Clear Sky Science · en
Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus
Helping Doctors Find the Right Patients Faster
Every clinical trial depends on finding patients who fit a long list of medical conditions, treatments, and time frames. Today, doctors often have to read through electronic health records and trial descriptions by hand, which is slow and error‑prone. This article presents a large, carefully checked collection of Spanish clinical trial texts and shows how modern artificial intelligence can turn that unstructured language into organized data, paving the way for faster, fairer, and more precise medical research.
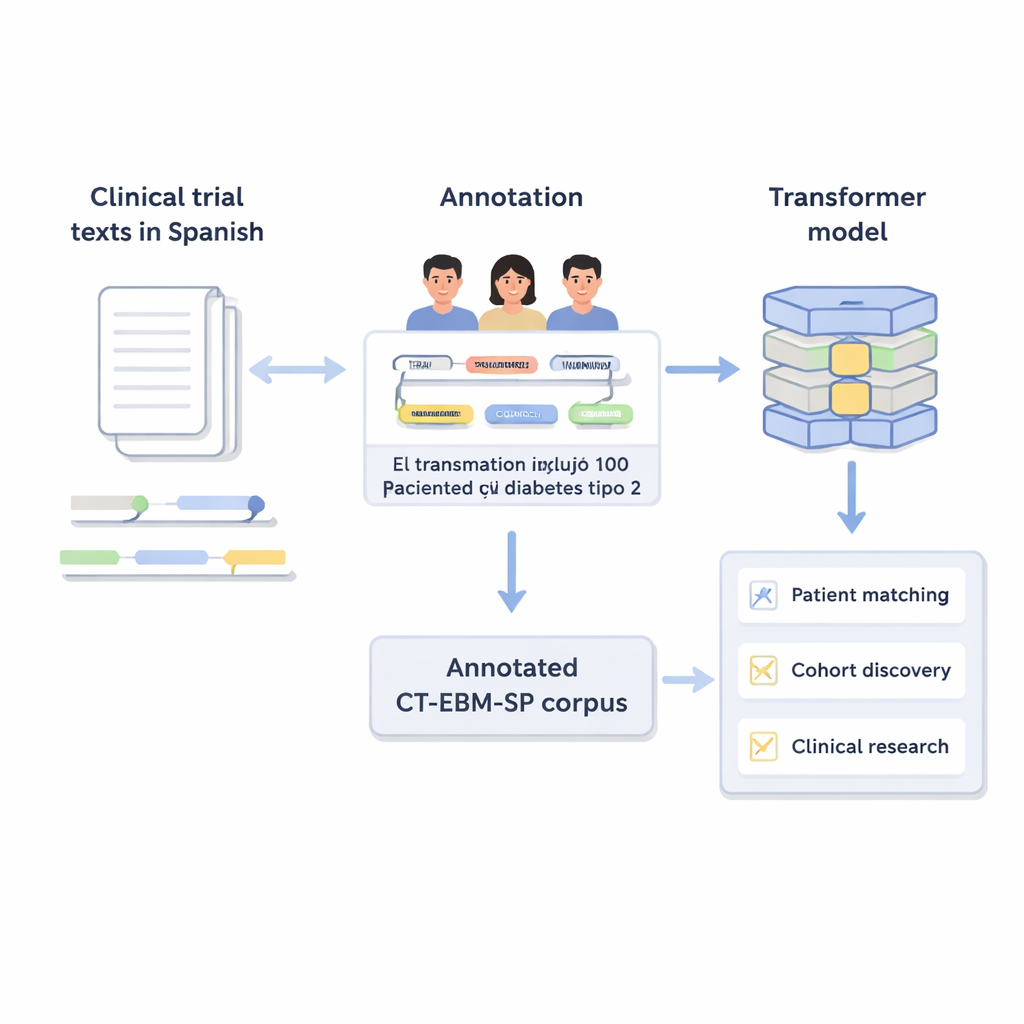
Turning Free Text into Organized Information
Clinical trials describe who can and cannot participate using everyday medical language: age limits, past illnesses, lab results, and treatments tried. Computers struggle with this kind of free text. The authors created version 3 of the CT‑EBM‑SP corpus, a dataset of 1,200 Spanish clinical trial texts containing nearly 300,000 words. Human experts went through these texts and marked 23 types of medical entities, such as diseases, drugs, test results, and time expressions, as well as cues for negation (for example, “no history of”) and uncertainty. They also labeled 11 attributes that capture details like whether an event is in the past or future and whether it happened to the patient or a family member.
Making Medical Terms Speak the Same Language
A major challenge in medicine is that the same concept can be written in many ways. To solve this, the team linked most of the marked entities to standardized codes from the Unified Medical Language System (UMLS), a huge multilingual medical dictionary. This step, called concept normalization, means that different spellings or phrases all point to the same unique identifier. For example, several variants of “25‑hydroxyvitamin D” are all mapped to a single UMLS concept. In total, the corpus includes over 87,000 entities and more than 68,000 relationships, and about 82% of entities were successfully normalized. Two experts independently checked these links, achieving very high agreement, which indicates that the annotations are reliable.
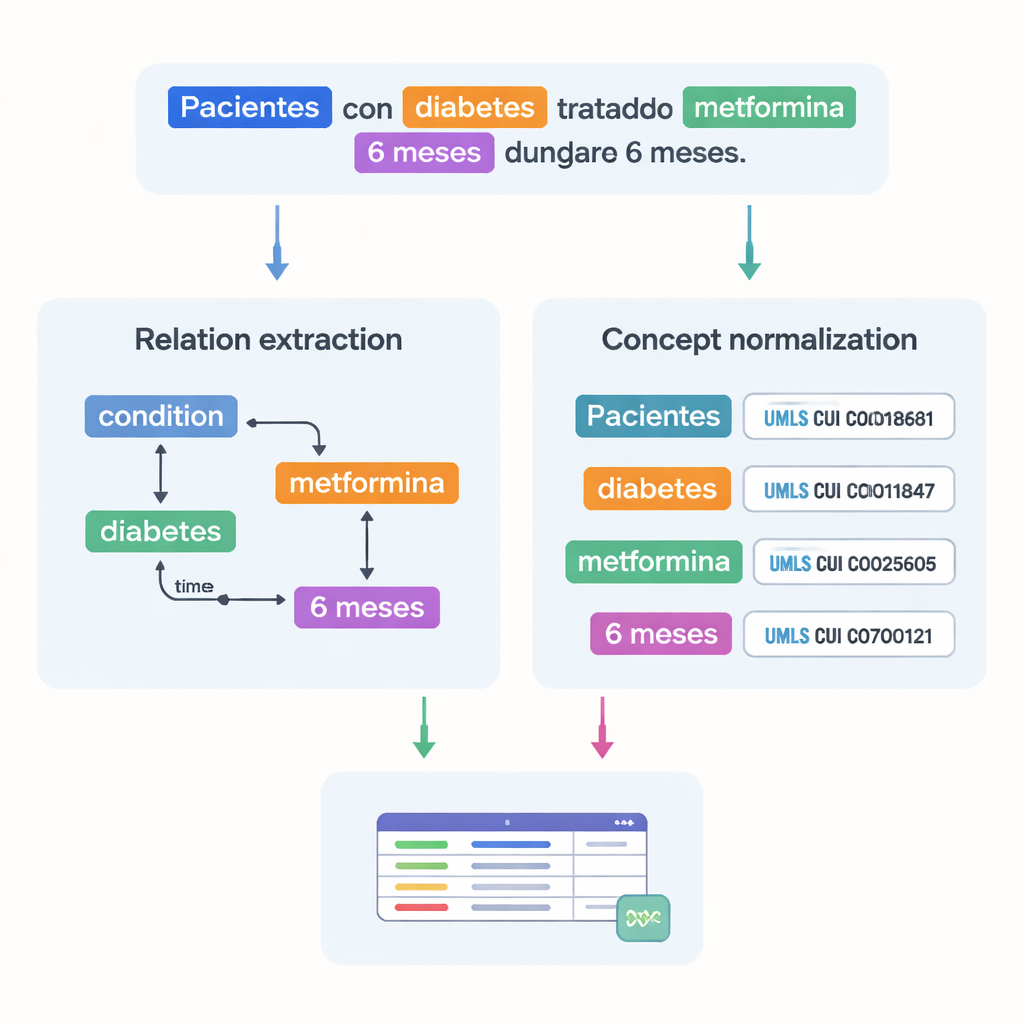
Capturing How Medical Facts Relate to Each Other
Beyond listing medical terms, the dataset records how they connect. The authors designed 18 types of relations to capture patterns that matter in trials, such as which dose belongs to which drug, how long a treatment lasts, or which condition a patient experiences. Temporal relations show whether one event happens before or after another, and other links mark where a disease occurs in the body or whether a phrase expresses negation or speculation. Together, these relations let computers build graphs of a patient’s situation—who the patient is, what condition they have, what treatment they receive, and under what timing—rather than just recognizing isolated words.
Training and Testing Modern AI Models
To demonstrate that the corpus is practically useful, the authors fine‑tuned several transformer‑based AI models, including multilingual versions of BERT and RoBERTa. They trained these models on two tasks: relation extraction, which learns to recover the links between entities, and medical concept normalization, which maps text to UMLS codes. On relation extraction, the best model reached an F1 score close to 0.88, meaning it correctly identified most relations with relatively few mistakes. For concept normalization, a multilingual model called SapBERT, used without extra training, correctly guessed the right concept on its first try almost 90% of the time. These results show that well‑annotated, medium‑sized datasets can power accurate, efficient models even without massive general‑purpose language systems.
Why This Resource Matters for Future Care
The CT‑EBM‑SP corpus and associated models provide a foundation for tools that can automatically parse Spanish clinical trial texts, match them against patient records, and support cohort discovery in hospitals. Because the data are aligned with international medical standards and have been carefully checked by experts, they can also help develop similar resources for other languages with fewer digital tools. In everyday terms, this work is about making it easier and safer for the right patients to be offered the right trials, speeding up medical discoveries while reducing the burden on healthcare professionals.
Citation: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Keywords: clinical trials, medical text mining, Spanish healthcare, transformer models, evidence-based medicine