Clear Sky Science · en
Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing
Listening In on How the Brain Hears Real Conversations
Most of what we say and hear every day is casual conversation, not single words or carefully read sentences. Yet much of brain research on language has relied on artificial tasks. The Kymata Soto Language Dataset changes this by providing a rich, open collection of brain recordings from people simply listening to lively radio discussions in English and Russian, giving scientists a powerful new window into how our brains process natural speech.
A New Library of Brain Responses to Real Speech
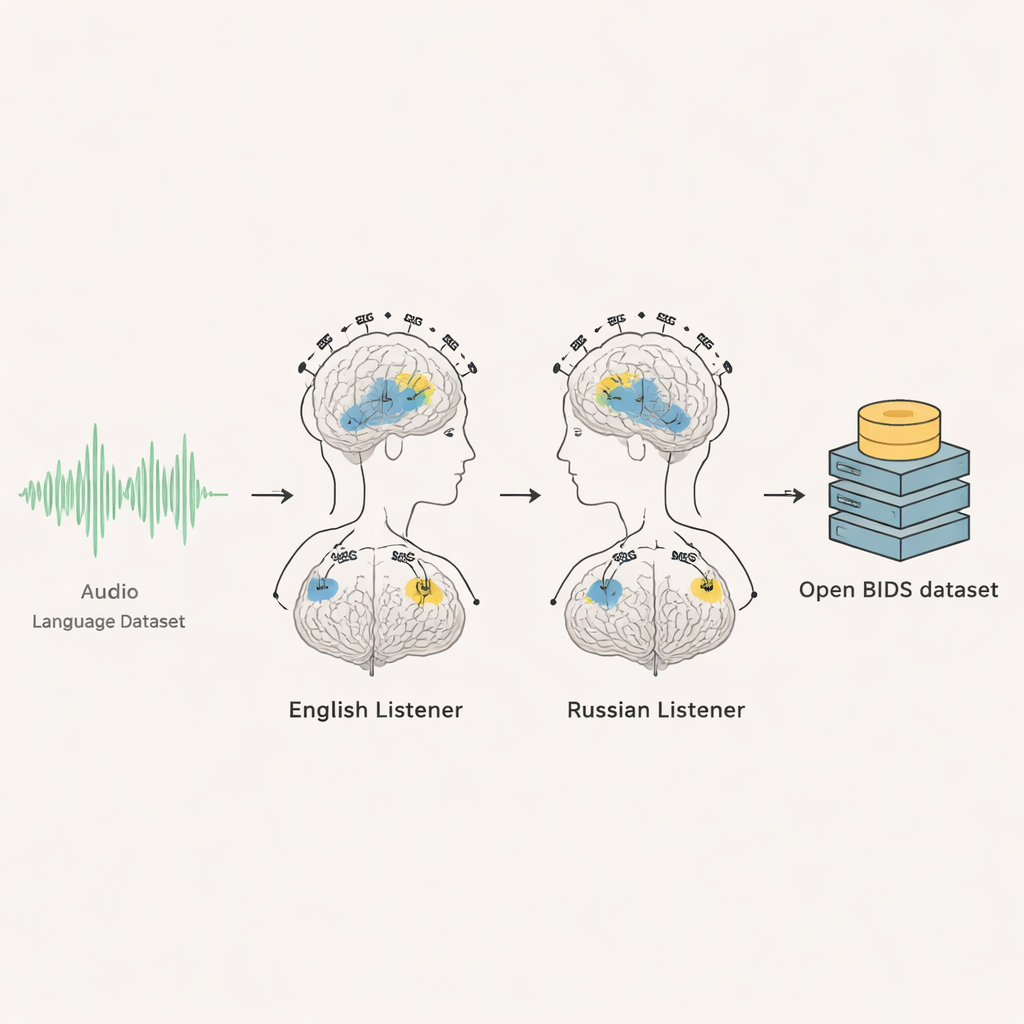
This project brings together two advanced brain‑recording methods—electroencephalography (EEG) and magnetoencephalography (MEG)—from 35 adults: 20 native English speakers and 15 native Russian speakers. While they sat quietly and listened to about six and a half minutes of radio‑style conversation in their own language, their brain activity was recorded a thousand times per second. Each person heard the same audio several times, allowing researchers to average across repeats and pick out the brain’s reliable responses from the background noise. The result is a detailed, time‑locked record of how the brain reacts, moment by moment, as people follow an unfolding discussion.

Conversations About Ice Cream and Coffee
Rather than using classic stories or artificial sentences, the team chose engaging but everyday topics: the history of ice cream for English listeners and the history of Colombian coffee for Russian listeners. Both recordings came from BBC studio discussions involving three speakers (two men and one woman). The conversations were edited to about 400 seconds and presented at comfortable listening levels through earpieces. After each repeat, participants answered one or two simple multiple‑choice questions about the content—just enough to ensure they stayed alert and followed the story, not to test them aggressively.
Keeping the Eyes Busy but the Mind on Sound
While participants listened, they stared at a central cross on a screen. Around it, clouds of colored dots drifted and changed in a seemingly random way. These moving dots served two purposes: they helped keep people’s gaze steady, which improves data quality, and they created controlled patterns of visual motion and color that other researchers can later analyze. Importantly, the dots were not synchronized with the speech content, so they did not “illustrate” the story or add meaning, but they did provide a consistent visual background that can be studied alongside the sounds.
From Raw Brain Signals to Ready‑to‑Use Data
The researchers carefully documented every part of the experiment and organized the dataset using an international standard for brain data called BIDS. For each volunteer, there are raw EEG and MEG recordings, timing markers for when the audio started, second‑by‑second visual events, and practice segments. The team also provides the original audio files, full transcripts, and precise timing for when every word and even every individual speech sound began. They include scripts so others can automatically reproduce the exact audio excerpts used. For the English group, anonymized MRI brain scans are shared so that brain responses can be mapped onto individual brain anatomy; for the Russian group, consent did not permit sharing MRI images, so users are advised to rely on standard average brain templates.
Checking That the Signals Make Sense
To make sure the data are scientifically trustworthy, the authors ran validation analyses focused on how the brain tracks changes in sound loudness over time. They transformed the audio into several mathematical descriptions of “time‑varying loudness” and then examined where and when the brain responses lined up with those loudness patterns. For both English and Russian listeners, the brain showed similar timing patterns, consistent with what has been reported in earlier work. This agreement across languages and with past studies is a strong sign that the recordings are clean, reliable, and ready for others to build on.
Why This Matters for Future Brain and Language Research
For non‑specialists, the main takeaway is that this dataset is a new common resource that lets many different research teams study how real, spontaneous speech is processed in the brain. Because it is open, well‑annotated, and recorded in two different languages, it can support projects ranging from basic questions about how we understand conversation, to comparisons across languages, to ambitious efforts to decode speech directly from brain activity. In short, the Kymata Soto Language Dataset is less about answering one single question and more about giving the scientific community a high‑quality, shared foundation for exploring how our brains make sense of the conversations that fill our daily lives.
Citation: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Keywords: brain and language, speech perception, EEG MEG, naturalistic conversation, open neuroimaging data