Clear Sky Science · en
Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics
Why the Story of Olive Oil Fraud Matters
When you pay extra for a bottle of olive oil, you expect the real thing, not a mix quietly stretched with cheaper seed oils. Yet because olive oil is valuable and global trade is complex, fraud and mislabeling are common problems. This study presents a fast, non-destructive way to spot such tricks by shining laser light on oils and letting smart computer programs read the hidden chemical fingerprints. The approach aims to help protect consumers, honest producers, and regulators by making it easier to check whether what is in the bottle matches what is on the label.
Shining Light to Read Oil Fingerprints
The researchers used a technique called Raman spectroscopy, which involves pointing a focused beam of light at a sample and measuring how the light scatters back. Different molecules vibrate in their own ways, leaving a pattern of peaks in the resulting spectrum, much like a barcode. Olive oil and common adulterants such as sunflower, rapeseed, and corn oils have different mixes of fatty acids and natural pigments, so their spectra are not identical. By studying these patterns across pure oils and carefully prepared mixtures, the team could identify a small set of “key peaks” whose shape and strength changed reliably as more or less olive oil was present in a blend.
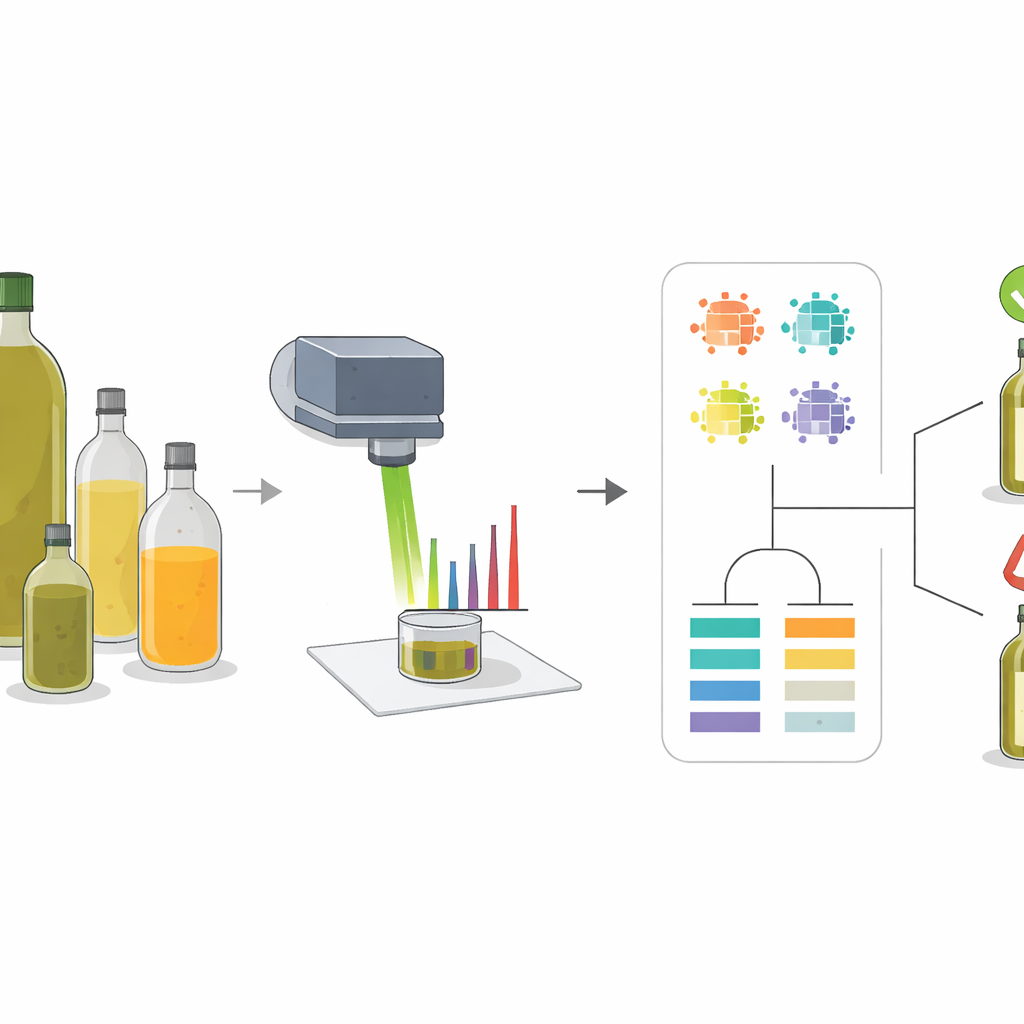
Finding the Most Telling Signals
Instead of relying on a single measurement, the team extracted several descriptors from each important peak: how tall it was (intensity), how much area it covered, how wide it was halfway up, and how its area compared with other peaks. They then used clustering and correlation maps to see how these descriptors grouped different oils and how they shifted when olive oil content increased. Peaks linked to color compounds such as beta-carotene, and to particular types of unsaturated fats, turned out to be especially informative. For example, certain peaks grew stronger as olive oil levels rose, while others faded because they were tied to linoleic acid, which is more abundant in sunflower oil. This multi-feature view captured subtle differences that would be missed if only a single intensity value were used.
Letting Algorithms Sort Honest from Adulterated
To turn these spectral fingerprints into practical decisions, the authors trained several machine learning models. First, they asked the models to classify ten oil types, including four pure oils and six kinds of binary and ternary blends. Tree-based methods—random forests and gradient-boosted trees—performed best, correctly assigning almost all samples to the right category when given the full set of peak features. Next, the same style of models was used for numerical prediction: estimating the actual percentage of olive oil in two-oil and three-oil mixtures. Again, the tree-based approaches outperformed more traditional methods, accurately tracking olive content even when signals from different oils overlapped strongly in the spectra.
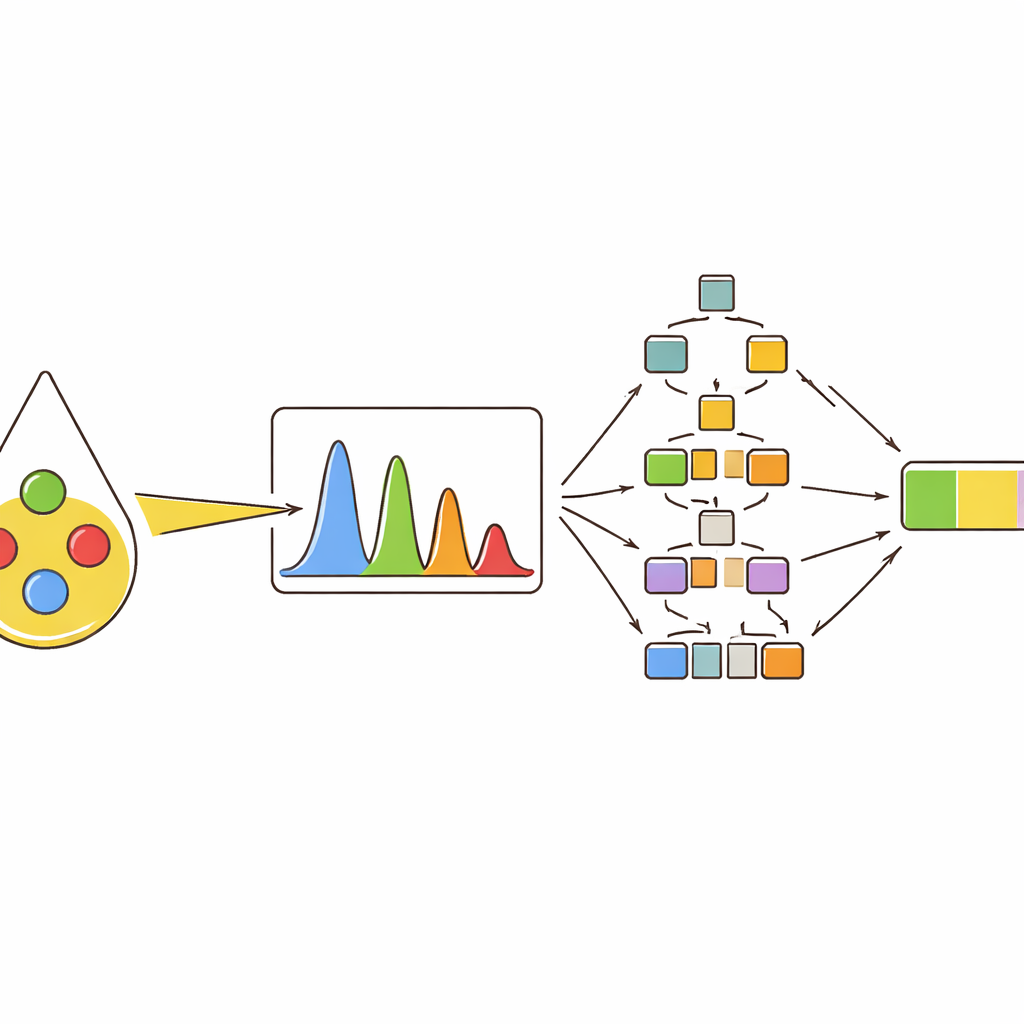
Opening the Black Box of Smart Models
Many powerful machine learning tools are hard to interpret; they may work well but offer little insight into why they made a particular decision. To tackle this, the study used an explanation method that assigns each input feature a contribution to the final prediction. This revealed that a few specific peaks dominated the models’ judgments, consistently pushing the predicted olive content up or down depending on their values. The same peaks kept appearing as most important across different blend types and in tests on commercial supermarket oils, which contained only a small amount of olive oil. For these real-world samples, the best models estimated olive content very close to the true value, supporting both the accuracy and the transparency of the approach.
What This Means for Your Bottle at Home
In everyday terms, the work shows that a quick light-based scan, interpreted by well-designed and explainable computer models, can tell whether an “olive oil” is pure, heavily diluted, or somewhere in between. By focusing on a handful of robust spectral features and combining them in advanced yet interpretable algorithms, the researchers built a tool that could be integrated into routine quality checks, potentially even in portable devices. While broader testing on more regions, varieties, and types of fraud is still needed, this framework points toward a future where verifying the honesty of high-value foods like olive oil becomes faster, easier, and more reliable for everyone.
Citation: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Keywords: olive oil authentication, food fraud detection, Raman spectroscopy, machine learning, edible oil quality