Clear Sky Science · en
Reliability of LLMs as medical assistants for the general public: a randomized preregistered study
Why your phone might not be the best first doctor
More and more people are turning to AI chatbots for help when they feel unwell, hoping for quick answers about whether to worry, what their symptoms might mean, and whether to head to the hospital. This study asks a simple but urgent question: if ordinary people use powerful language models as medical helpers at home, do they actually make better decisions about their health—or could the technology give a false sense of security?
Testing smart machines in real-life style cases
To find out, researchers in the UK designed ten realistic medical stories, such as a sudden severe headache or trouble breathing, based on common conditions that many of us might face. A team of experienced doctors agreed on the best “next step” for each story—ranging from staying home and looking after yourself to calling an ambulance—and listed the key conditions a careful person should consider. Then 1,298 adults from across the UK were randomly assigned one of four options: use one of three leading AI chatbots, or use whatever they would normally rely on at home, such as web search or personal experience.
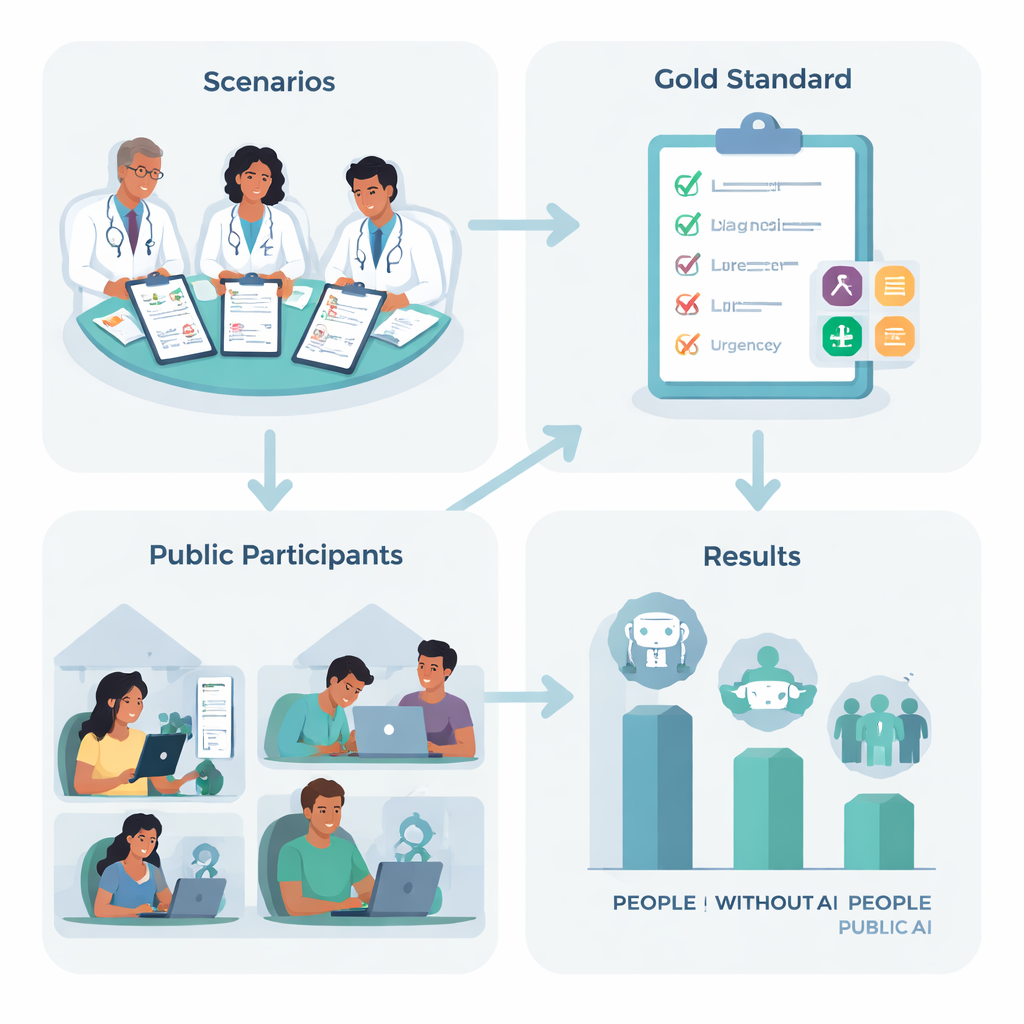
How people and machines performed—separately and together
When the language models were tested on their own, by feeding them the full case descriptions and asking directly for a diagnosis and recommended action, they did impressively well. Across the three systems, they correctly suggested at least one relevant medical condition in about 95% of cases and chose the right level of urgency more than half the time—far better than random guessing. On paper, these systems looked like strong candidates to guide worried patients.
When AI advice meets real people
But once everyday users entered the picture, the picture changed. Participants using AI were no more accurate than the control group at choosing what to do next, and they were actually worse at naming relevant underlying conditions. People in the non-AI group were about 1.8 times more likely to identify a correct condition than those using chatbots. Most participants in all groups underestimated how serious the situation was. In other words, access to an advanced language model did not help people understand their symptoms better, and it did not clearly push them toward safer choices.
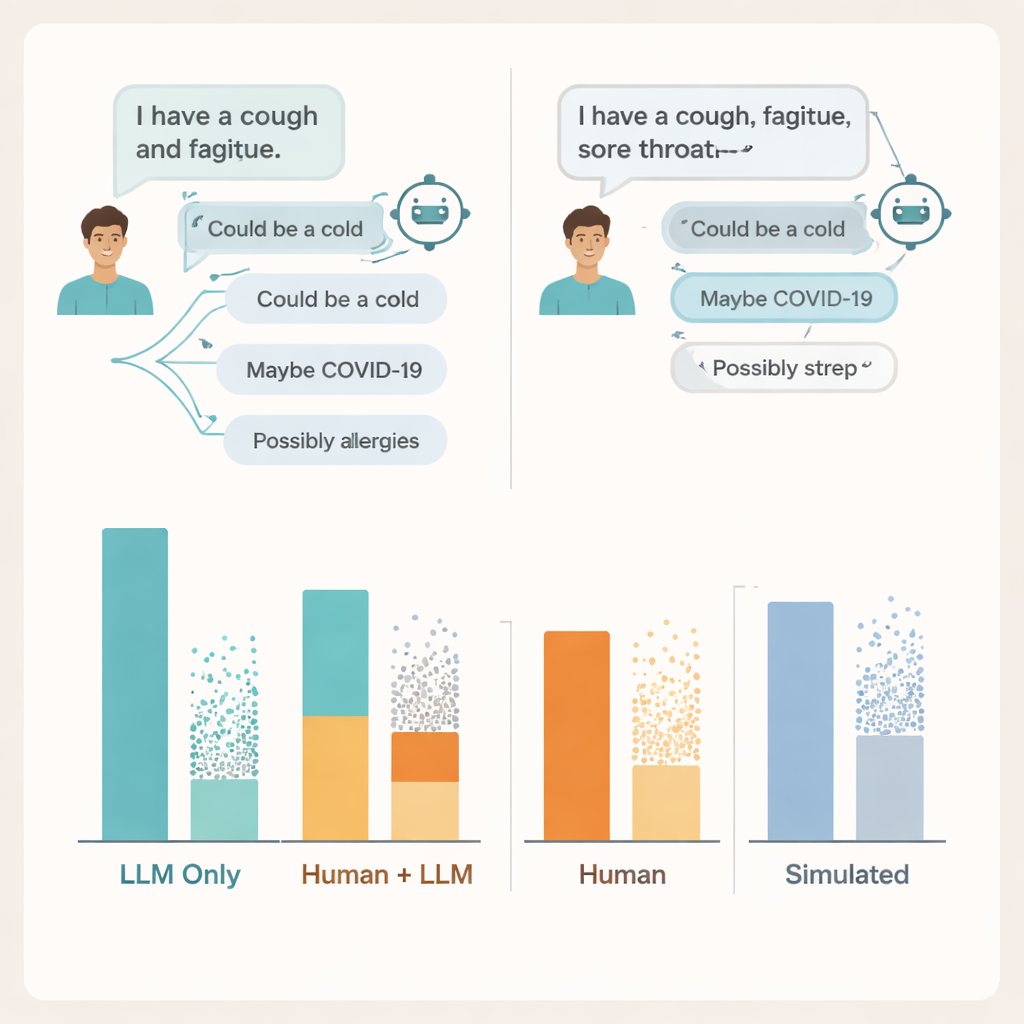
Where the conversation breaks down
To understand why, the researchers dug into the actual chat transcripts. They found problems on both sides of the conversation. Many users did not share enough detail about their symptoms for the AI to give sound advice—much as patients sometimes leave out key information when talking to a doctor. The models themselves often mentioned at least one relevant condition, but they also added several incorrect or distracting possibilities, and users struggled to tell which suggestions mattered. In some cases, nearly identical symptom descriptions led to sharply different advice from the same model, making it hard for people to form a clear sense of when to trust what they saw on screen.
Why standard tests miss the real risks
The team also compared these results with two popular ways of judging medical AIs: multiple-choice exam questions and fully simulated “patient” chats run between two models. On both, the systems again looked strong, reaching or beating typical passing scores on exam-style questions and doing better with simulated patients than with real ones. Yet high exam scores and polished simulated conversations did not line up with how well real people fared when using the same tools. Benchmarks that test knowledge in isolation, the authors argue, miss the messy, fragile nature of real human–AI interactions.
What this means for patients and health systems
For now, the study concludes, current general-purpose language models are not ready to act as unsupervised front-line advisers for the public. They clearly contain a great deal of medical knowledge, but that knowledge does not automatically translate into safer choices when anxious people type in partial, confused questions at home. Making AI genuinely helpful in high-stakes settings like healthcare will demand more than better exam scores—it will require careful design, testing with diverse real users, and stricter checks on how information is gathered, explained, and trusted in the back-and-forth of conversation.
Citation: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Keywords: medical chatbots, self-diagnosis, healthcare AI, patient decision-making, large language models