Clear Sky Science · en
Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML
Why Smarter Data Notes Matter for Your Health
As hospitals and researchers rush to use artificial intelligence to predict disease and guide treatment, the quality of the data feeding these tools quietly shapes who benefits—and who may be left behind. This paper introduces a practical way to “label the box” for biomedical datasets, so that anyone building AI systems can quickly see where the data came from, who it represents, and how it should—and should not—be used. By streamlining this kind of documentation, the authors aim to make medical AI fairer, safer, and easier to trust.
The Hidden Stories Inside Medical Data
Most big biomedical datasets—collections of lab results, scans, or treatment outcomes—were never created with AI in mind. They often lack clear records of how the data were gathered, which patients were included, or what was changed over time. These missing details can hide biases, such as certain groups being under-represented or key information being recorded inconsistently. When such data are used to train machine learning systems, the resulting tools may work well for some patients but poorly for others, reinforcing existing gaps in care. The authors argue that better, standardized documentation is essential to uncover and manage these risks before algorithms are deployed.
Combining the Best Ideas Into One Simple Guide
Several data “fact sheet” approaches already exist in the AI community, such as Datasheets for Datasets, Data Cards, and HealthSheets. Each offers structured questions about a dataset’s purpose, contents, collection methods, and limits. However, they were mostly designed by computer scientists for AI-specific datasets, and can be long and difficult for busy biomedical researchers to complete. To avoid reinventing the wheel, the team first mapped and harmonized fields from four widely cited templates, building a consolidated list of 136 questions that captured the most important concepts while removing overlap. They then refined this list down to 100 fields grouped into seven intuitive categories, ranging from basic information and how the data are used to issues like ethics, legal constraints, and how labels were created.
Listening to the People Who Use and Create the Data
Next, the researchers asked real-world biomedical stakeholders—which included clinicians, lab scientists, data managers, and computational experts—to rate how essential each documentation field was to their work. Twenty-three participants from a multi-center cancer research network completed the survey. The team grouped respondents into two broad “personas”: those closer to collecting data at the bench or bedside, and those who mainly manage, curate, or analyze data. This revealed clear differences in priorities. For example, both groups highly valued knowing when a dataset was last updated and when it might change again. But only the data managers and computational experts strongly prioritized details about how labels were assigned or how future updates would look, while clinicians and bench scientists placed more emphasis on intended and unsuitable uses of the data.
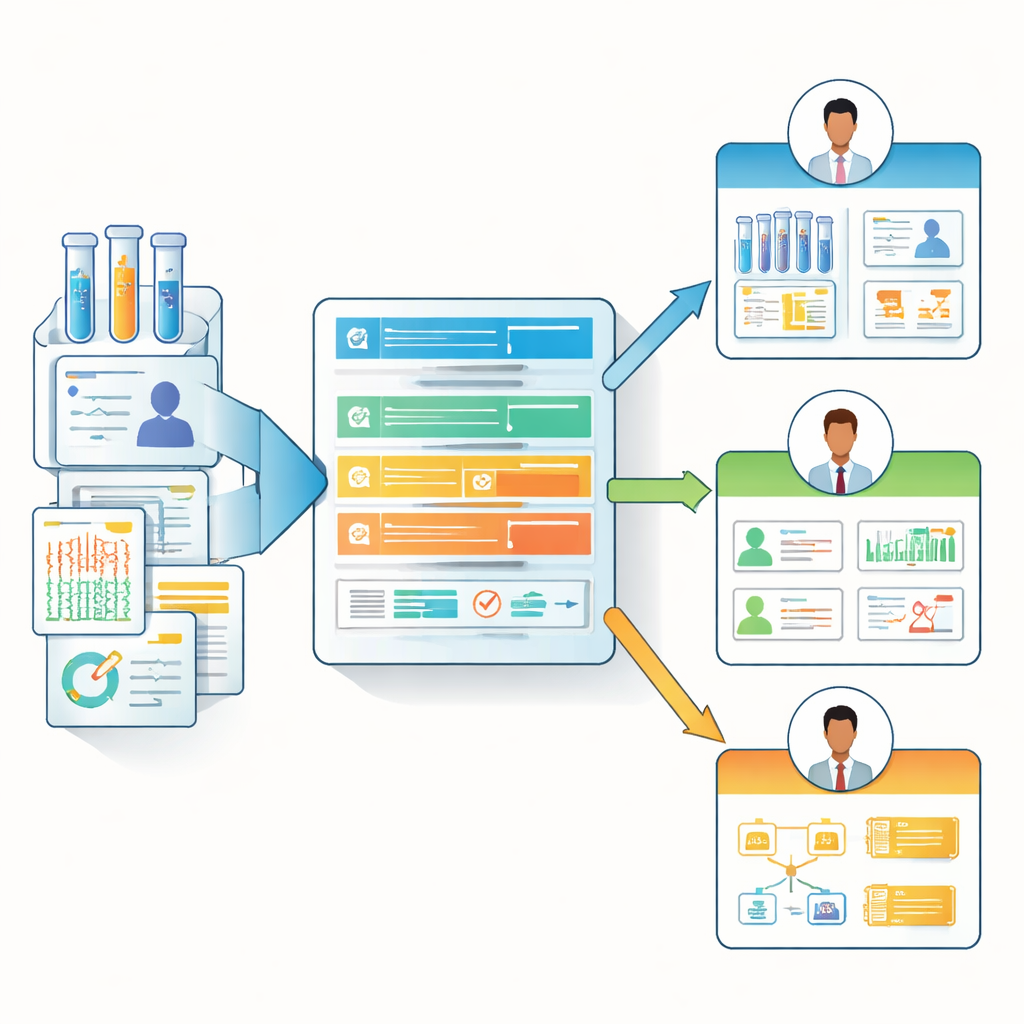
From One-Size-Fits-All to Role-Aware Data Notes
Based on these survey insights, the authors designed the “Biomedical Data Manifest,” a lightweight, web-based documentation template that adapts to different roles. Instead of forcing every contributor to fill out a massive checklist, the manifest uses a hierarchy of core questions and optional, more detailed ones. It can highlight the most relevant fields for each persona—for example, surfacing data lineage and update details for analysts, while emphasizing clinical context and constraints for front-line researchers and clinicians. The team provides a ready-to-use form (for example, in Microsoft Forms), an HTML display template, and an open-source R package called BioDataManifest. This software can automatically turn survey responses into clear manifest pages and even pull information from major public repositories like the Genomic Data Commons and dbGaP to create partial manifests for existing datasets.
What This Means for Future Medical AI
Ultimately, the Biomedical Data Manifest is a practical tool to make the “fine print” of biomedical datasets easier to create, share, and understand. By separating documentation about data from documentation about specific AI models, and by tailoring what is shown to different user roles, the framework lowers the burden on researchers while giving downstream users the context they need to judge whether a dataset is fit for a given purpose. In everyday terms, it turns opaque medical datasets into clearly labeled packages, helping AI developers spot limitations and potential biases before they affect patients. If widely adopted, this kind of role-aware, reusable documentation could make biomedical AI more transparent, reproducible, and equitable.
Citation: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Keywords: biomedical data documentation, responsible AI in medicine, dataset transparency, machine learning bias, data stewardship