Clear Sky Science · en
In-memory analog computing for non-negative matrix factorization
Why breaking big data into parts matters
Everyday services like movie recommendations, photo apps, and genetic analysis all rely on finding patterns hidden inside huge tables of numbers. A popular way to do this is called non‑negative matrix factorization, which breaks a large data table into simpler building blocks that are easier to interpret. But as data sets grow to millions of users, items, or pixels, today’s digital chips can struggle to keep up in real time. This paper shows how an analog, in‑memory computing approach can perform this heavy mathematical lifting far faster and with far less energy, opening the door to more responsive and efficient AI‑driven services.
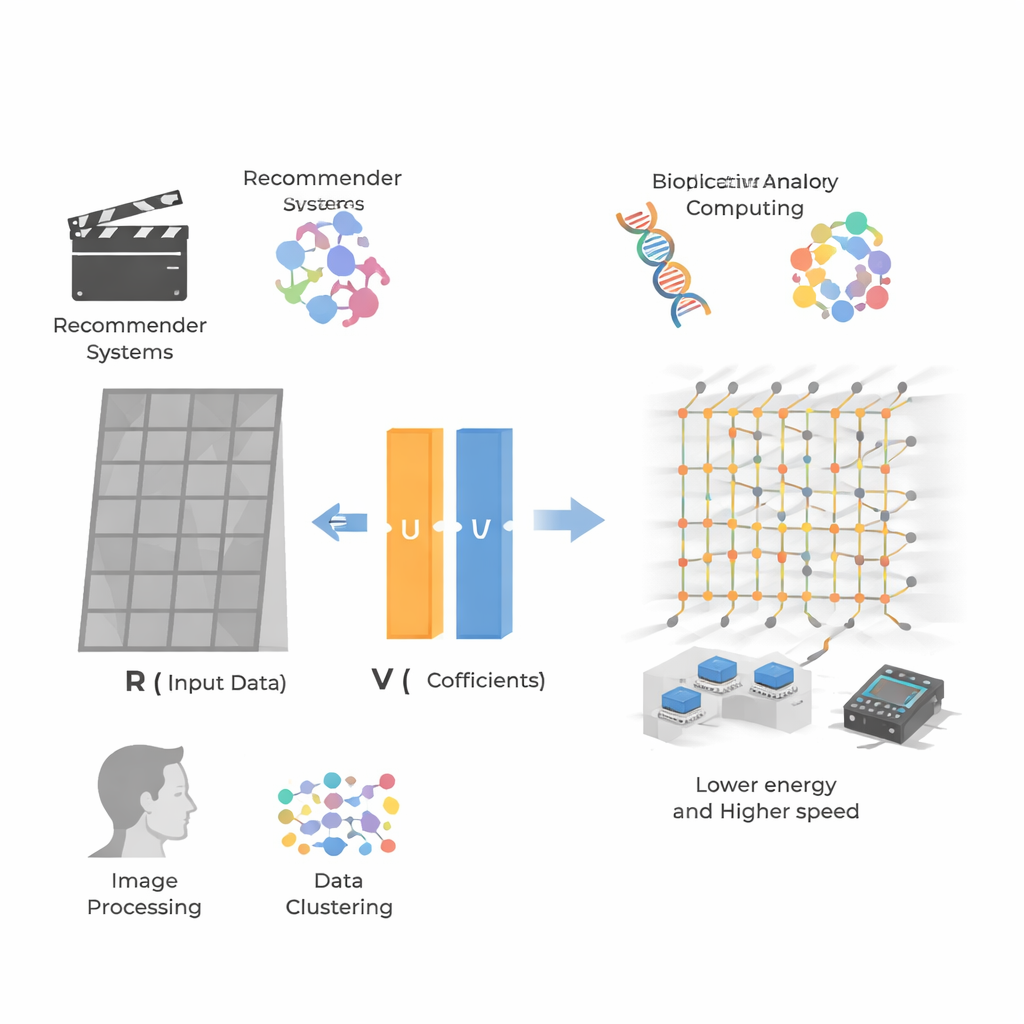
Pulling patterns out of giant tables
At the heart of the work is non‑negative matrix factorization (NMF), a method that takes a big grid of non‑negative numbers—such as user–movie ratings or image pixel values—and rewrites it as the product of two smaller grids. One grid represents hidden “features” (for example, a user’s taste for action versus romance), and the other represents how strongly each item or pixel exhibits those features. Because all values stay non‑negative, these features tend to look like intuitive parts: facial components in images, or preference profiles in recommendation data. This makes NMF popular in recommendation systems, bioinformatics, image processing, and clustering, but also makes it computationally demanding for very large, sparse data sets.
Why digital chips hit a wall
Traditional processors—CPUs, GPUs, and even FPGAs—treat matrix operations as long sequences of basic steps, moving data back and forth between memory and computing units. For modest problems this works well, but for modern data sets with millions of rows and columns the cost in time and energy becomes enormous. The slowdown of Moore’s law and the so‑called von Neumann bottleneck, where memory access dominates power and delay, make it increasingly difficult to scale NMF to real‑time applications such as live recommendation or fast image analysis. Even clever digital algorithms still face polynomial‑time complexity and heavy memory traffic whenever matrices must be repeatedly updated.
Computing inside memory with analog signals
The authors take a different route by using analog matrix computing based on resistive memory devices known as memristors. These devices can be arranged in dense crossbar arrays where each junction stores a conductance value. When voltages are applied along one side of the array, currents flowing out along the other side naturally perform many multiply‑and‑add operations in parallel. By wiring these arrays in a closed loop with a small number of operational amplifiers, the team builds a compact generalized inverse (GINV) circuit that solves whole regression problems in essentially one analog step, rather than in many digital iterations. They refine the design with a conductance compensation scheme that keeps the circuit stable while sharply reducing the number of amplifiers, saving chip area and power.
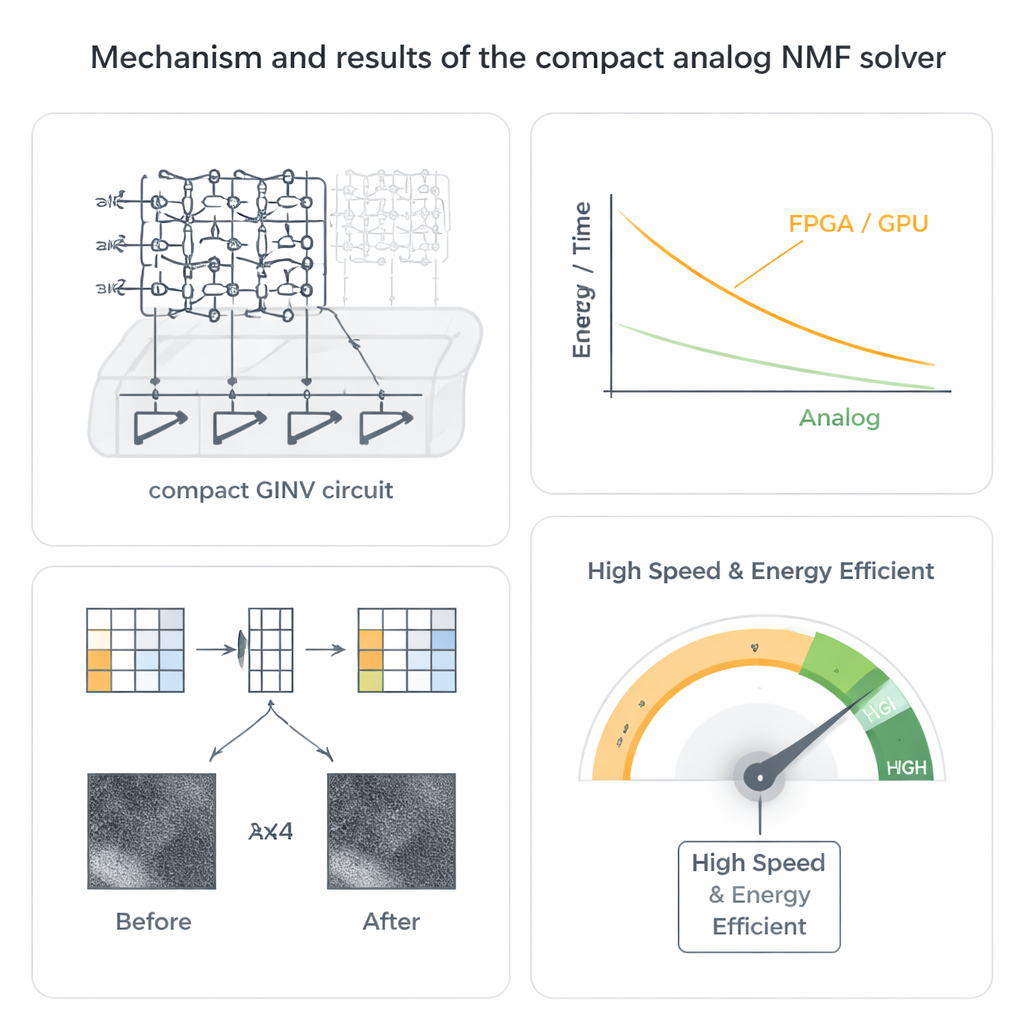
From math trick to working hardware
To make this practical for NMF, the researchers pair their compact GINV circuit with a well‑known strategy called alternating non‑negative least squares. Instead of trying to solve for both factor matrices at once—a difficult non‑convex problem—the method alternately improves one matrix while holding the other fixed, breaking the task into a chain of simpler non‑negative regression problems that the analog circuit can solve. They fabricate hafnium‑oxide memristor arrays and build a printed circuit board platform, then demonstrate two key applications. For image compression, a nebula photograph is split into small patches that are factorized, halving the storage while reproducing the image with only a tiny loss in visual quality. For recommender systems, they factorize user–item rating data such as the MovieLens 100k set, accurately predicting missing ratings even though the matrix is extremely sparse.
Speed, efficiency, and robustness in the real world
Beyond basic correctness, the analog solver shows remarkable speed and energy advantages. Because current through the crossbar represents many operations done at once, the time to solve a regression problem becomes almost independent of matrix size, in sharp contrast to digital methods. System‑level estimates suggest speedups ranging from hundreds to thousands of times over advanced FPGA and GPU implementations, along with improvements of several orders of magnitude in energy efficiency. Perhaps surprisingly, the analog nature of the hardware is not a weakness but a strength: the NMF algorithm naturally tolerates device noise and programming errors, and in simulations the final image and recommendation quality remain high even when the underlying memristor values are quite imprecise or drift with temperature.
What this means for everyday technology
In simple terms, the study shows that a new kind of “calculator in memory” can handle one of the workhorse tools of modern data science much faster and more efficiently than today’s digital chips. By embedding matrix factorization directly into compact analog circuits, services like streaming recommendations, personalized content ranking, and on‑device image processing could eventually run in real time while consuming far less power. The work provides both a circuit blueprint and experimental proof that such analog in‑memory computing can tackle realistic data sets with accuracy close to full‑precision software, pointing toward future hardware that can sift through massive data streams as effortlessly as light passing through glass.
Citation: Wang, S., Luo, Y., Zuo, P. et al. In-memory analog computing for non-negative matrix factorization. Nat Commun 17, 1881 (2026). https://doi.org/10.1038/s41467-026-68609-8
Keywords: analog in-memory computing, non-negative matrix factorization, memristor crossbar, image compression, recommender systems