Clear Sky Science · en
A dataset of scientific citations in U.S. patent Office Actions
Why Patent Citations Matter to Everyday Innovation
When you hear about a new gadget, medicine, or clean-energy technology, there is usually a paper trail of ideas behind it. Much of that trail is recorded in patents and the documents they cite. This paper introduces a large new dataset that reveals, in unusual detail, which pieces of scientific research patent examiners rely on when deciding whether an invention deserves protection. By opening this hidden window into the examination process, the authors give researchers, policymakers, and even curious citizens a new way to study how scientific knowledge fuels real-world innovation.
A Hidden Layer in the Patent Process
Most studies of patents look only at the citations printed on the front page of granted patents. These lists seem straightforward, but they are the end result of a complex back‑and‑forth between applicants and government examiners. Along the way, examiners issue formal letters called Office Actions, where they explain why a patent should be accepted or rejected and reference earlier work they consider important. Many of these cited items, especially scientific papers, never appear on the final patent. Until now, they have been hard to access in bulk, which means research has largely ignored this rich record of how decisions are actually made.
Building a New Map from Office Actions
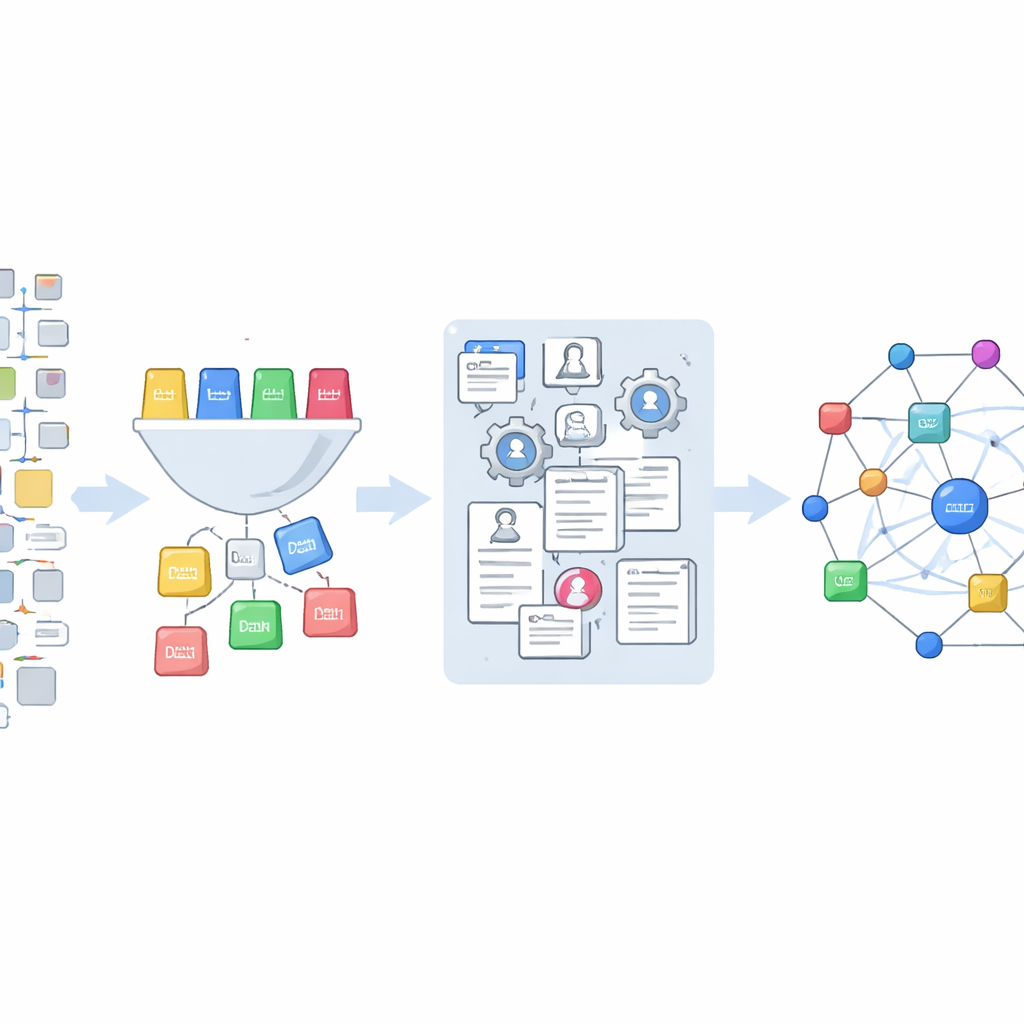
The authors tap into a trove of Office Action data released by the U.S. Patent and Trademark Office and hosted on Google Cloud. From millions of references, they isolate about 850,000 that do not point to other patents, but instead to outside sources such as journal articles, books, websites, and product manuals. They design a scheme with 14 everyday categories—ranging from books and conference proceedings to web pages and product documentation—and then train a machine‑learning model to sort each citation into one of these types. This model, refined using examples labeled with the help of an advanced language system, classifies nearly 847,000 unique citation strings.
From Messy References to Clean Research Records
Identifying which citations are scientific is only the first step. Real‑world references are messy: titles may be incomplete, years mis‑typed, and page numbers jumbled. To turn this tangle into usable data, the team feeds the raw strings into a specialized tool that parses them into pieces such as author, year, journal, and page range, while applying careful cleaning rules. They then match these cleaned records to OpenAlex, a large open database of research publications, using two strategies. When a title is available, they search by title and retain only high‑confidence matches; when it is not, they rely on combinations of author names, journal, year, and pages. If OpenAlex cannot find a match, they fall back on Crossref, another major source of publication identifiers, and loop back to OpenAlex using any discovered digital object identifiers.
How Reliable Is the New Dataset?
Because this resource is meant to underpin future studies, the authors devote substantial effort to testing its accuracy. Their classifier correctly assigns references to the right type in about 92 percent of cases overall, and it performs especially well on the most common classes such as journal articles and patents. For the matching step, manual checks show that title‑based searches become more accurate as the match score rises, reaching the mid‑90s percentile in the best group, while searches based on detailed metadata are correct 99 percent of the time in a sample. Cross‑checks of records recovered through Crossref also show near‑perfect agreement. The authors are transparent about weaker spots—such as rare categories like theses or technical reports—and encourage users to refine these where needed.
New Ways to Study How Science Drives Technology
The finished dataset links roughly 265,000 scientific references from Office Actions to individual U.S. patent applications and to rich publication records in OpenAlex. This allows researchers to ask new kinds of questions: How heavily do different examiner groups or technology areas lean on scientific papers? Which studies are considered important during examination but drop out of the final patent? Do abandoned patents draw on a different slice of the scientific record than successful ones? Because all code and data are openly released, others can adapt the tools, extend the coverage, and refine the classifications. In plain terms, this work turns an obscure and scattered set of legal documents into a clear, reusable map of how science and technology meet inside the patent system.
Citation: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Keywords: patent citations, office actions, scientific literature, innovation data, OpenAlex