Clear Sky Science · en
A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision
Why this matters for understanding vision and AI
Our eyes take in a wild variety of images every day, from forests and faces to street signs and screen noise. Yet most brain and artificial intelligence studies are built on a narrow slice of this visual world: photographs of natural scenes. This paper introduces a new kind of brain dataset that deliberately breaks out of that comfort zone, using carefully designed synthetic images to stress‑test both our theories of human vision and the AI models inspired by it.
Building a new visual test bench
The authors extend the influential Natural Scenes Dataset (NSD), which recorded ultra‑high‑resolution brain activity at 7‑Tesla MRI while people viewed tens of thousands of photographs. That original dataset has already powered some of the most accurate models of how the visual cortex responds to pictures. But because all of those images are relatively ordinary photos, it is hard to know whether a model that works well on NSD truly captures general principles of vision or has simply become specialized to that specific diet of images. To tackle this, the team scanned the same eight volunteers again, this time showing them 284 “synthetic” images that deliberately step outside the usual photo world.
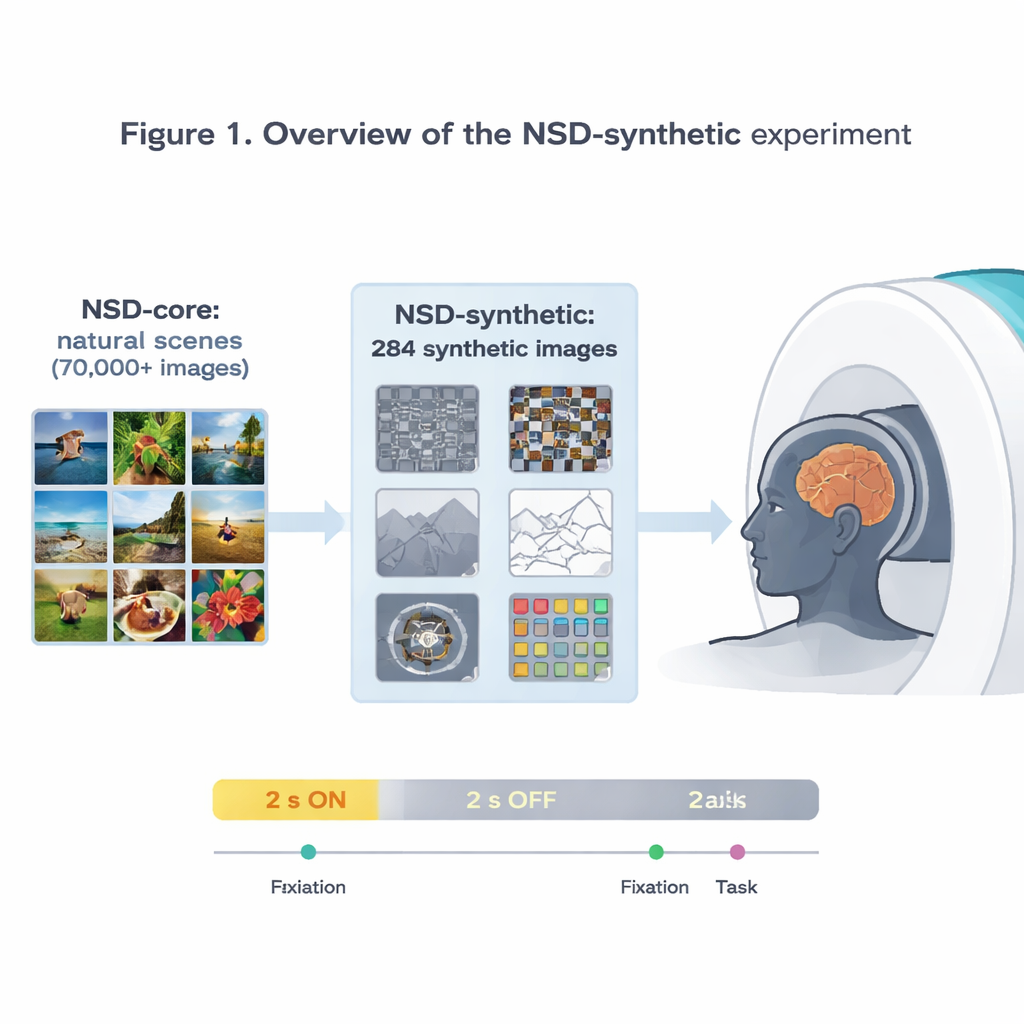
Strange images, reliable brain responses
The synthetic images span eight families: different kinds of visual noise, simple natural scenes and their altered versions (like upside‑down or line drawings), scenes with reduced contrast or scrambled phase, single words placed at various locations, spiral gratings that probe sensitivity to fine patterns, and brightly colored noise patches. While people either focused on a tiny flickering dot or performed a simple image comparison task, the researchers measured brain activity every 1.6 seconds. They show that these odd‑looking stimuli still produce strong, reliable signals, especially in early visual areas that respond to basic features like edges, contrast, and color. Patterns of activity across the cortex match well‑known preferences of specialized regions, such as a word‑selective area responding most to centrally placed words and a scene‑selective area responding most to pictures of environments.
Proving the data are truly “out of distribution”
For this new dataset to challenge models, its brain responses must be genuinely different from those evoked by natural photographs. The authors compress activity patterns from both the original NSD and the synthetic session into a two‑dimensional map that reflects how similar responses are across images. In that space, responses to synthetic images cluster separately from responses to natural photos, even when accounting for differences between scanning sessions. Moreover, synthetic images naturally group by their visual type—noise with noise, gratings with gratings, and so on—showing that the brain organizes these stimuli according to their underlying structure, not just their surface appearance.
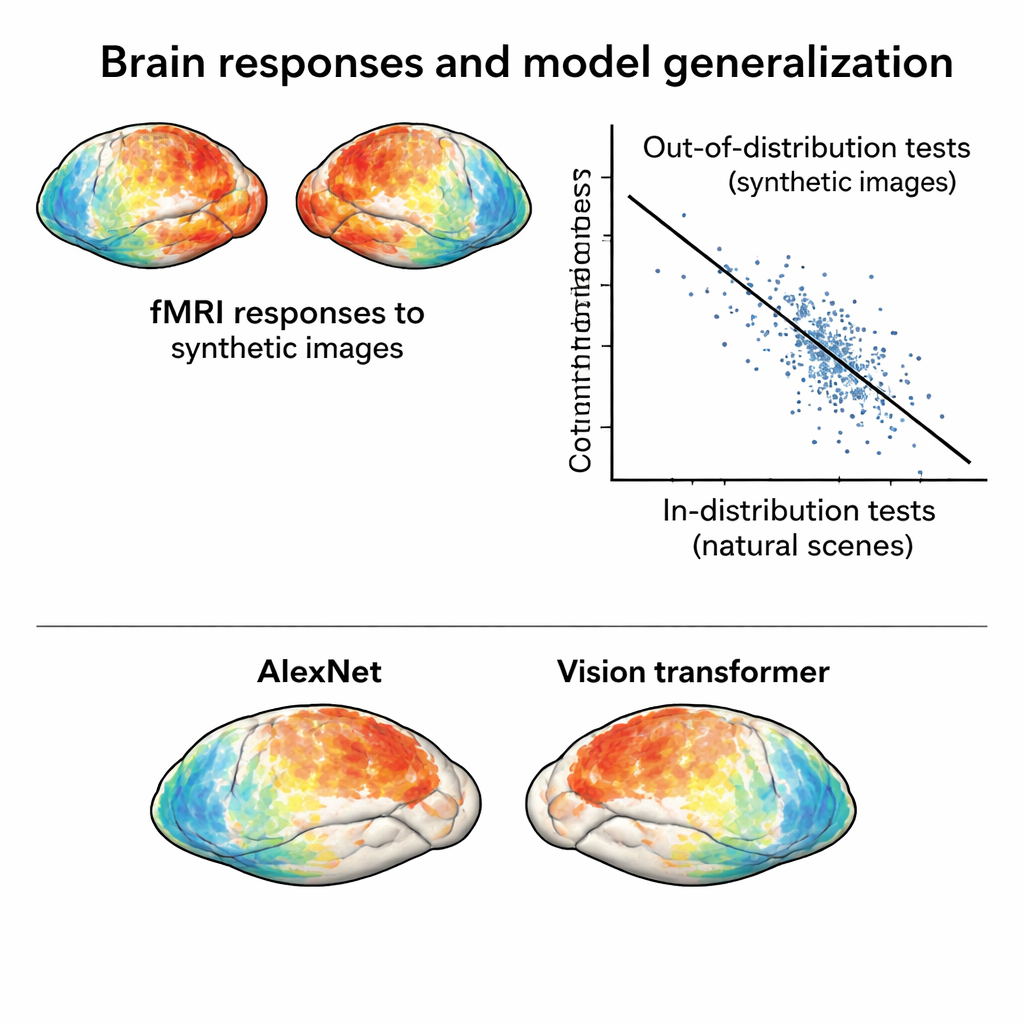
Putting brain and AI models to a tougher test
With this new “out‑of‑distribution” dataset in hand, the team trains standard encoding models: mathematical tools that predict brain responses from image features extracted by deep neural networks. Models trained only on the natural photos perform well when tested on similar photos, but their accuracy drops markedly when predicting responses to the synthetic images. That drop is not due to noisy data—the synthetic responses are actually very clean—but to real model failures. Crucially, comparing different neural network architectures under these harsher conditions reveals contrasts that barely show up on in‑distribution tests. For example, a modern vision transformer and a self‑supervised network both outperform classic convolutional networks when faced with synthetic images, suggesting that how a model is trained strongly shapes its robustness.
How far from familiar images can models go?
The authors go further and treat “distance” from the training data as a continuum, not a yes‑or‑no label. They measure how far each image’s brain response lies from the cloud of responses to natural scenes. The farther away a synthetic image is in this space, the worse models tend to perform and the less accurately they can be used to identify which image a person saw based on brain activity alone. They also show that even within the world of ordinary photographs, cleverly chosen test sets can behave as “mildly out of distribution”: models do best on images drawn from the same cluster as their training set, less well on distant natural scenes, and worst on the synthetic stimuli. This graded picture turns the new dataset into a tool for probing exactly which kinds of visual structure current models miss.
What this means for future brain and AI research
For non‑specialists, the key message is that strong performance on familiar pictures does not guarantee that a brain‑inspired AI model has truly captured how we see. By releasing NSD‑synthetic alongside the original NSD, the authors provide a public “crash test track” for vision models: a way to see where they break when the images become more abstract, more colorful, or less natural. Because the dataset is openly available and tightly integrated with an existing, widely used resource, it is likely to become a standard benchmark for testing and improving theories of human vision and the artificial networks that aim to mimic it.
Citation: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Keywords: visual cortex, fMRI dataset, synthetic images, out-of-distribution, deep neural networks