Every day, we effortlessly spot patterns: a red light means stop, a crowded street means slow down, a certain posture means a pet is about to leap. Behind these skills lies the brain’s ability to uncover hidden, or “latent,” structure in the world and reuse it across many different tasks. This paper asks a deceptively simple question: what makes one pattern of population brain activity better than another for solving many related tasks quickly and accurately?
The Hidden Knobs Behind Neural Codes Figure 1.
The authors study brain activity at a population level, treating the firing of many neurons as points in a high-dimensional space. They focus on tasks that share an underlying set of latent variables—for example, an object’s shape, size and position, or an animal’s location and speed. A downstream neuron or circuit reads these patterns out with a simple linear rule, akin to drawing a plane through the cloud of points to separate “category A” from “category B.” Instead of simulating every neuron in detail, the authors derive an analytical formula that predicts how well such a readout will generalize to new examples, given the geometry of the neural activity. Remarkably, they find that performance is governed by just four statistics that capture how strongly neurons reflect the latent variables, how cleanly different variables are separated, how noise is arranged and how many effective dimensions the activity occupies.
Four Simple Ingredients of Good Generalization
The first ingredient is overall correlation between individual neurons and the latent variables: when small changes in the hidden variables cause clear shifts in neural responses, downstream readouts have more signal to work with. The second and third ingredients describe “factorization”: ideally, different latent variables are encoded along independent directions, and random noise drifts in directions that are orthogonal to these signal axes. This makes it easier for a single linear boundary to transfer across many tasks that all depend on the same hidden structure. The fourth ingredient is effective dimensionality, which captures how many directions in activity space the population really uses. Higher dimensionality tends to dilute noise across more directions, improving reliability, but it must be balanced against how clearly the signal aligns with behaviorally relevant variables.
Testing the Theory in Artificial and Biological Brains Figure 2.
To check their theory, the authors first apply it to artificial neural networks. In multilayer perceptrons trained on many related classification problems, and in a deep network trained to track mouse body parts in video, they measure the four geometric quantities at each layer. The predicted errors closely match the actual performance of simple readouts trained on those internal representations. They then turn to real brain data. Recordings from macaque visual areas show that, as signals move from the eyes through higher visual cortex, the geometry evolves in a way that reduces generalization error: correlations with latent variables increase, nuisance variability is pushed away from signal directions and certain forms of dimensionality are reshaped. In rats learning a spatial alternation task, both behavior and readout performance improve over days of training, while the geometry of hippocampal and prefrontal activity changes in systematic ways that mirror the theory’s predictions.
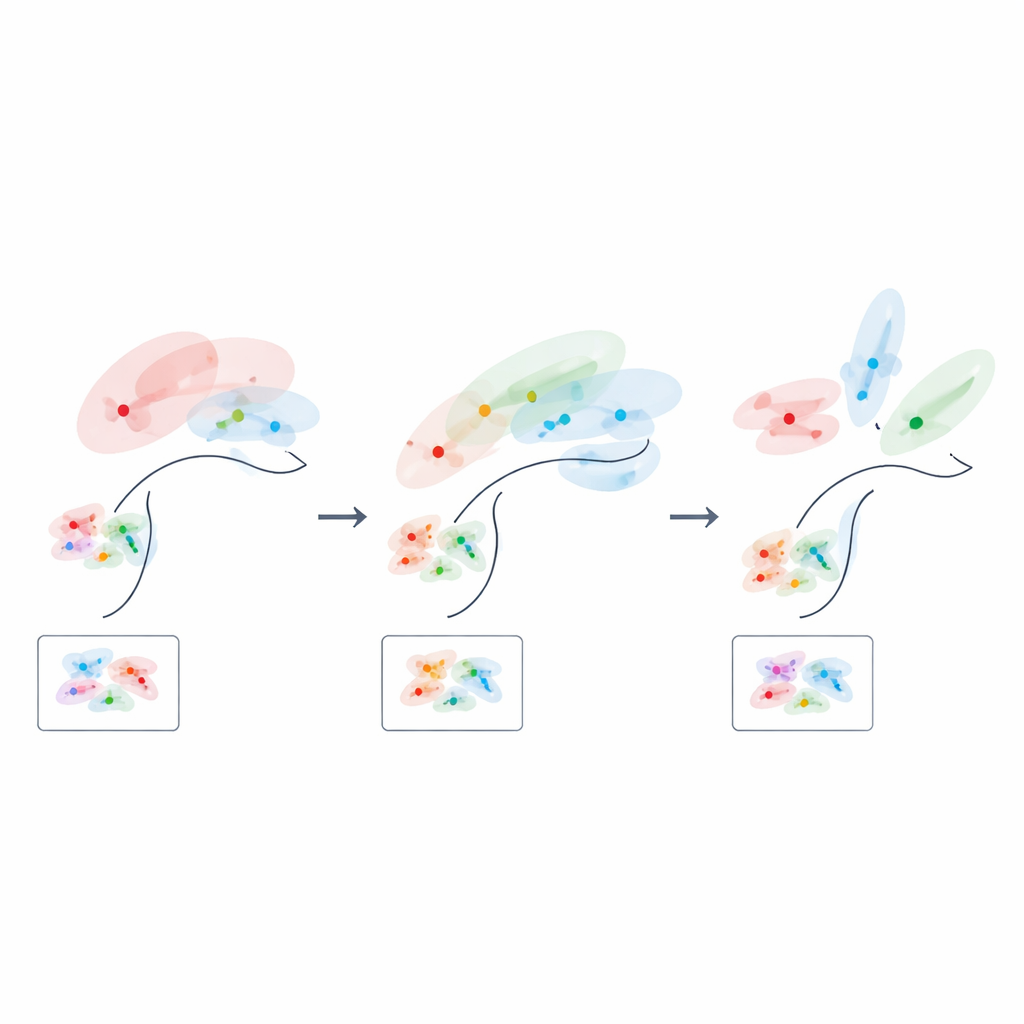
How Learning Rewrites Neural Space
Because their formula links geometry directly to performance, the authors can ask what an “optimal” neural code should look like at different stages of learning. Early on, when only a few training examples are available, the best codes are low-dimensional and strongly aligned with the most informative latent variables, effectively compressing away less useful features. As experience accumulates, the optimal solution shifts: the representation of task-relevant structure expands into more dimensions, and the tight correlation between single neurons and individual variables actually relaxes. In other words, the brain appears to start with a focused, low-dimensional sketch of the task and gradually fills in a richer, more distributed map as it learns.
Why This Matters for Understanding Brains and Machines
To a lay reader, the key message is that population brain activity is not just a tangle of spikes; it has a shape, and that shape matters. By identifying four measurable geometric features that control how well simple readouts can generalize across related tasks, this work offers a common language for comparing biological and artificial neural networks. It suggests that as animals and machines learn, they reorganize their internal activity from compact, highly aligned codes into higher-dimensional, better factorized ones that still protect task-relevant information from noise. This geometric view helps explain how the same brain circuits can flexibly reuse hidden structure across many situations, supporting the seemingly effortless generalization that underlies everyday intelligence.
Citation: Wakhloo, A.J., Slatton, W. & Chung, S. Neural population geometry and optimal coding of tasks with shared latent structure.
Nat Neurosci29, 682–692 (2026). https://doi.org/10.1038/s41593-025-02183-y
Keywords: neural population geometry, latent variable coding, multitask learning, disentangled representations, generalization in neural networks