Clear Sky Science · en
Deep Gaussian process-based cost-aware batch Bayesian optimization for complex materials design campaigns
Smarter Searches for Better Materials
Designing new metals and alloys is a bit like looking for a few precious needles in a mountainous haystack. Each candidate recipe can be expensive to test in the lab or on a supercomputer, so scientists need ways to decide which few are worth exploring next. This paper introduces a strategy that treats materials discovery as a careful game of questions: it decides not only which alloy to ask about next, but also which kind of test to run and how much that test will cost. The goal is to reach top‑performing materials faster, with fewer and cheaper measurements.
Why the Search Is So Hard
Modern alloys, especially high‑entropy alloys that mix many elements in nearly equal amounts, inhabit enormous design spaces. Each composition can have many important properties, such as strength, melting point, and thermal conductivity, and these often trade off against each other. Measuring or simulating all of them for every possible recipe is impossible. Traditional Bayesian optimization methods already help by training a statistical “surrogate” that predicts properties from a limited number of examples and suggests the next experiments. But standard surrogates struggle when relationships are highly tangled, when different properties are strongly linked, or when only some properties are measured for each sample.
Layered Models That Learn Hidden Structure
To tackle this, the authors build on deep Gaussian processes, a kind of layered probabilistic model. Instead of a single smooth function, they stack several layers that gradually transform the input. Early layers learn hidden representations of alloy compositions; later layers map those hidden features to multiple properties at once. This hierarchy naturally captures effects like varying sensitivity to composition across the design space and complex links between properties. Crucially, the model also keeps track of its own uncertainty, which is vital when deciding whether it is worth paying for another measurement. Because different properties can be observed for different alloys, the model can still benefit from partial, “patchy” data and share information across tasks.
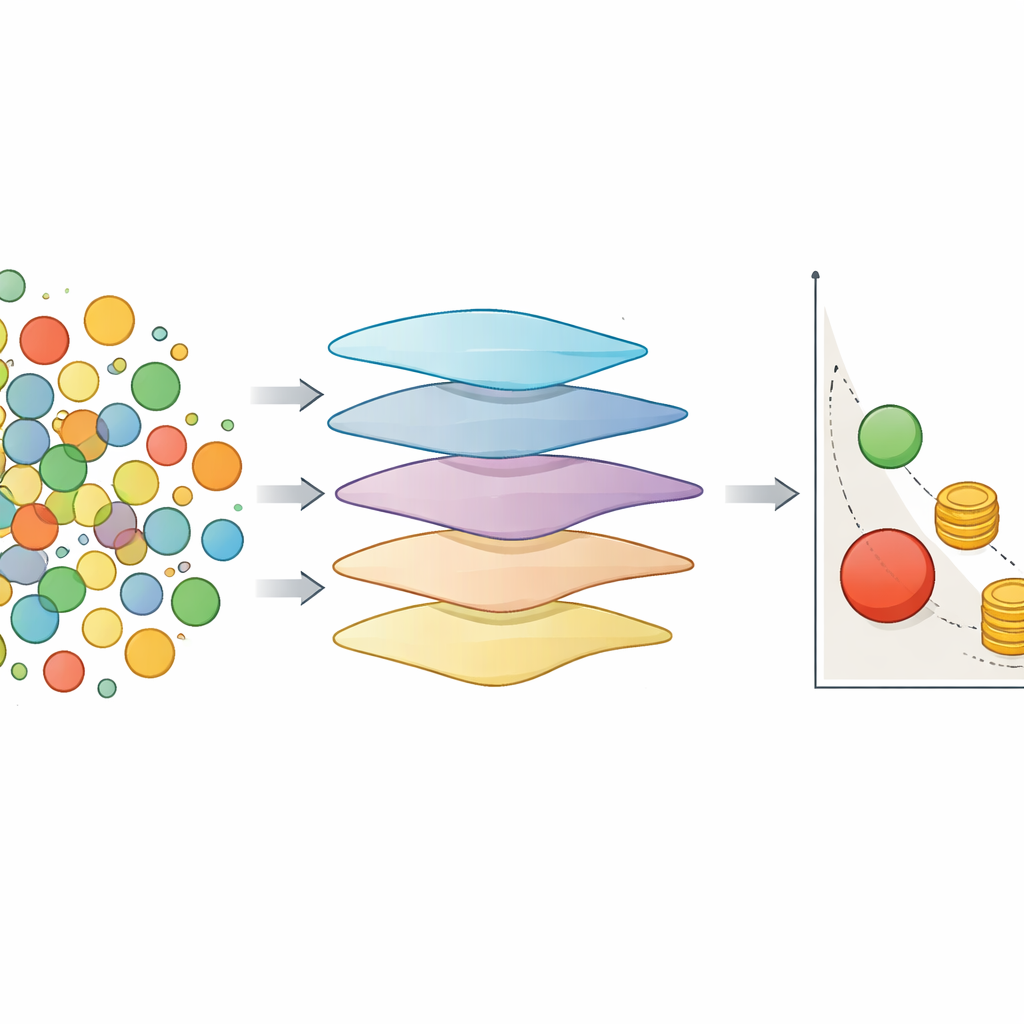
Making Each Measurement Count
The second ingredient is cost awareness. Not all measurements are equal: some, like detailed thermal conductivity or melting‑point tests, are expensive; others, like density or hardness, are cheaper. The authors extend a popular decision rule that usually focuses only on scientific gain—how much a new batch of experiments might improve the best known trade‑offs among properties. Their version divides that gain by the total cost of the proposed batch. This pushes the optimizer to favor many cheap, informative queries while reserving expensive measurements for the most promising candidates. They also mix “isotopic” batches, where all properties are measured together, with “heterotopic” steps that selectively measure only cheaper properties, using those results to refine the model before committing to high‑cost tests.
Testing on Toy Problems and Real Alloys
The team first benchmarked several variants of their approach on standard multi‑objective test problems with different shapes and difficulty levels. They compared simple single‑task models, multi‑task models that share information across properties, pure deep models, and hybrids that combine deep mean predictions with multi‑task uncertainty estimates. The results showed that no single method wins everywhere. Simple, shallow models excel on low‑dimensional, gently curved landscapes. Multi‑task models shine in high‑dimensional spaces where different objectives are tightly linked. Deep and hybrid models show their strength on highly twisted, non‑convex landscapes, where capturing intricate structure and skewed distributions matters most.
Faster Path to High‑Performance Alloys
To show practical impact, the authors then ran a fully simulated discovery campaign for refractory high‑entropy alloys intended for high‑temperature use. They explored a seven‑element composition space and tried to maximize five key properties at once, while treating two additional properties as helpful side information. Costs were assigned realistically—thermal conductivity and solidus temperature were made much more expensive than density, hardness, or a ductility indicator. The new framework was able to steer sampling toward regions of composition space that balanced multiple performance goals, while heavily reusing cheap measurements and sparingly calling on costly ones. Deep, cost‑aware strategies matched or modestly exceeded the performance of traditional methods, especially as more data accumulated, and did so with smarter use of a fixed evaluation budget.
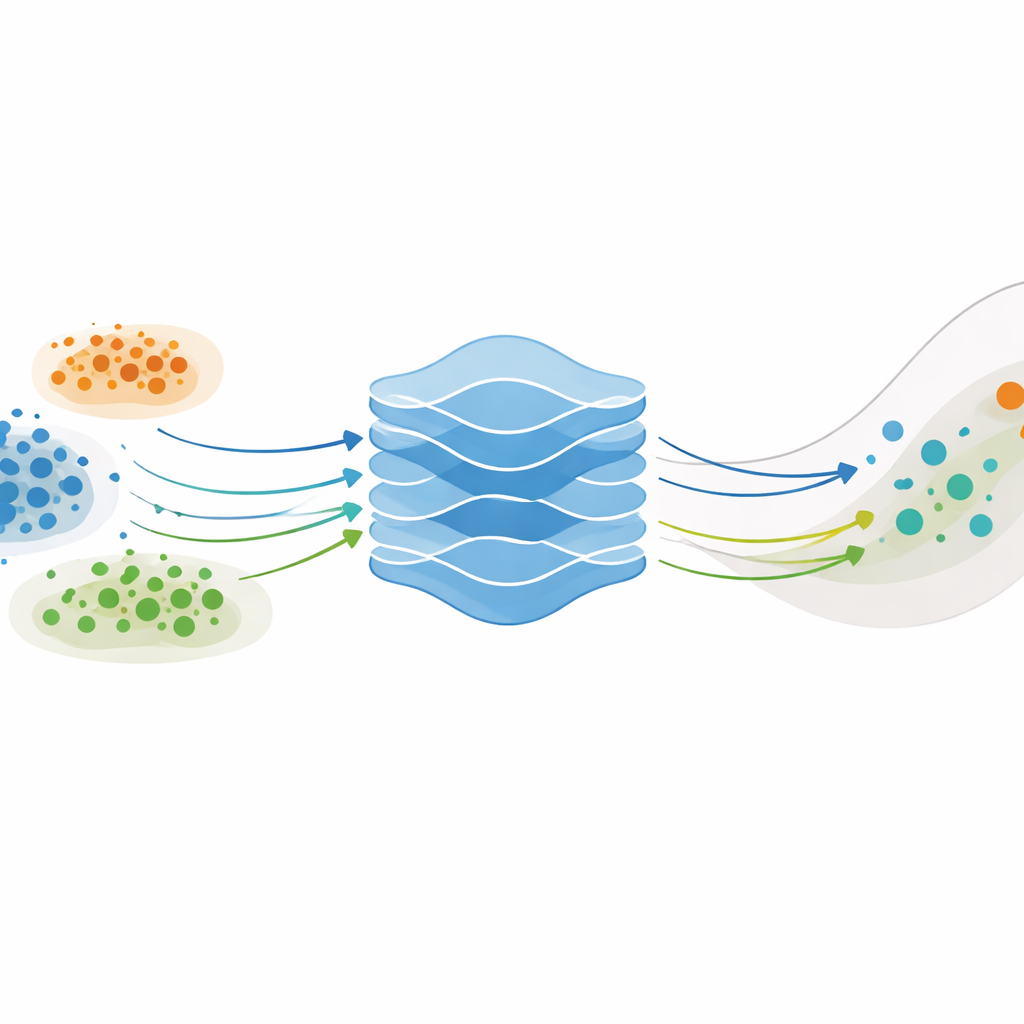
What This Means for Materials Discovery
For a non‑specialist, the main message is that this work offers a principled way to “spend” experimental and computational effort more wisely when searching for new materials. By combining layered probabilistic models that learn hidden patterns with a budgeting strategy that weighs expected scientific gain against test cost, the approach can reach high‑performing alloy designs in fewer, better‑chosen steps. While the advantages are most dramatic for complex, noisy problems, the framework lays important groundwork for future campaigns where scientists must juggle many variables, many objectives, and tight resource limits.
Citation: Alvi, S.M.A.A., Vela, B., Attari, V. et al. Deep Gaussian process-based cost-aware batch Bayesian optimization for complex materials design campaigns. npj Comput Mater 12, 105 (2026). https://doi.org/10.1038/s41524-026-01981-7
Keywords: materials discovery, Bayesian optimization, deep Gaussian processes, high-entropy alloys, cost-aware design