Clear Sky Science · en
CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience
Why looking at pictures can reveal how our minds work
Every day, our eyes take in thousands of images—from coffee cups and smartphones to dogs, trees, and crowded streets. Behind the scenes, our brains rapidly recognize what we see and often remember it later. The CNeuroMod-THINGS project set out to capture this hidden activity in extraordinary detail, creating one of the most deeply measured brain datasets ever collected while people look at real‑world pictures. This resource is meant to fuel the next generation of brain and artificial intelligence research.
Building a rich library of brain responses
Instead of scanning hundreds of volunteers once or twice, the team repeatedly scanned just four highly committed participants. Each person came back for 33 to 36 visits, adding up to around 200 hours of brain imaging in the wider CNeuroMod project and dozens of hours devoted to pictures alone. During these sessions, volunteers viewed up to 4,320 distinct photographs drawn from the THINGS image collection, which spans 720 everyday object categories such as tools, animals, vehicles, and furniture. This careful choice of images ensures that many corners of our visual world are represented, not just a few popular objects.

A memory game inside the MRI scanner
To keep participants engaged and to probe memory, the researchers turned the picture viewing into a continuous recognition game. On each trial, a single image appeared at the center of the screen while the person lay in an MRI scanner. Using a custom video‑game‑style controller, participants reported whether they believed the picture was new or had been seen before, and how confident they were in that judgment. Most images were shown three times: once for the first encounter, once again a few minutes later in the same visit, and once more in a later visit, often about a week apart. This design allowed the team to compare short‑term and longer‑term memory for exactly the same pictures while tracking the corresponding changes in brain activity.
Capturing detailed signals from vision and memory
The dataset goes far beyond simple “on/off” measures of brain activity. The authors used advanced analysis methods to estimate a separate response for every single trial and every image in each tiny three‑dimensional pixel of the brain scan. They also tracked where people were looking using eye‑tracking cameras, monitored breathing and heart rate, and measured head motion. Quality checks show that the signals are remarkably stable: participants responded on almost every trial, held their gaze near the center of the screen, and moved very little. In key visual areas—regions known to respond strongly to faces, bodies, or scenes—the same picture produced highly consistent patterns of activity each time it appeared. These patterns were strong enough that when the responses were plotted in a simplified two‑dimensional map, images with similar meanings (for example, animals or vehicles) tended to cluster together.
Mapping what different brain regions care about
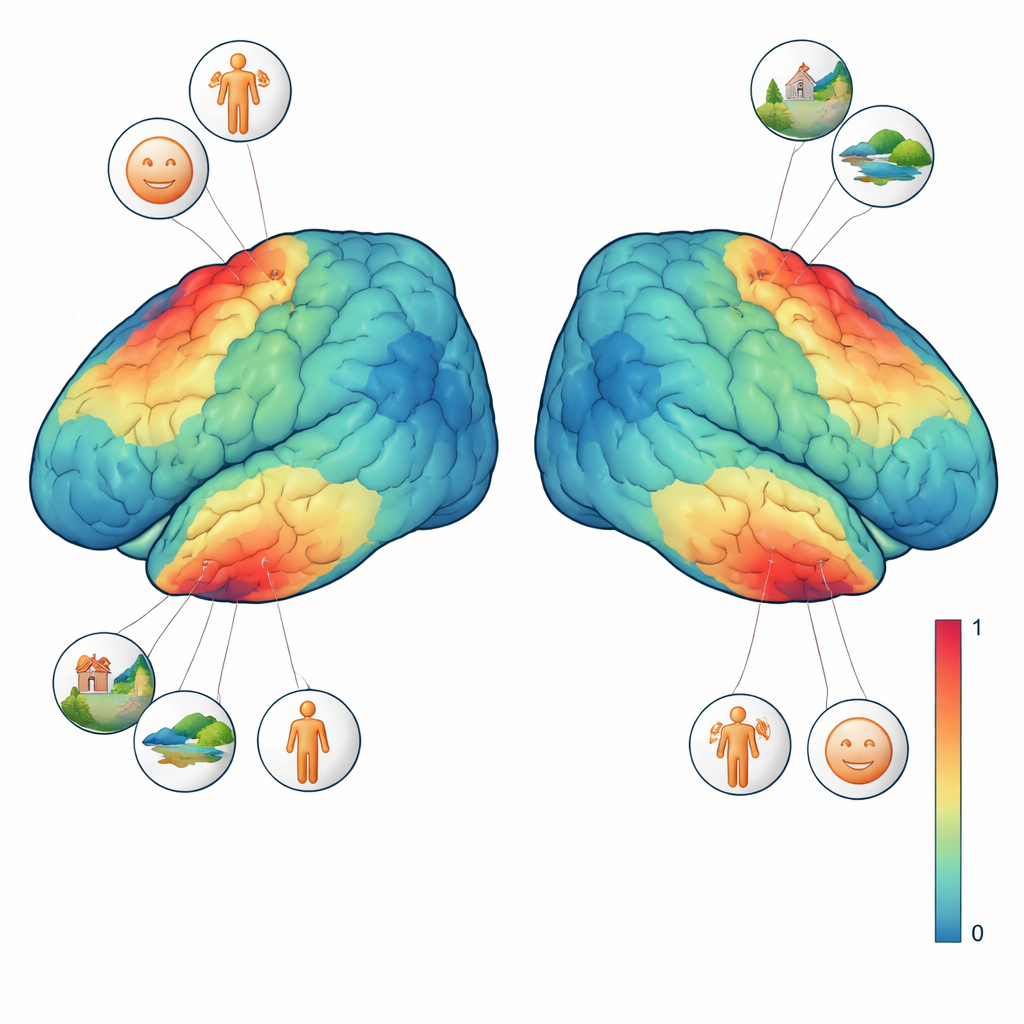
To better interpret these signals, three of the four participants completed additional vision tests. In one, sweeping shapes moved across a textured background to reveal which part of the visual field each brain region “sees.” In another, short blocks of faces, places, body parts, characters, and generic objects were shown to pinpoint regions that prefer one type of image over others. Combining these localizer tasks with the main experiment, the team could ask precise questions such as: does a single voxel respond more when a face is present, or when the whole scene is visible? They found that face‑selective regions responded most strongly whenever any kind of face appeared, while a scene‑selective region preferred images with rich backgrounds like rooms, streets, or landscapes, even when no people were visible. These fine‑grained preferences emerged at the level of individual images and even single voxels.
A foundation for smarter models of vision
At its core, CNeuroMod-THINGS is a carefully curated public resource rather than a one‑off result. All brain data, eye‑tracking, behavioral responses, image annotations, and analysis code are freely shared under an open license. Because the same four people were scanned in many other tasks—watching movies, playing video games, listening to stories—researchers can now build detailed, person‑specific models that link controlled experiments with more natural experiences. For non‑specialists, the takeaway is that we now have a high‑resolution “look‑up table” showing how a real human brain responds to thousands of everyday pictures. This will help scientists test ideas about visual perception and memory and guide the design of artificial vision systems that see the world a little more like we do.
Citation: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Keywords: fMRI, visual perception, object recognition, brain data, memory