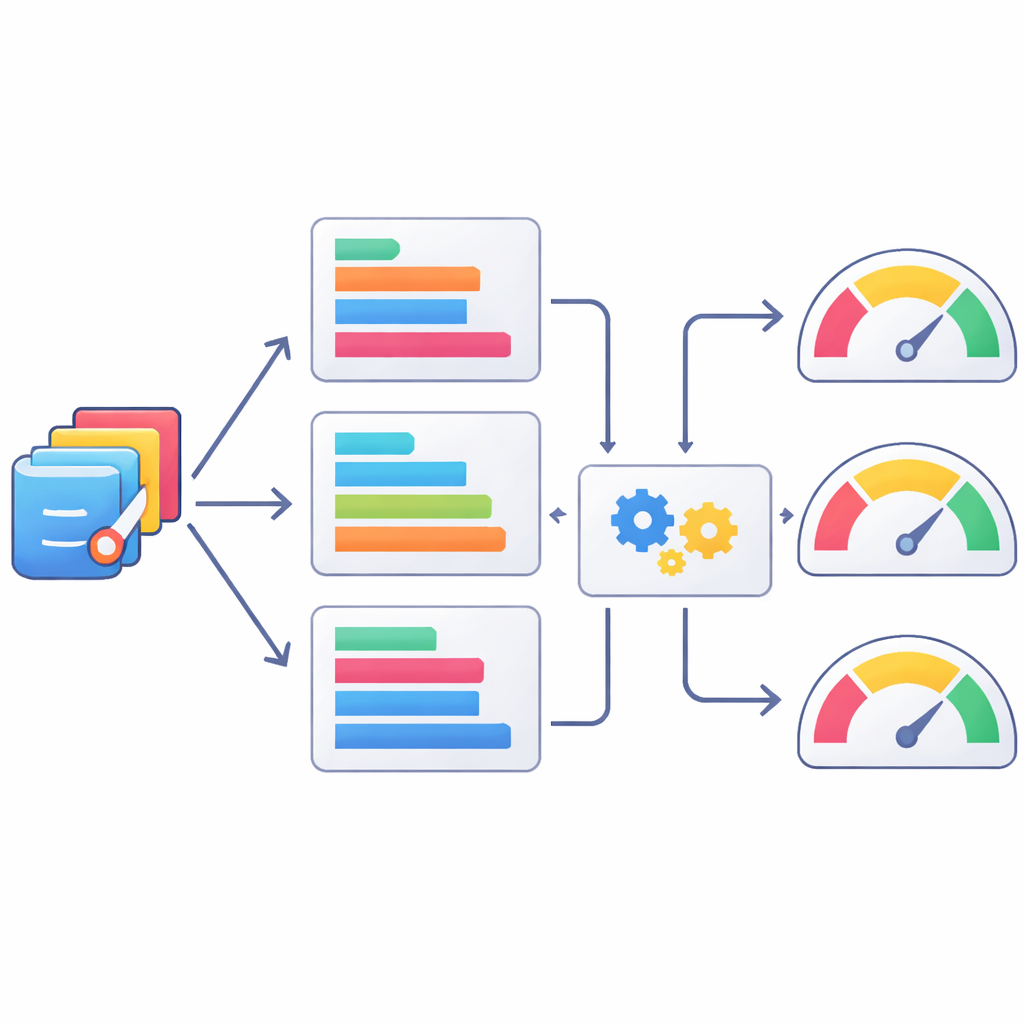
Teaching machines to judge code like humans do
Because human review is slow and expensive, the authors also explored how well automatic text-based metrics can stand in as rough judges of statistical code quality. They compared AI-generated SAS programs to the human-verified versions using a suite of well-known natural language processing scores, then checked how these scores lined up with the human ratings. Some metrics, like variants of the ROUGE score that track overlaps in short sequences of tokens, correlated better with human judgments than others, but all were only moderately aligned. The team then went a step further, training machine-learning models to predict human scores from combinations of these metrics. Methods such as XGBoost improved the match to human ratings, but still fell far short of perfectly capturing expert judgment, underscoring that automatic scores are, at best, partial proxies.
Building towards future AI-driven statistical tools
Beyond benchmarking, the authors show how StatLLM can support new tools and research directions. Because each task is described in general terms, the same problems can be used to test code generation in other languages such as R or Python, or even to combine code from multiple languages. The paper highlights ensemble approaches that could mix different AI-generated solutions for greater reliability, and demonstrates a prototype R Shiny app where users upload a dataset and task description, and an AI system automatically produces and runs R code. StatLLM also provides a platform to design and test next-generation statistical software that understands natural language instructions while being held to clear, measurable standards.
What this means for using AI in data analysis
For non-specialists, the main takeaway is that AI can already write short snippets of statistics code—but reliability is far from guaranteed, especially for tasks that go beyond simple examples. StatLLM offers a transparent, reusable way to see how well different models perform, to improve automatic checks on their work, and to design safer, more robust data analysis tools. As newer language models appear, they can be plugged into this living benchmark, keeping the field honest about what AI can and cannot yet do in serious statistical work.
Citation: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Keywords: large language models, statistical analysis, code evaluation, benchmark dataset, SAS programming