Clear Sky Science · en
Computational single-neuron mechanisms of visual object coding in the human temporal lobe
How the Brain Knows What We’re Looking At
Every time you glance at a crowded street, your brain instantly tells you which shapes are people, which are cars and which are signs, even if they’re partly hidden or oddly lit. This paper asks a deceptively simple question: how does the human brain turn the flood of raw visual detail hitting our eyes into stable ideas like “dog” or “cup” that we can recognize, remember and talk about?
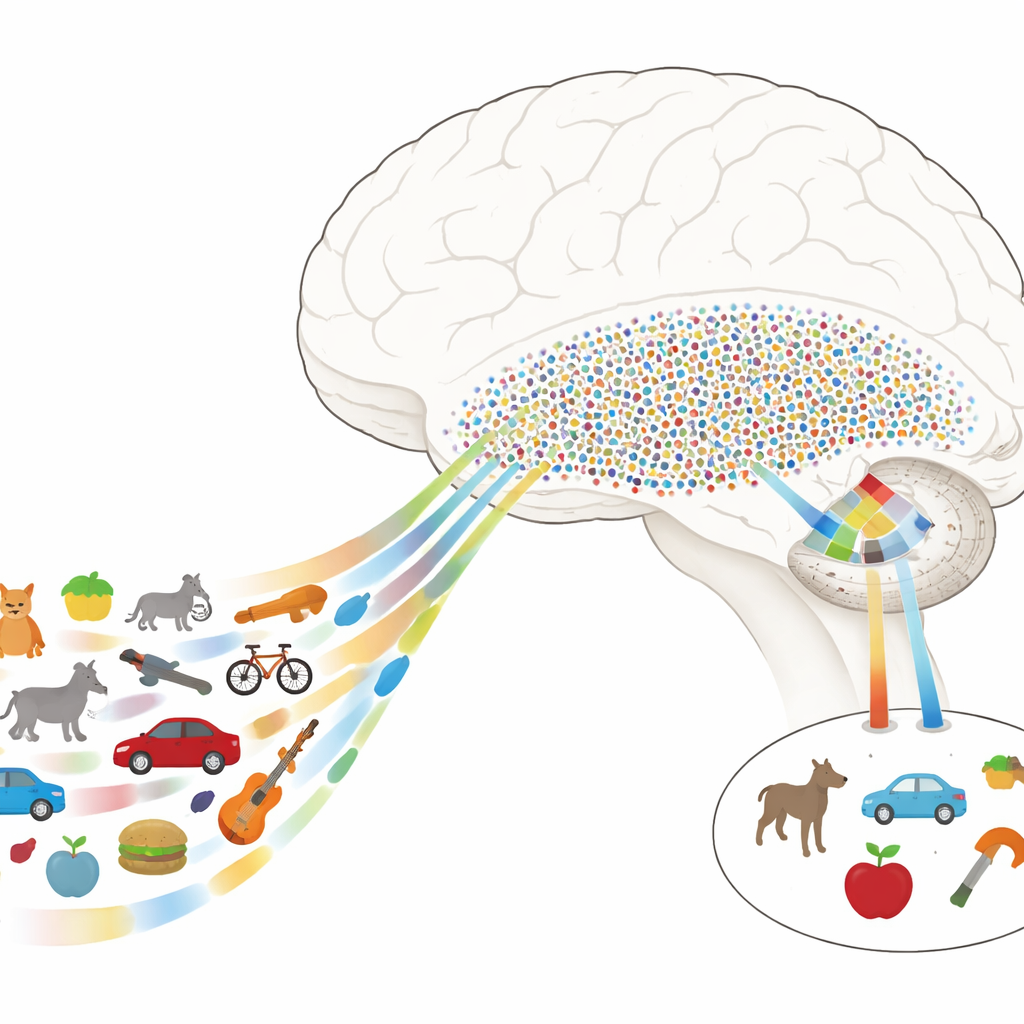
From Detailed Pictures to Meaningful Things
Scientists know that object recognition relies heavily on a chain of regions on the underside of the brain called the ventral visual pathway. Early stages deal with simple features such as edges and textures, while later stages care more about whole objects and their meaning. In humans, a key stretch of this pathway is the ventral temporal cortex (VTC), and just downstream sits the medial temporal lobe (MTL), which is crucial for memory. The mystery has been how the brain moves from the VTC’s detailed, picture-like descriptions of what we see to the MTL’s sparse, concept-like codes that let a few neurons stand in for many different views of the same object.
A Neural Map of Object Space
The authors recorded electrical activity directly from the brains of epilepsy patients who already had electrodes implanted for medical reasons. While patients performed a simple task, they viewed hundreds of natural images drawn from many categories—animals, tools, foods, vehicles, plants and more. In VTC, the researchers found that responses could be described as combinations of a few key feature directions, or “axes,” such as how natural versus man-made something looks, or how animate versus inanimate it is. By mathematically combining these axes, they built a “neural feature space” in which each image occupies a location, and similar objects cluster together even if they differ in low-level details.
From Dense Feature Grids to Sparse Concept Hubs
In this neural feature space, VTC acts like a dense grid: many sites participate in representing each object, encoding fine-grained visual differences. In contrast, neurons recorded one by one in the MTL behaved very differently. Instead of tracking individual features, many of these cells responded strongly only to objects falling within particular regions of the VTC feature space. Each such neuron effectively had a “receptive field” not in physical space, but in this abstract map of object properties. Objects that landed inside a neuron’s preferred region often shared both perceptual traits (for example, rounded shapes or greenish colors) and higher-level meanings (such as being living things or tools), leading that neuron to fire sparsely yet selectively.
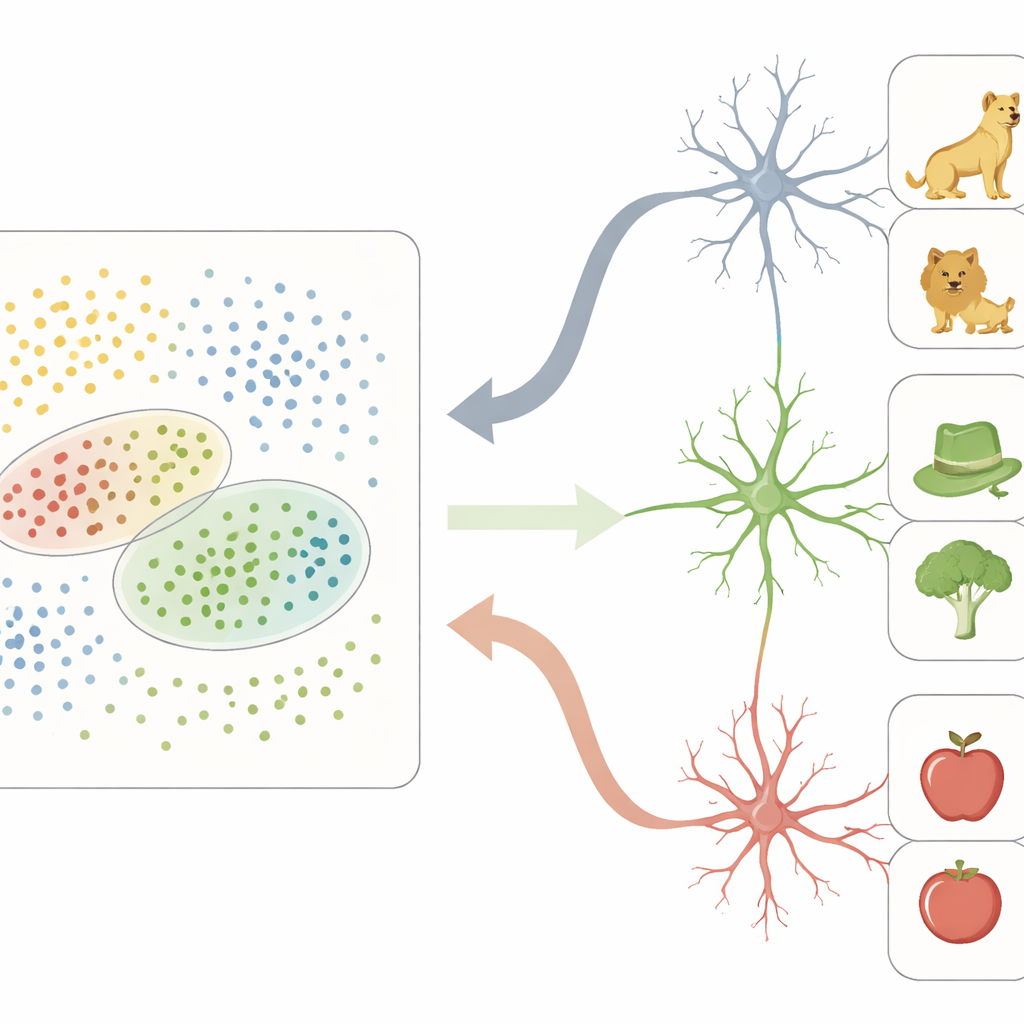
Wiring Together Vision and Memory
To show that this is not just a mathematical trick, the team looked at how these brain areas interact in real time. They found that VTC sites carrying strong feature-axis signals were especially synchronized with category-sensitive sites in the MTL, particularly in certain rhythmic brain waves. Information tended to flow from VTC to MTL in lower frequencies associated with feedforward processing, while feedback from MTL to VTC rode on slightly higher frequencies. Crucially, when an MTL neuron was tuned to a specific region of feature space, its spikes aligned with fast rhythms in the VTC, and this coupling was stronger for the very images that neuron encoded. A second set of experiments using a different image collection confirmed that both the VTC feature map and MTL region tuning were stable across stimulus sets.
Why This Matters for Everyday Seeing and Remembering
Together, these results support a concrete computational story: the VTC spreads out visual objects along meaningful feature axes, forming a rich, continuous landscape, and the MTL places small, selective “pointers” onto regions of this landscape. This transformation turns a detailed, distributed picture-code into a sparse concept-code that is easier to store, retrieve and combine with other memories. For a non-specialist, the takeaway is that recognizing a dog on a rainy night is not a simple lookup, but the result of a layered, cooperative process in which one part of the brain builds a structured map of appearances and another part learns to mark and read off regions of that map as distinct, enduring ideas.
Citation: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Keywords: object recognition, ventral temporal cortex, medial temporal lobe, neural coding, visual memory