Clear Sky Science · en
A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage
Why protecting living traditions needs smart reading
All around the world, living traditions such as folk music, handicrafts, and local festivals risk fading from everyday life. In China, vast amounts of writing already describe these practices, but most of it sits in long web pages that people—or computers—find hard to search or analyze. This study introduces a carefully built Chinese-language dataset and an advanced artificial intelligence model that can automatically spot key pieces of information in those texts, such as names of crafts, master artisans, materials, and places. Together, they offer new tools to help preserve and study intangible cultural heritage at digital scale.
Turning messy text into organized knowledge
The core idea behind the work is a technology called named entity recognition, which teaches computers to highlight important items in text: people, locations, times, organizations, and so on. For intangible cultural heritage, this also means recognizing special kinds of entities like the names of heritage projects, specific craft techniques, and the materials they use. The problem is that, until now, there was no public dataset tailored to this domain in Chinese, and general-purpose systems struggled with vivid descriptions, poetic wording, and regional expressions found in heritage documents.
Building a focused collection of heritage texts
To fill this gap, the authors assembled a new dataset, called ICH-NER, from China’s official Intangible Cultural Heritage Network. They focused on craftsmanship-related entries—such as traditional textiles, ceramics, metalwork, and carving—because these descriptions are rich in details about processes and materials. After cleaning out notices and duplicates, they designed eight key categories of entities: heritage item names, locations, people, organizations, time periods, ethnic groups, materials, and craftsmanship. Each Chinese character in the texts was tagged with a simple code indicating whether it belongs to an entity and, if so, of what type. In total, the dataset contains 7,779 samples and more than 21,000 labeled entities, making it a solid benchmark for future research.
Careful rules for consistent labeling
Because no standard classification system existed for this kind of heritage text, the researchers first crafted detailed guidelines based on national heritage lists and official descriptions. They ran a pilot phase to handle tricky cases, such as places that are also part of project names, or nested phrases where one entity sits inside another. A single trained annotator then labeled the whole dataset using open-source software, repeatedly revisiting earlier work to correct inconsistencies. The final data are split into training and development sets, with attention paid to keeping similar proportions of each entity type and a good mix of regional terms and writing styles in both parts.
Designing an AI model tuned to heritage language
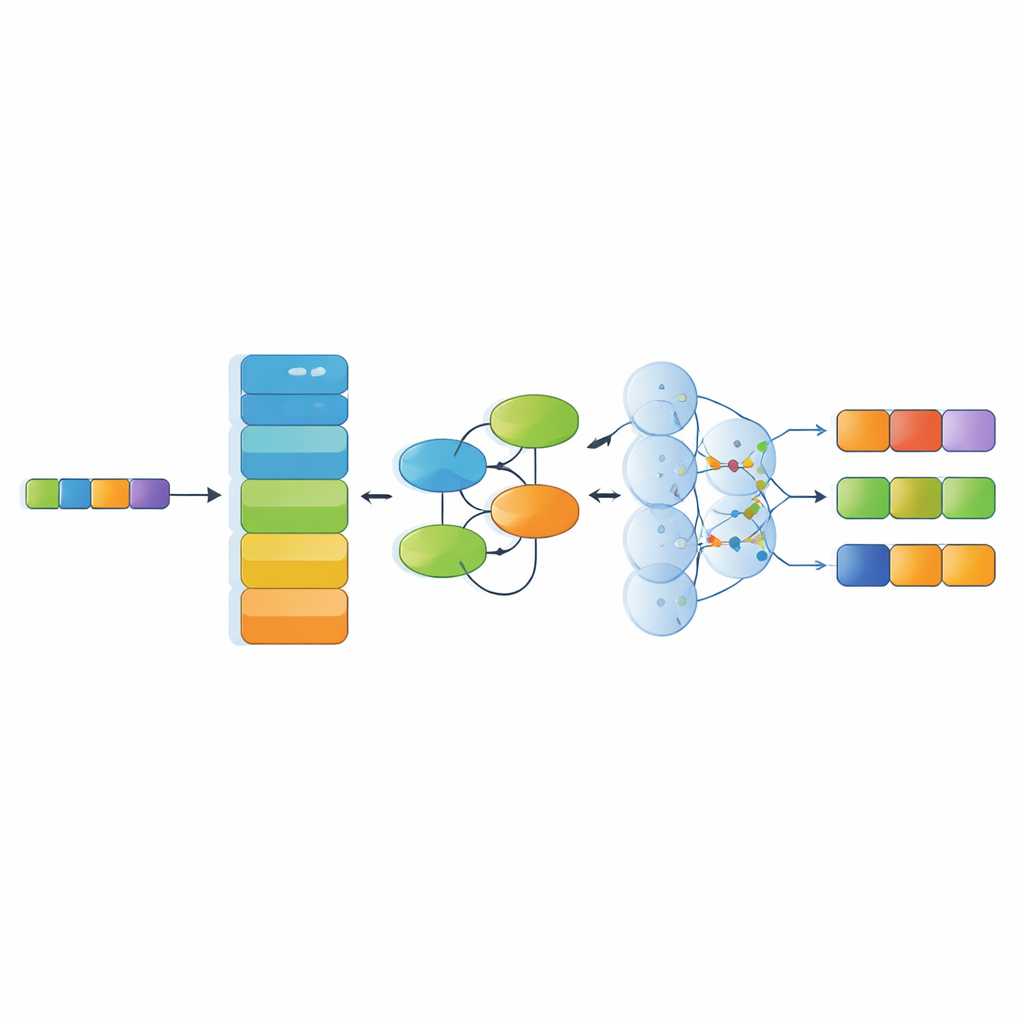
Alongside the dataset, the study proposes a specialized recognition model that stacks several modern AI components. First, a powerful language encoder (RoBERTa) converts the Chinese characters into context-aware numeric representations that reflect how words are used in surrounding text. Next, a Kolmogorov–Arnold Network module learns subtle, non‑linear patterns—such as how certain materials tend to pair with particular techniques or regions. A multi‑head attention layer then examines relationships across the whole sentence from multiple angles, and finally, a decoding layer chooses the most likely sequence of entity tags. This architecture is designed to handle long, complex sentences filled with metaphors and layered cultural references.
How well the system understands heritage text
The authors compared their model against several strong baselines commonly used in language research, including systems based on recurrent networks, lattice structures for Chinese text, and a recent method that treats entities as segments refined step by step. On the ICH-NER dataset, methods that rely on modern pre‑trained language models clearly outperformed older approaches. Their combined RoBERTa–KAN–attention–decoder system achieved the best overall balance of precision and recall, especially for challenging categories like materials, organizations, and craft techniques, where data are relatively scarce and descriptions are often intricate or ambiguous.
What this means for living culture in the digital age
In practical terms, the new dataset and model make it easier for computers to pick out who, what, where, and when from rich descriptions of traditional crafts. This structured information can feed into knowledge graphs, interactive maps, or search tools that help researchers, curators, and the public explore how techniques spread, how certain families or regions shape a craft, and how practices evolve over time. While the work is technical, its impact is human: it offers a way to turn scattered, text‑bound descriptions of living traditions into organized knowledge that can better support preservation and understanding of intangible cultural heritage.
Citation: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Keywords: intangible cultural heritage, named entity recognition, Chinese language processing, cultural datasets, digital preservation