Clear Sky Science · en
On the fundamental resource for exponential advantage in quantum channel learning
Why this matters for future quantum computers
As quantum computers grow, one of the hardest challenges is figuring out exactly how these fragile machines behave and where their errors come from. This paper asks a deceptively simple question: when we use quantum tricks to learn about an unknown device, what, exactly, is the special resource that gives us an exponential speed‑up over any classical method? The answer turns out to be more subtle than "just add more entanglement," and that has practical consequences for how we design next‑generation quantum hardware and experiments.
Two different quantum helpers
Scientists have long known that giving an experimenter access to a quantum memory can dramatically reduce the number of times they need to probe an unknown quantum process, such as the noisy behavior of a quantum chip. In this setting, there are two distinct resources hiding inside the vague phrase "quantum memory." One is the number of extra qubits, called ancilla qubits, that can be stored alongside the system being tested. The other is entanglement, the uniquely quantum linkage between those ancilla qubits and the system. Earlier work tended to blur these together: using large entangled states that naturally require many ancilla qubits. This paper teases them apart and asks how each resource, by itself, affects how many experimental shots are needed.
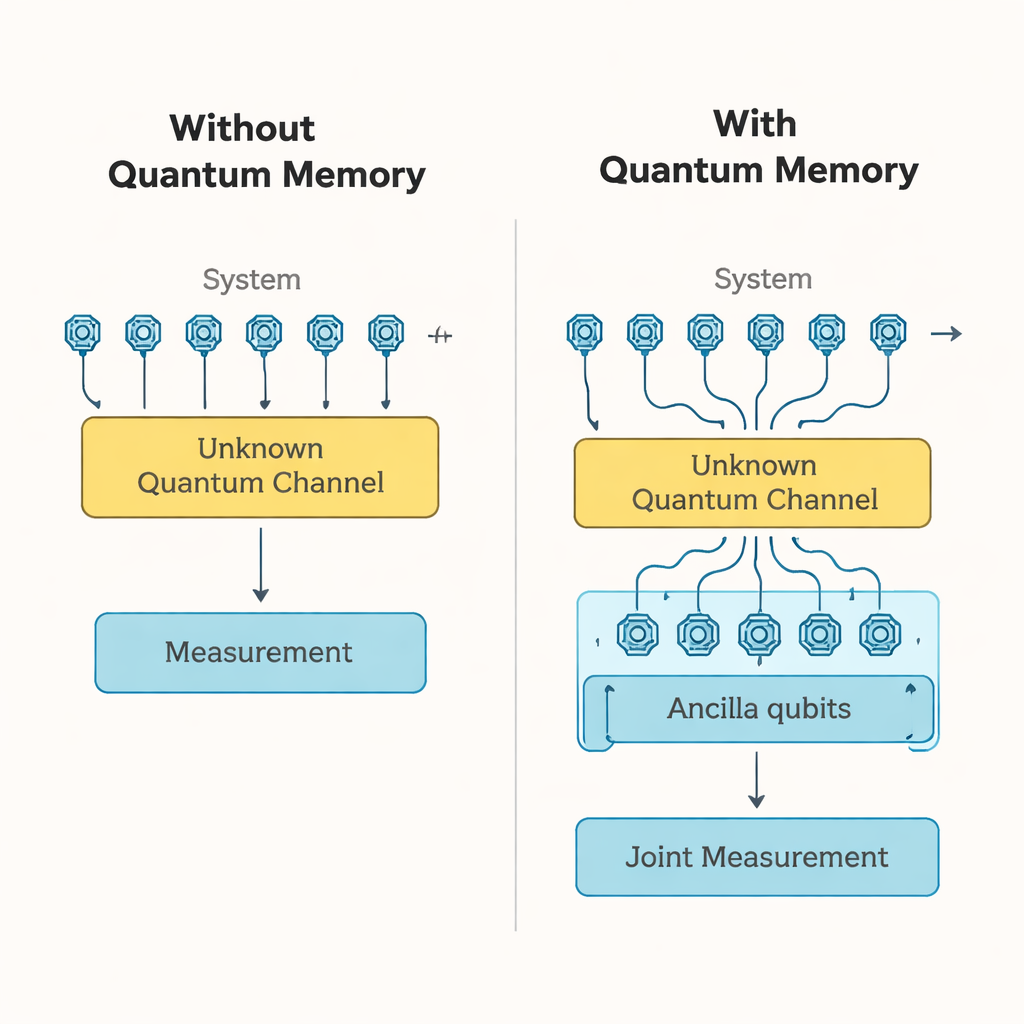
Learning a noisy quantum channel
The authors focus on a central test case: learning a so‑called Pauli channel, a standard model for noise on n‑qubit devices where errors are built from combinations of the familiar X, Y, and Z quantum operations. The learning task is to estimate certain parameters of this noise channel to within a chosen accuracy and confidence, and the key cost is the number of times the channel must be applied and measured. Without any quantum memory at all, previous results showed that this cost typically grows exponentially with n. By contrast, if one can prepare a large Bell‑pair state linking n system qubits to n ancilla qubits, the same job can be done with only a number of uses that grows like a simple polynomial in n, an enormous improvement.
Small entanglement can still give an exponential boost
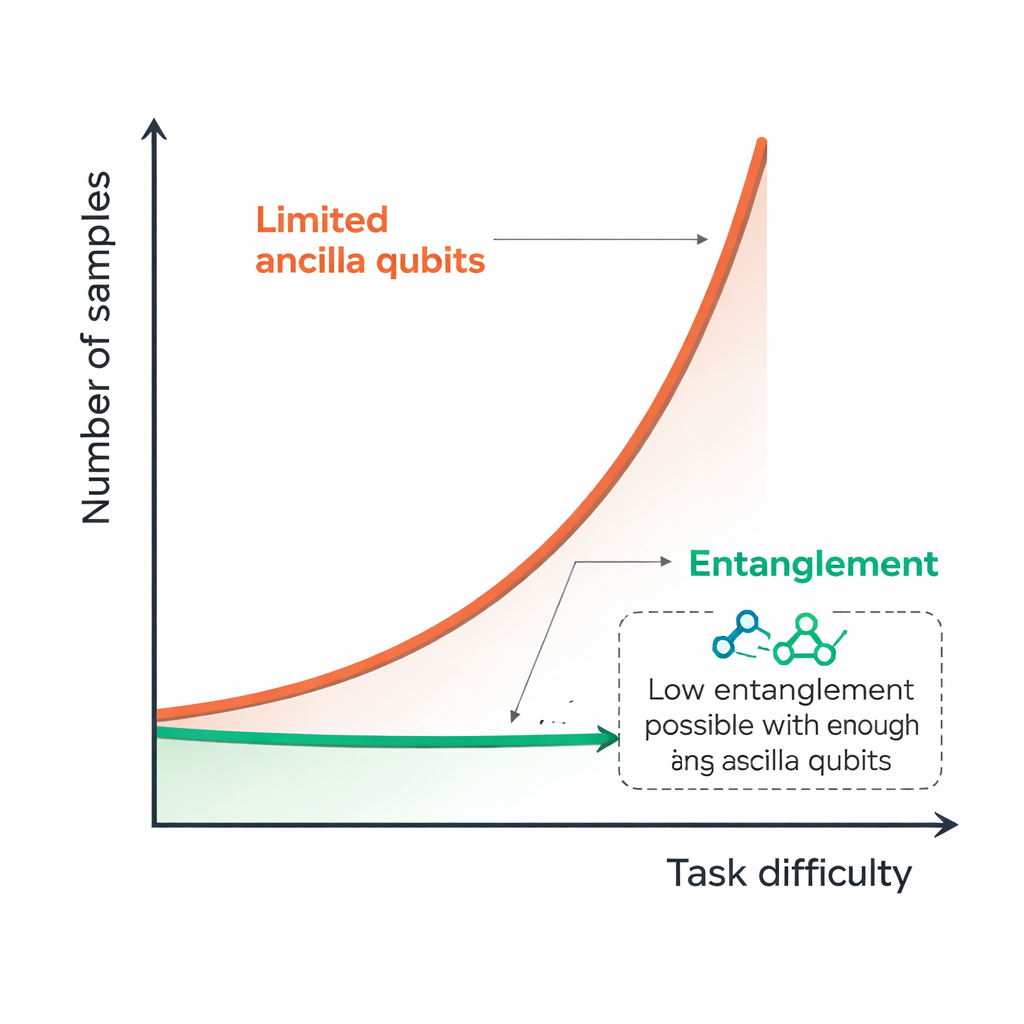
A natural guess is that this exponential boost relies on having a lot of entanglement in each input state. Surprisingly, the authors show this is not true. They construct families of input states whose entanglement between system and ancilla is vanishingly small on a per‑qubit basis, yet still allow the Pauli channel to be learned with only polynomially many uses, as long as one has a full set of n ancilla qubits available. The price of reducing entanglement in each probe is that more probes are needed overall, but the growth remains polynomial rather than exponential. In other words, the total "entanglement budget" can be traded against the number of experimental shots without ever losing the core quantum advantage.
Ancilla qubits are the real bottleneck
The story changes dramatically when the number of ancilla qubits is restricted. The authors prove that if you do not have enough ancilla qubits in your quantum memory, then even learning a limited, low‑detail subset of the channel’s parameters becomes exponentially hard again, no matter how cleverly you entangle what you have. They map out how this difficulty depends on both the number of ancilla qubits and how rich a description of the channel you aim for. In particular, they show that to keep the sample cost polynomial for tasks that scale with system size, the number of ancilla qubits must essentially grow in lockstep with the number of system qubits.
What this means for building and testing quantum devices
For non‑experts, the main takeaway is that the "secret ingredient" behind exponential gains in learning quantum noise is not huge amounts of entanglement in each state, but rather having a quantum memory dimension—that is, enough ancilla qubits—that scales with the size of the device under test. Entanglement still matters, but only in a modest amount, and can be diluted over many runs. This insight guides how experimentalists should invest scarce resources: building larger, stable quantum memories may be more crucial than perfecting highly entangled probes. The results also set targets and limitations for future error‑diagnosis and benchmarking tools in realistic, noisy quantum machines.
Citation: Kim, M., Oh, C. On the fundamental resource for exponential advantage in quantum channel learning. Nat Commun 17, 1822 (2026). https://doi.org/10.1038/s41467-026-68532-y
Keywords: quantum learning, Pauli channel, quantum memory, entanglement, quantum noise characterization