Clear Sky Science · en
Data science academic programs in the pre-ChatGPT erain the Midwestern United States: a curated dataset
Why this matters for students and communities
Across the United States, new data-focused degrees seem to appear every semester, but it can be hard to tell what “Data Science,” “Data Analytics,” or an “Interdisciplinary” program actually mean. This article describes a carefully built dataset that maps and organizes every data-related academic program in the Midwestern United States just before tools like ChatGPT became widespread, offering a clear snapshot of how colleges were training the next generation of data professionals.
A snapshot taken before the AI wave
The authors set out to capture the state of data science education in 2023, right before generative artificial intelligence began reshaping teaching and technical work. They focused on higher education institutions across 12 Midwestern states, from community colleges to major universities. Whenever a program’s name included the word “data,” they examined it in detail: Where was it taught? Was it a major, a minor, a certificate? Was it aimed at undergraduates or graduate students? Which departments were in charge, and what subjects did the coursework cover? By freezing this moment in time, the dataset allows future researchers to see how educational offerings change as AI tools spread.
Sorting out different kinds of data programs
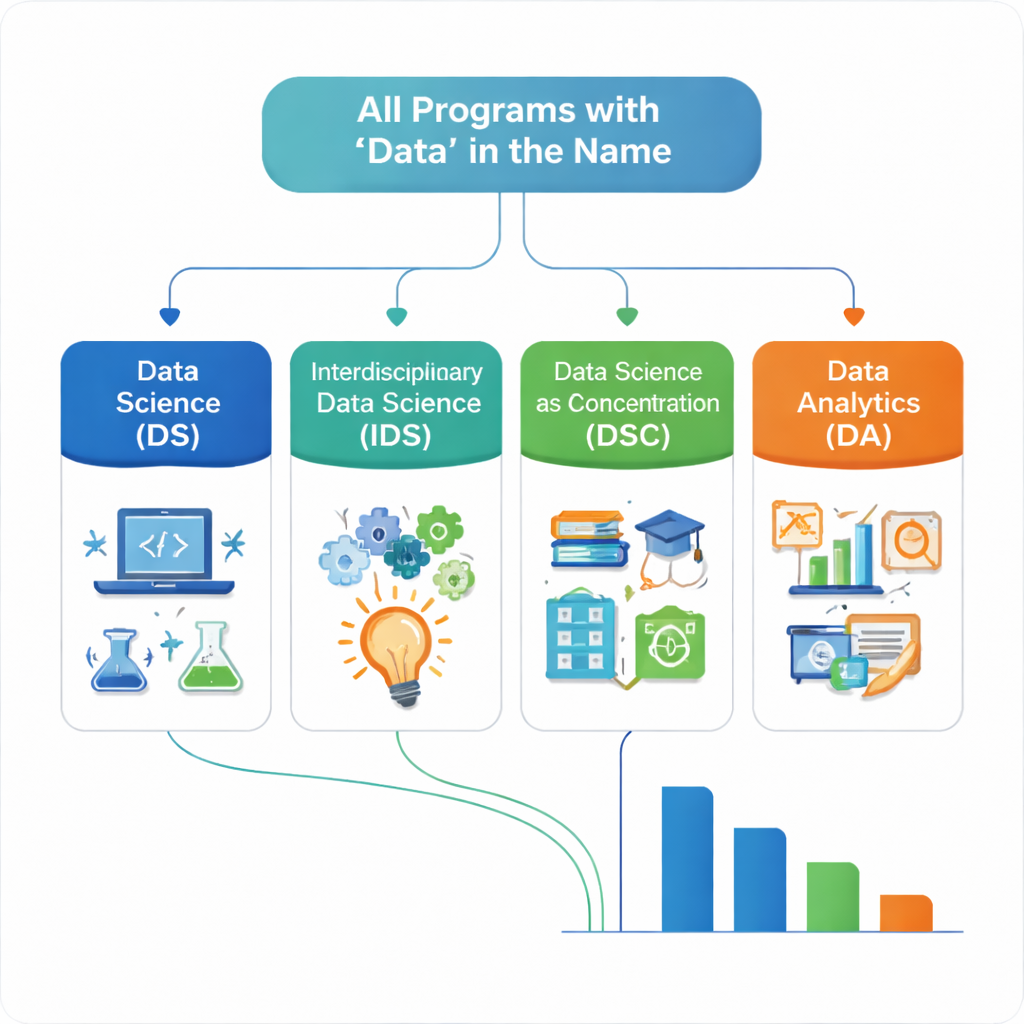
One of the biggest challenges the authors faced is that “data science” is used in many different ways. Two degrees with nearly identical names can train students for very different careers. To bring order to this chaos, they created a reproducible classification system with four main groups. A classic Data Science program combines substantial mathematics, statistics, and computer science and is typically led by those departments. Interdisciplinary Data Science programs share that technical core but are either steered partly by non-technical departments or require students to add a second major or minor. Data Science as a Concentration describes cases where “data” is a track inside another degree. Data Analytics programs include offerings that use the word “data” but lack the full blend of math and computing, or are directed by departments outside the core quantitative fields.
How the information was collected and checked
To build the dataset, the team first used the College Board’s college search tool to compile a list of institutions in the Midwest. They then visited each school’s website by hand, searched for programs with “data” in the title, and recorded details in a structured spreadsheet. For every program they documented the state, school, city, program name, whether it was offered on campus or online, its level and type, and whether it was a major, minor, or certificate. They treated majors and minors as potentially distinct offerings and paid close attention to which departments were officially responsible. When department leadership was unclear, they turned to course lists and subject tags to infer whether the curriculum truly combined mathematics and computing. After the manual work, they used Python code to clean the data, remove duplicates, enforce consistent categories, and flag any contradictions or missing information.
What the dataset reveals about the Midwest
The final collection includes 404 unique programs from 225 school systems. More than half of these are classified as Data Science, suggesting that many Midwest institutions have embraced the more technical, math-and-computing-focused model. About one third fall under Data Analytics, often linked to business, information, or technology units, and typically placing less emphasis on both math and computer science together. Interdisciplinary Data Science and Data Science as a Concentration make up smaller but important portions, reflecting efforts to blend data skills with areas like business, engineering, or the social sciences. The authors also group schools into types—community colleges, tech and engineering schools, universities, and other colleges—and show that universities dominate the number of offerings, while community colleges and technical schools lean more heavily toward Data Analytics programs.
How others can use this resource
The dataset, publicly available through Harvard Dataverse along with the code used to process and validate it, is meant to be reused. Policymakers can examine how data-related programs are distributed across states and school types when planning investments in workforce development. Department chairs and curriculum designers can benchmark their own programs against others nearby or of similar type. Education researchers can track how program names, structures, and leadership change over time, especially as AI tools become more deeply embedded in classrooms and workplaces. Instructors can even use the data in class projects, letting students explore the real educational landscape they are about to enter.
What this work tells us, in plain terms
At its core, this article offers a well-organized map of how Midwestern colleges were teaching data skills just before the generative AI boom. By clearly separating different kinds of “data” programs and documenting who runs them and what they require, the authors provide a baseline for understanding how education keeps up with rapid technological change. Years from now, this snapshot will help show whether programs became more technical, more interdisciplinary, or more shaped by AI—and will guide schools and communities as they decide how best to prepare students for a data-driven world.
Citation: Blackford, D., Maria Selvitella, A. Data science academic programs in the pre-ChatGPT erain the Midwestern United States: a curated dataset. Sci Data 13, 236 (2026). https://doi.org/10.1038/s41597-026-06553-4
Keywords: data science education, academic programs, Midwestern universities, data analytics degrees, higher education dataset