Clear Sky Science · en
Uncovering Cas9 PAM diversity through metagenomic mining and machine learning
Why this matters for future gene editing
CRISPR has become a symbol of modern gene editing, yet one quiet rule still limits what it can do: every cut in DNA must sit next to a short “permission slip” sequence. These short patterns, called PAMs, decide where the popular Cas9 enzyme can and cannot work. This study shows how trawling through vast amounts of microbial DNA, combined with advanced machine learning, can reveal an enormous hidden variety of these permission slips. That new map could open up many more spots in the human genome to precise, safer therapies.
Hidden rules that guide CRISPR cuts
Cas9 and related enzymes are part of a natural immune system found in bacteria and archaea. To avoid cutting their own DNA, these microbes make Cas proteins look for a PAM—a very short stretch of letters—next to the target site. Only when that PAM is present will Cas9 unwind the DNA and let its guide RNA check for a match, triggering a cut if everything lines up. The catch for medicine is that common lab workhorses, such as the standard Cas9 from Streptococcus pyogenes, recognize only narrow PAM patterns. If a disease-causing mutation lacks the right nearby sequence, today’s tools simply cannot reach it without sacrificing accuracy.
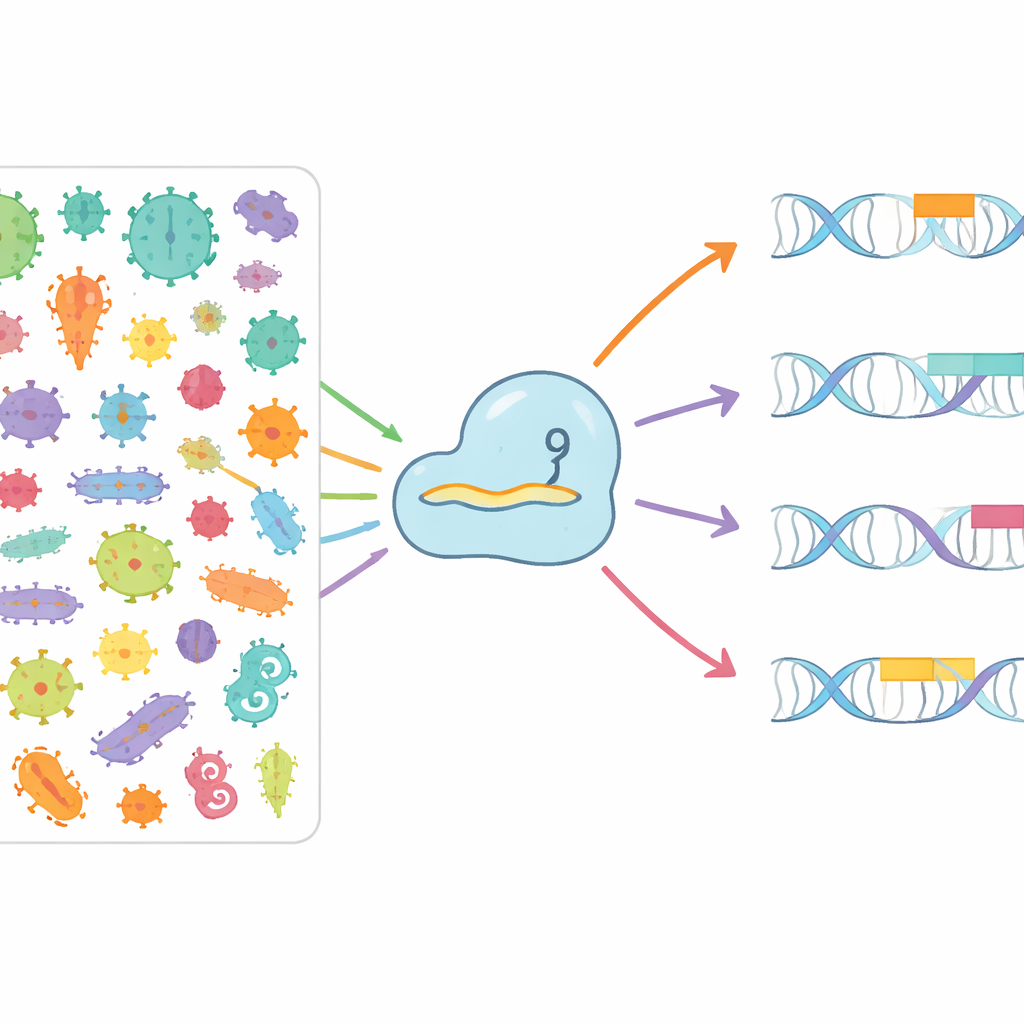
Mining the microbial world for new options
The authors set out to systematically chart how different Cas9 proteins recognize different PAMs in nature. They combed through more than 3.8 million bacterial and archaeal genomes, and over 7.4 million viral and plasmid sequences that infect or move between microbes. By identifying CRISPR arrays, linking them to nearby Cas9 genes, and then matching the stored “memory” spacers against invading viruses and plasmids, they could see which short DNA patterns tended to flank real targets. From this they built CRISPR-PAMdb, a public catalog containing 8003 Cas9 groups, each paired with a consensus PAM profile, and organized them on an evolutionary tree that highlights how closely related Cas9 enzymes tend to share similar PAM preferences while still showing striking overall diversity.
When data run out, let the model learn
Even with this enormous survey, most Cas9 proteins they found lacked enough matching viral targets to read out a PAM directly. To fill in the gaps, the team built a machine learning model called CICERO. CICERO uses a powerful protein “language model” that has learned general patterns of amino-acid sequences and fine-tunes it to predict, for any given Cas9 protein, how likely each DNA letter is to appear at each of ten positions in the PAM. The model was trained on the PAM profiles from CRISPR-PAMdb and then tested both by cross-validation and on 79 Cas9 enzymes whose PAMs had been measured experimentally, achieving strong agreement between prediction and reality.
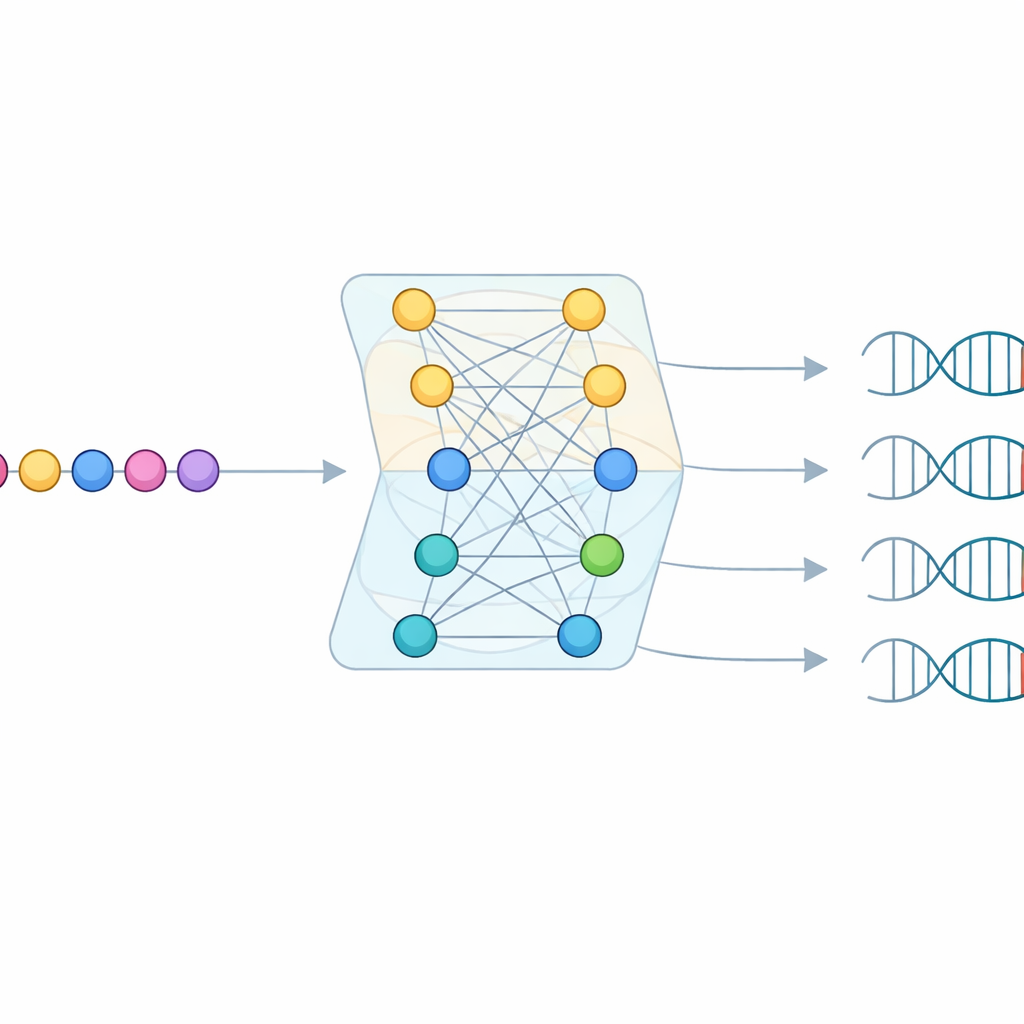
Knowing how confident to be
A key feature of CICERO is that it does not just guess a PAM—it also estimates how trustworthy each guess is. After learning to predict PAM patterns, the researchers trained a second, lightweight network that takes the same Cas9 sequence and learns to forecast how accurate the PAM prediction will be. Higher confidence scores strongly tracked with higher real-world accuracy. Using this confidence filter, the team extended PAM annotations to more than 50,000 additional Cas9 proteins, with over 17,000 predictions classified as high confidence. This greatly broadens the menu of Cas9 variants with reasonably well-understood targeting rules.
What this means for treating genetic disease
To show why these new resources matter, the authors examined tens of thousands of disease-linked single-letter mutations in the ClinVar database that could, in principle, be corrected using base editors—tools that change one DNA letter without cutting both strands. They found that the standard Cas9 enzyme can only access about half of such sites because of its strict PAM demands. When they allowed Cas9 relatives from CRISPR-PAMdb and high-confidence CICERO predictions that recognize a wider but still specific set of nearby sequences, nearly all of these mutations became theoretically reachable without relaxing targeting so much that precision would be lost.
A larger toolbox for precise DNA surgery
In plain terms, this work builds two things: a giant, public map linking thousands of natural Cas9 proteins to the short DNA patterns they prefer, and an AI guide that can predict those preferences for many more enzymes simply from their sequences. Together, they turn the microbial world into a rich parts library for future gene editors. As researchers refine and test these Cas9 variants in the lab, clinicians may gain safer, more versatile tools that can reach disease-causing mutations that were previously out of bounds, bringing truly precise genome surgery a step closer to reality.
Citation: Fang, T., Bogensperger, L., Feer, L. et al. Uncovering Cas9 PAM diversity through metagenomic mining and machine learning. Nat Commun 17, 2510 (2026). https://doi.org/10.1038/s41467-026-69098-5
Keywords: CRISPR-Cas9, PAM diversity, metagenomics, machine learning, genome editing