Clear Sky Science · en
Scene-level movie data from Amazon X-Ray in the US market combined with IMDb
Why Movie Scenes Matter for Understanding Culture
Movies shape how we see the world, yet most research on film has focused on box-office numbers, basic genres, or star power, not on what actually unfolds on screen from scene to scene. This article introduces a new dataset that lets researchers zoom in to the level of individual scenes, characters, and lines of dialogue for more than three thousand movies streamed in the U.S. on Amazon Prime Video. By combining Amazon’s X-Ray feature with the Internet Movie Database (IMDb), the authors offer a detailed, standardized map of who appears where and when in each film, opening the door to richer studies of representation, storytelling, and even artificial intelligence systems that learn from video.
From Rough Scripts to Finished Scenes
Until now, most large-scale studies of movies have relied on screenplays or subtitle files. These sources are helpful but imperfect. Scripts are often early drafts that differ from the final cut, and they may omit minor characters or late editing changes. Subtitles capture spoken lines but miss silent characters, background extras, and purely visual storytelling—the camera lingering on a character’s face, for example. Because of these gaps, earlier efforts to track who interacts with whom on screen, or how different groups are represented, have had to guess from text alone, which can lead to errors in identifying characters and their relationships.
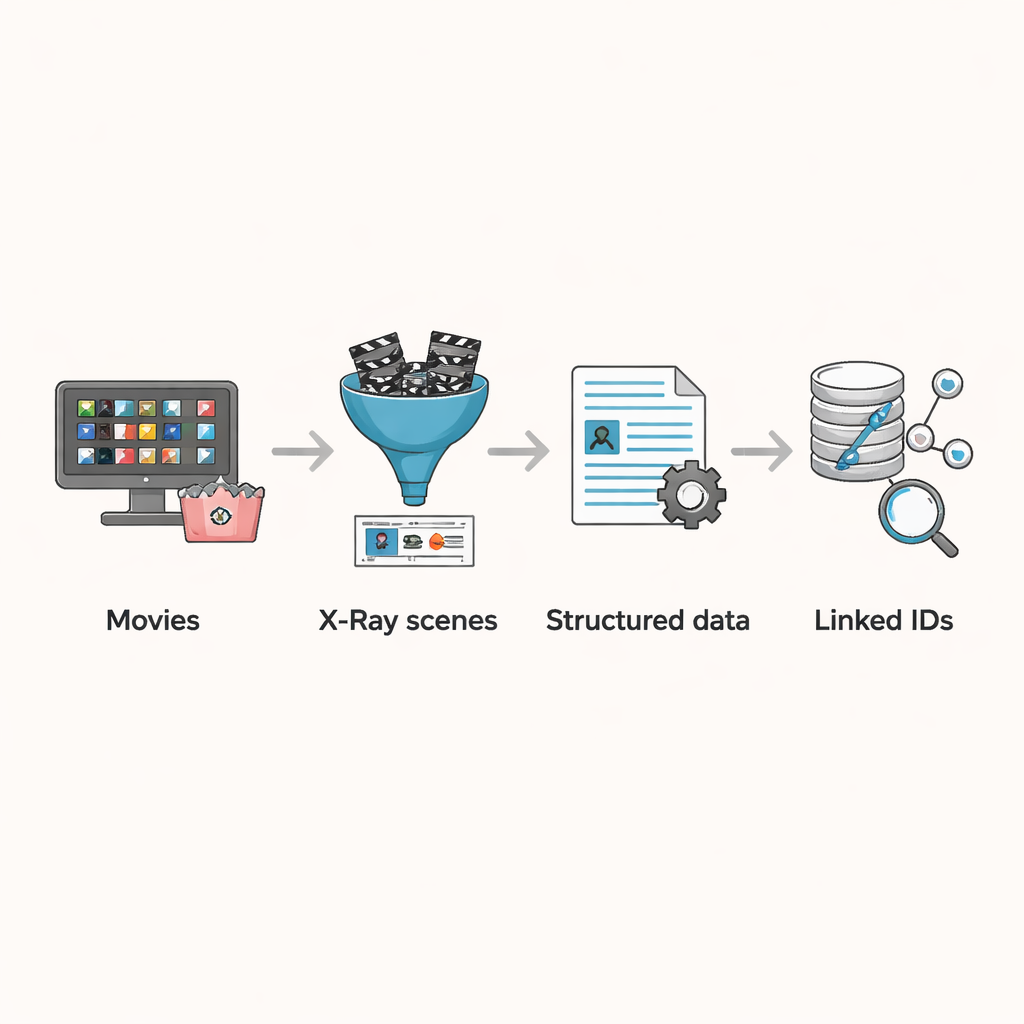
Turning X-Ray into Research-Ready Data
Amazon’s X-Ray feature offers a way around these problems. When viewers pause a movie, X-Ray shows which actors and characters are currently on screen, information that is curated and tied directly to the final edited film. The authors built a pipeline to harvest this scene-level data for 3,265 movies available in the U.S. Prime Video catalog as of August 2023. They first collected all Prime-included movie entries, filtered out those without X-Ray information, and removed duplicates caused by repeated titles or alternate versions. For each remaining film, they intercepted the data streams used by the player to load X-Ray and subtitle information, saving the results into structured files that list scene boundaries, the characters present in each scene, and, for most titles, the precise timing of every subtitle segment.
Linking Scenes to the Wider Movie World
The real power of the dataset comes from connecting these scene breakdowns to external information. While X-Ray already links each character to an IMDb profile, it does not include an IMDb ID for the movie itself. The authors designed a matching algorithm that starts from a film’s title, retrieves several candidate matches from IMDb, and then compares the top-billed cast from IMDb with the actors listed in the X-Ray data. If at least one major actor overlaps, the movie is treated as a match. This automated process correctly matched the vast majority of films, and the team then manually checked the remaining few hundred edge cases, fixing misclassifications and removing entries that were not actually narrative movies, such as stand-up specials. The final result is a carefully cleaned set of movies where each scene, character, and subtitle can be linked to rich metadata such as year, country, and cast demographics.
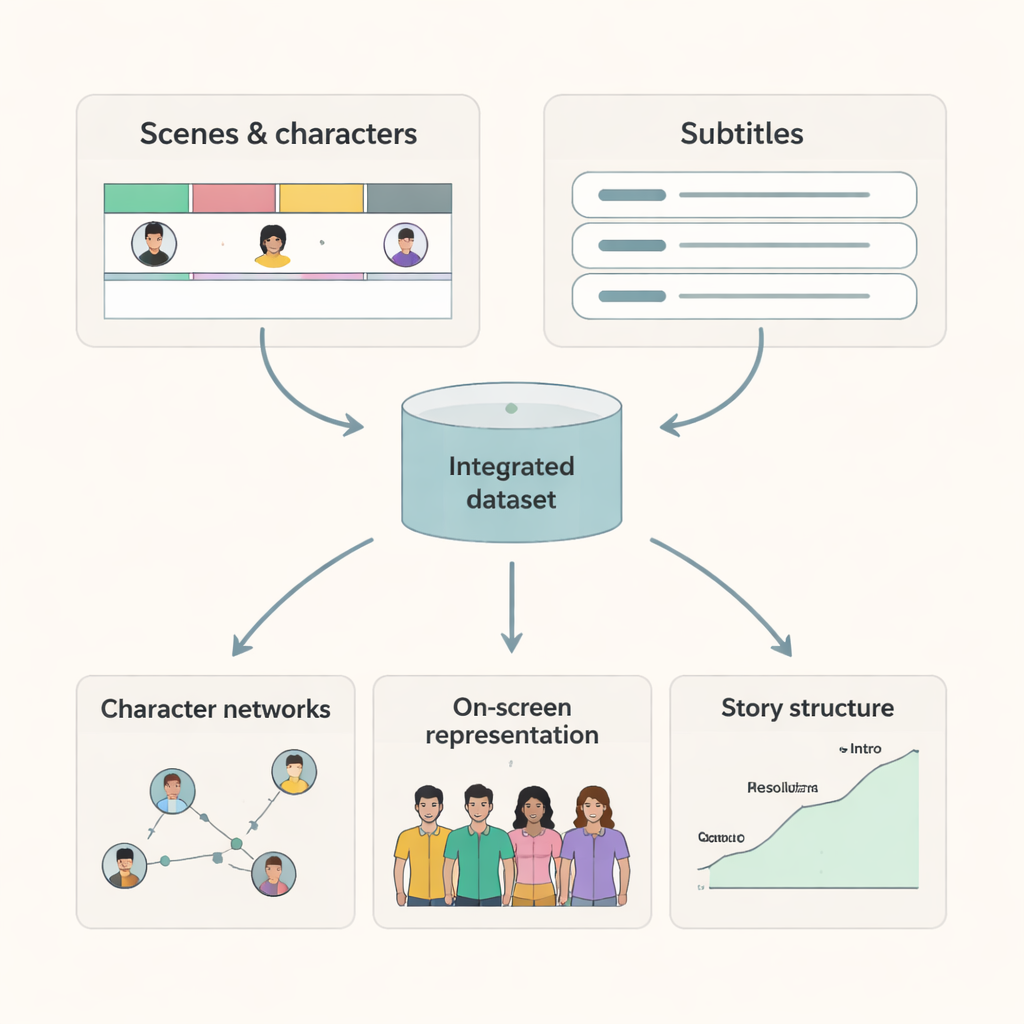
What Researchers Can Do with These Movies
Because every scene has clear start and end times and a list of who appears, researchers can now build precise maps of character interactions and screen time. Subtitles aligned with scenes make it possible to study how language differs across characters and contexts, or how certain themes unfold through dialogue. By combining this dataset with additional information from IMDb and other sources, scholars can examine questions such as: How has gender balance on screen changed over decades? Do characters from different backgrounds get equal narrative attention? How do patterns of interaction differ between genres or countries? The dataset also offers a high-quality benchmark for artificial intelligence models that aim to understand video content, because it provides ground truth about who is visible and when.
A New Lens on Everyday Films
In plain terms, this work turns thousands of movies into a searchable, scene-by-scene catalog of who shows up, who talks, and how stories are structured. While the collection is limited to titles available on U.S. Prime Video and depends on Amazon’s internal X-Ray processes, it still covers films across many decades and genres, not just famous award winners. That breadth allows researchers to study everyday movies, not only the classics that survive in memory. As the dataset is updated and expanded, it promises to deepen our understanding of how films reflect society—and to give both social scientists and technologists a more faithful picture of what actually happens on screen.
Citation: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Keywords: movie datasets, scene-level analysis, Amazon X-Ray, IMDb metadata, on-screen representation