Clear Sky Science · en
Synthesizing scientific literature with retrieval-augmented language models
Why keeping up with science is so hard
Every year, millions of new scientific papers appear online. No human researcher can possibly read them all, yet important medical treatments, climate insights and technological breakthroughs may be hidden in this flood of information. This article explores whether advanced AI systems can help scientists search through this ocean of studies and weave them into clear, trustworthy summaries—without making things up.
A new kind of research assistant
The authors introduce OpenScholar, an artificial intelligence system built specifically to read and synthesize scientific literature. Unlike general chatbots, OpenScholar is tightly connected to a giant open database of about 45 million research papers, called the OpenScholar DataStore. When a scientist asks a question—such as how to cool levitated nanoparticles or which methods work best for brain imaging—the system first hunts through this database for relevant passages, then drafts an answer with inline citations, much like a human-written review article. It repeats this process several times, critiquing and refining its own drafts to improve clarity, completeness and citation quality.
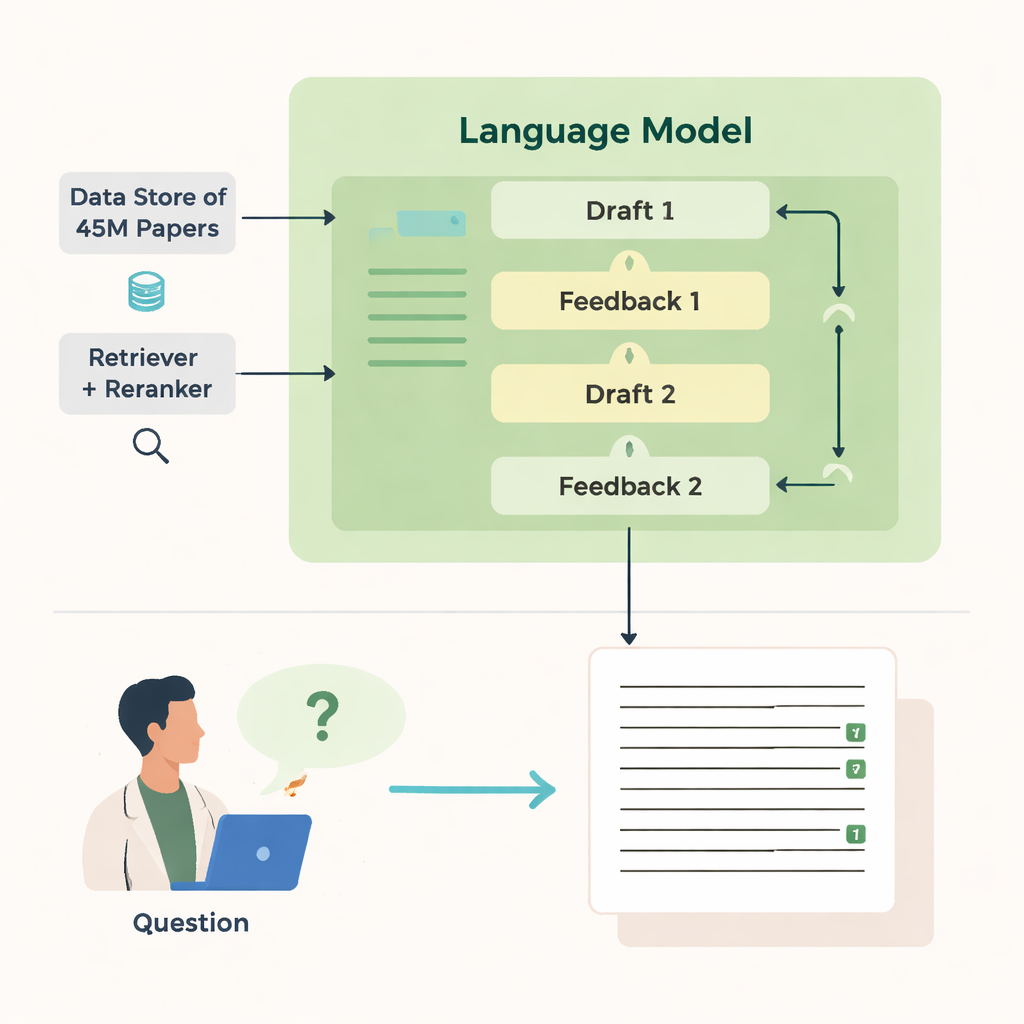
How it searches and writes
OpenScholar’s power comes from several coordinated parts. A “retriever” module scans pre-computed text embeddings from millions of articles to find promising snippets, while a “reranker” reorders these snippets to focus on the most relevant ones. The language model then uses this evidence to produce a long-form answer with numbered references. After the first draft, the model generates feedback to itself—pointing out missing perspectives, weak structure or thin evidence—and, when needed, triggers more targeted searches. It then rewrites the answer, weaving in new papers and adjusting citations. A final check ensures that statements that need support are backed by at least one retrieved source.
Putting claims and citations to the test
To see whether OpenScholar actually helps, the authors created ScholarQABench, a large benchmark designed to mimic real literature-review questions. It includes nearly 3,000 expert-written questions and hundreds of long answers across computer science, physics, neuroscience and biomedicine. Importantly, these questions usually require reading several papers, not just one abstract. The team evaluated systems along multiple axes: factual correctness, how well answers covered key points, clarity of writing and how accurately citations reflected the underlying papers. They combined automatic checks with detailed ratings from PhD-level experts who compared AI-generated answers to human-written ones.
Beating strong chatbots and matching experts
On this benchmark, OpenScholar outperformed both standard language models and earlier tools that simply tack retrieval onto a general chatbot. A compact eight-billion-parameter version, trained entirely on open data, did better on a demanding multi-paper synthesis task than GPT-4o and a competing system called PaperQA2, despite those relying on larger proprietary models. One striking finding was how often ordinary chatbots hallucinated references: in 78–90 percent of cases, their citation lists included papers that did not exist or did not support the claims. By contrast, OpenScholar’s citation accuracy rivaled that of human experts. When experts compared answers directly, they preferred OpenScholar-8B to expert-written responses about half the time, and an OpenScholar pipeline built on top of GPT-4o about 70 percent of the time, largely because the AI covered more relevant studies and organized them clearly.
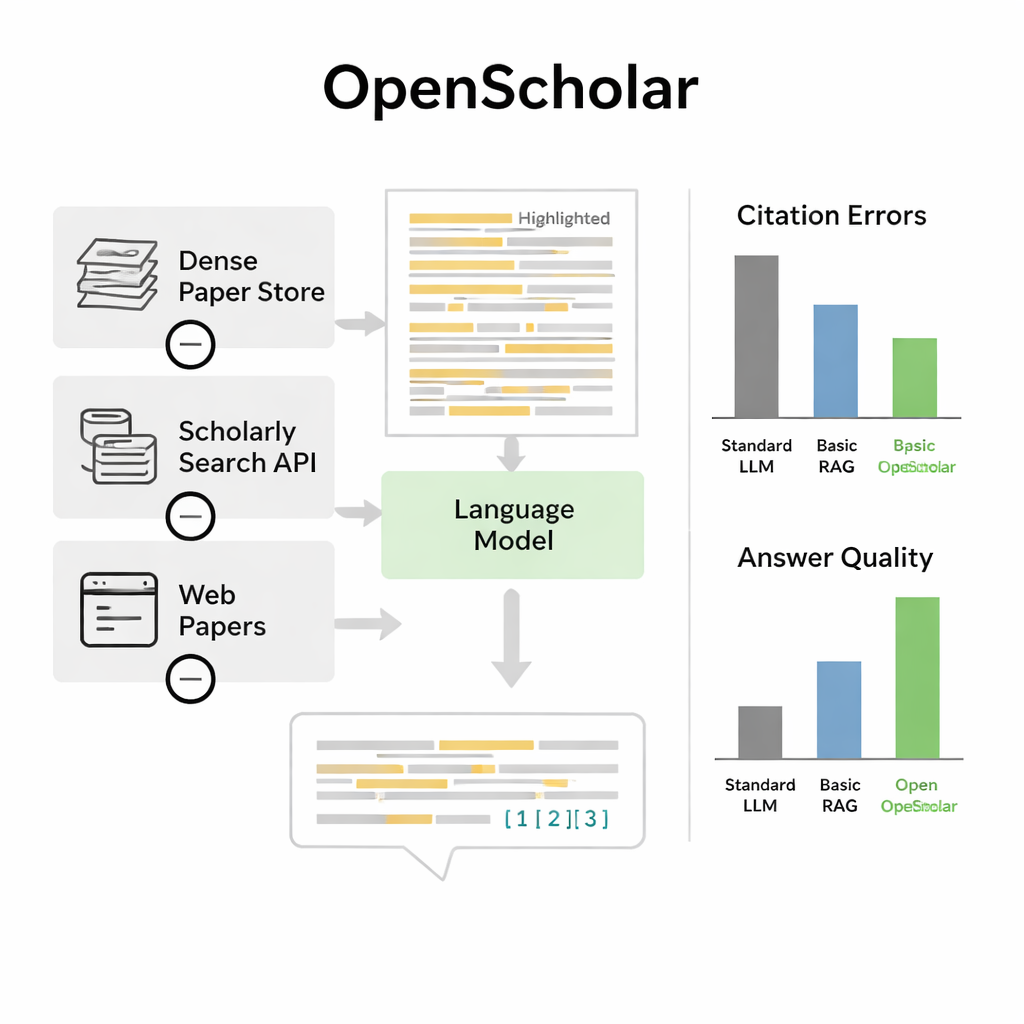
Limits and future improvements
Despite these gains, the authors emphasize that OpenScholar is not a replacement for scientists. The system can still miss the most representative papers, overemphasize less important work or introduce factual misstatements, especially in more compact models. The benchmark itself has limits too: it focuses mainly on computer science, biomedicine and physics, and the carefully annotated questions are still relatively few because expert time is expensive. Evaluations also struggle to fully capture more subtle qualities, such as whether citations highlight truly seminal work or whether an answer would actually guide a new experiment.
What this means for everyday science
For non-specialists, the main takeaway is that carefully designed AI tools can already help scientists navigate the scientific literature more effectively, provided they are tied to real data and held to strict standards for evidence and transparency. OpenScholar shows that when an AI system is built from the ground up to retrieve, check and cite real papers—and when its performance is tested against human experts—it can produce literature summaries that are not only readable but also verifiable. In practice, such tools could free researchers to focus more on designing experiments and interpreting results, while still keeping humans firmly in charge of judging what is true and important.
Citation: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Keywords: scientific literature review, retrieval-augmented language models, OpenScholar, citation accuracy, AI research tools