Clear Sky Science · en
A fine-grained fundus image dataset for cataract severity assessment and diagnosis
Why clearer eye checks matter
Cataracts are the world’s leading cause of blindness, especially in older adults. Yet many people only learn they have a serious problem when their vision has already declined enough to disrupt daily life. This paper introduces a new, carefully labeled collection of eye photographs and an artificial intelligence (AI) framework designed to judge how bad a cataract is and to explain that judgment in plain language. By turning a single eye image into a detailed “report card” of lens cloudiness and visual quality, the work aims to make early, accurate cataract assessment available well beyond specialized eye clinics.
A closer look at the back of the eye
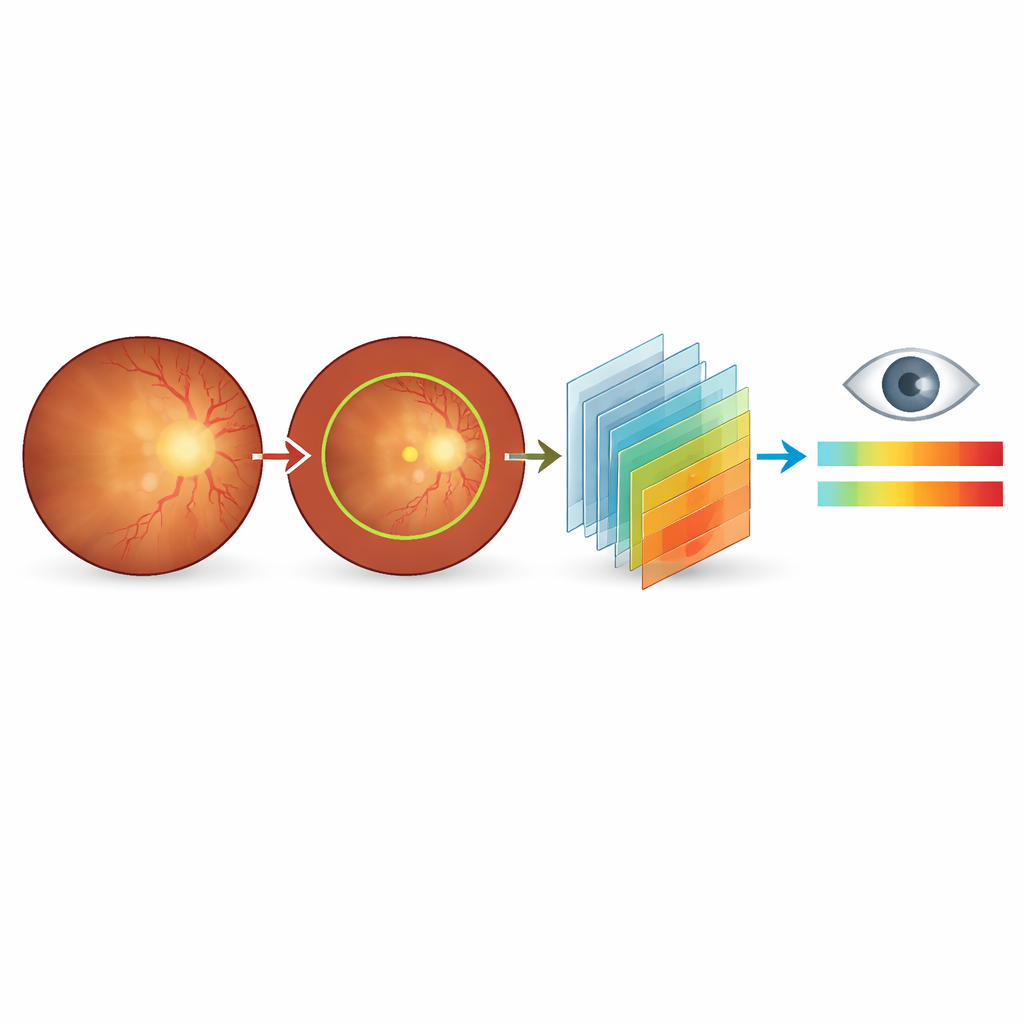
Instead of photographing the cloudy lens directly, the researchers focus on fundus images—color pictures of the retina, the light-sensitive layer at the back of the eye. When the lens becomes cloudy, these pictures grow dull and blurry, blood vessels fade, and key regions become hard to see. Doctors already use these cues informally, but until now there has not been a public dataset that links subtle changes in these images to fine-grained cataract severity scores and expert written explanations. The new Cataract Severity and Diagnostic Image dataset (CSDI) fills this gap, giving AI models the rich guidance they need to mimic expert judgment.
Building a richly annotated eye image collection
CSDI is based on 187 fundus images from patients seen at a major eye hospital in Beijing between 2023 and 2024. All images were taken with the same camera and settings to minimize technical differences. Two senior ophthalmologists first screened the images, discarding any that were poorly exposed, partially blocked, or affected by other eye diseases. For each remaining image, they evaluated overall color and clarity, how sharply the optic disc and its surface vessels appeared, how easy it was to locate the central macula region, and how many branches of the retinal blood vessels remained visible. These observations were then distilled into both a numerical score and a structured written diagnosis.
From simple labels to a detailed cataract “scoreboard”
Rather than stopping at a yes-or-no answer about cataracts, the team created a 0–10 severity scale with one decimal place. Scores near zero indicate no cataract effect on the fundus image; mid-range scores correspond to mild to moderate blurring that may warrant closer follow-up; and high scores signal severe image degradation consistent with significant vision problems and likely need for surgery. To support consistent AI training, the researchers also provided automatic outlines of the main fundus region and manual outlines and visibility flags for the optic disc. Each image is accompanied by matching English and Chinese diagnostic sentences that describe color shifts, blurring, and lost detail in a fixed order, giving models a template for how experts reason about what they see.
Teaching language-and-vision AI to act like an eye specialist
On top of this dataset, the authors tested a new diagnostic framework based on multimodal large language models—systems that look at both images and text. These models receive a fundus photo and a short instruction to “act as an ophthalmologist,” then respond with a severity assessment and a narrative explanation. The team evaluated both commercial and open-source models on two tasks: placing each case into one of five severity bands (from normal to severe) and generating a diagnostic description that matches expert wording. They then fine-tuned several open-source models using efficient techniques so they could run within hospital networks, keeping patient data on-site while still reaching or even surpassing the performance of larger commercial systems.
What this means for patients and doctors
To everyday readers, the key message is that a single eye photograph can now be turned into a nuanced picture of cataract impact, not just a crude “you have it or you don’t.” The CSDI dataset, freely available along with code, makes it possible for researchers and clinicians worldwide to build and compare AI systems that speak the same language as eye specialists. In the long run, such tools could support remote screening in communities with few eye doctors, reduce disagreement between clinicians, and help patients understand why surgery is or is not recommended—offering clearer insight into a condition whose hallmark is, ironically, the loss of clarity.
Citation: Xie, Z., Ao, M., Tang, H. et al. A fine-grained fundus image dataset for cataract severity assessment and diagnosis. Sci Data 13, 418 (2026). https://doi.org/10.1038/s41597-026-06684-8
Keywords: cataract, fundus imaging, medical AI, vision-language models, ophthalmology dataset