Clear Sky Science · en
Text mining-assisted machine learning prediction and experimental validation of emission wavelengths
Turning Scientific Text into Light
Every year, scientists publish tens of thousands of papers on materials that glow—substances used in phone screens, medical scanners, and radiation detectors. Buried in those pages are measurements of exactly what colors different materials emit, but the information is scattered, inconsistently written, and hard for computers to use. This study shows how to automatically read that literature, turn it into a large, reliable dataset, and then use machine learning to predict the color of light new materials will emit—helping researchers design better phosphors much faster.
Why Glowing Materials Matter
Phosphors are materials that absorb energy and re‑emit it as visible light. They sit at the heart of technologies such as ultra‑high‑definition displays, white LEDs, medical imaging, and radiation detection. Engineers want phosphors that shine with very specific colors, stay bright at high temperatures, and waste as little energy as possible. Over the past two decades, research on these materials has exploded, filling the scientific record with detailed reports of chemical recipes and emission wavelengths. Yet these data are mostly locked in unstructured text—phrases in paragraphs, captions, and experimental sections that are written for humans, not computers. 
Teaching Computers to Read Materials Papers
The authors built a specialized text‑mining pipeline tailored to phosphor literature. Rather than using generic language tools, they crafted rules that understand how chemists actually write formulas, especially for “doped” materials where a small amount of one element is added to a host. Their system can correctly recognize complex names like a host lattice followed by several dopant ions and their concentrations, and can link those names to nearby numbers that represent emission wavelengths. It also tackles tricky language, such as sentences that say “it emits at 630 nm” without repeating the material’s name, or paragraphs where several materials and several wavelengths are mentioned together. By classifying each sentence according to how many materials and properties it contains, and then choosing a matching algorithm for that situation, the pipeline greatly reduces mix‑ups between which number belongs to which material.
Building a Clean Map from Composition to Color
Applying this pipeline to 16,659 journal articles, the team extracted around 6,400 reliable “material–emission” pairs: a phosphor’s formula, its emission peak wavelength, the unit, and the paper’s digital identifier. Careful testing showed high accuracy both in recognizing full phosphor formulas and in linking them to the right emission values. With this structured dataset in hand, the researchers focused on one especially important family: materials doped with europium ions (Eu²⁺), which can emit across a wide swath of the visible spectrum depending on the surrounding crystal. They computed physically meaningful descriptors for each host—such as crystal structure details, bond lengths, and electronic bandgap—and then used feature‑selection methods to narrow these down to the handful that matter most for color prediction.
Letting Machine Learning Predict the Glow
Next, the authors trained and compared several machine‑learning models to predict emission wavelength from those descriptors. An algorithm called XGBoost performed best, reaching a coefficient of determination (R²) of about 0.91 on unseen test data—strong evidence that the model captures the key relationships between structure and color. To see if the approach works in the real world, they used the model to propose promising new Eu²⁺‑doped sulfide and nitride phosphors, synthesized four candidates in the lab, and measured their emission. The observed wavelengths differed from the predictions by only about 10 nanometers, meaning the model’s “guesses” were very close to experimental reality. 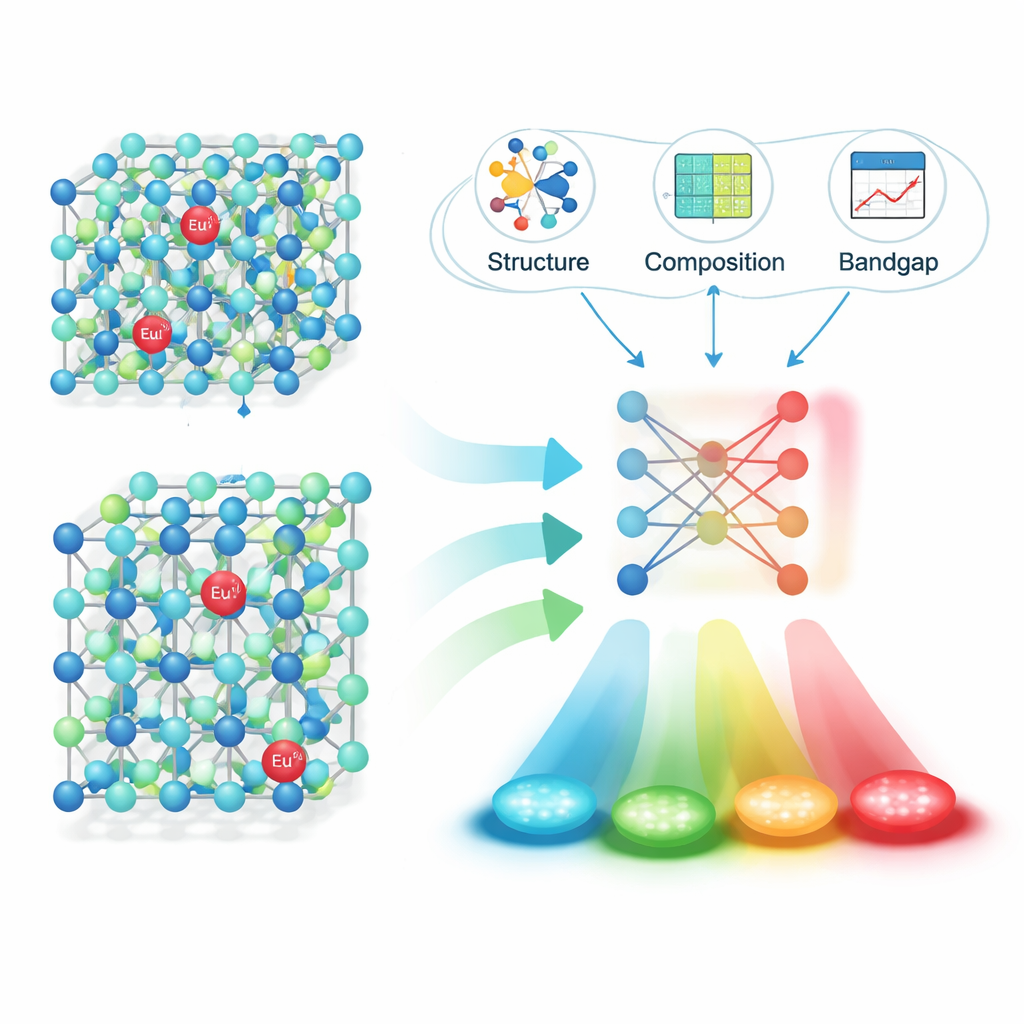
From Papers to Practical Designs
For non‑specialists, the core message is that this work turns scattered, human‑written papers into a coherent, searchable map connecting “what a material is made of” to “what color it glows.” By automating the reading, organizing, and learning steps—and then confirming predictions through real experiments—the study outlines a closed loop: text → data → model → new material. This framework can be extended to other properties such as brightness and stability, and even to other classes of functional materials. In doing so, it points toward a future where instead of trial‑and‑error lab work, scientists can rapidly home in on the most promising recipes, accelerating the development of better lighting, displays, and sensing technologies.
Citation: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Keywords: luminescent materials, text mining, machine learning, phosphors, emission wavelength prediction