Clear Sky Science · en
Physical neural networks using sharpness-aware training
Why this matters for the future of AI hardware
As artificial intelligence grows more powerful, it is increasingly limited not by clever algorithms but by the chips that run them. One promising escape route is to build neural networks directly in physical hardware using light, analog electronics, or other wave-based systems. This article introduces a new way to train such “physical neural networks” so that they stay accurate even when the real world is messy—when devices are slightly misbuilt, heat drifts, or components move out of alignment.
From digital brains to physical machines
Modern AI typically runs on digital hardware like graphics processors, where training relies on the backpropagation algorithm to tune millions of numerical weights. Physical neural networks attempt to offload this computation into real materials and devices—such as photonic chips, interferometer meshes, or diffractive optical setups—whose behavior naturally mimics neural network math. Because these systems process information where it is stored, they can be far faster and more energy efficient than conventional chips. But training them is hard: either you train a digital model and hope it matches the hardware, or you train directly on the device itself. Both paths run into trouble when real devices deviate from ideal models or drift over time.
Two flawed ways to teach physical networks
The first approach, called in silico training, learns all parameters on a computer model and then copies them to the hardware. This only works well if the mathematical model nearly matches the fabricated device, which is rarely true once manufacturing variations, electrical noise, and thermal effects are included. The second approach, in situ training, loops the physical device directly into the learning process, repeatedly measuring outputs as parameters are adjusted. While this bypasses modeling errors, it creates other problems: gradient information is hard and costly to obtain, training becomes device-specific, and the resulting parameters usually cannot be transferred to another nominally identical chip. In both cases, small changes after deployment—such as a tiny temperature shift or misalignment—can slash accuracy and force expensive retraining.
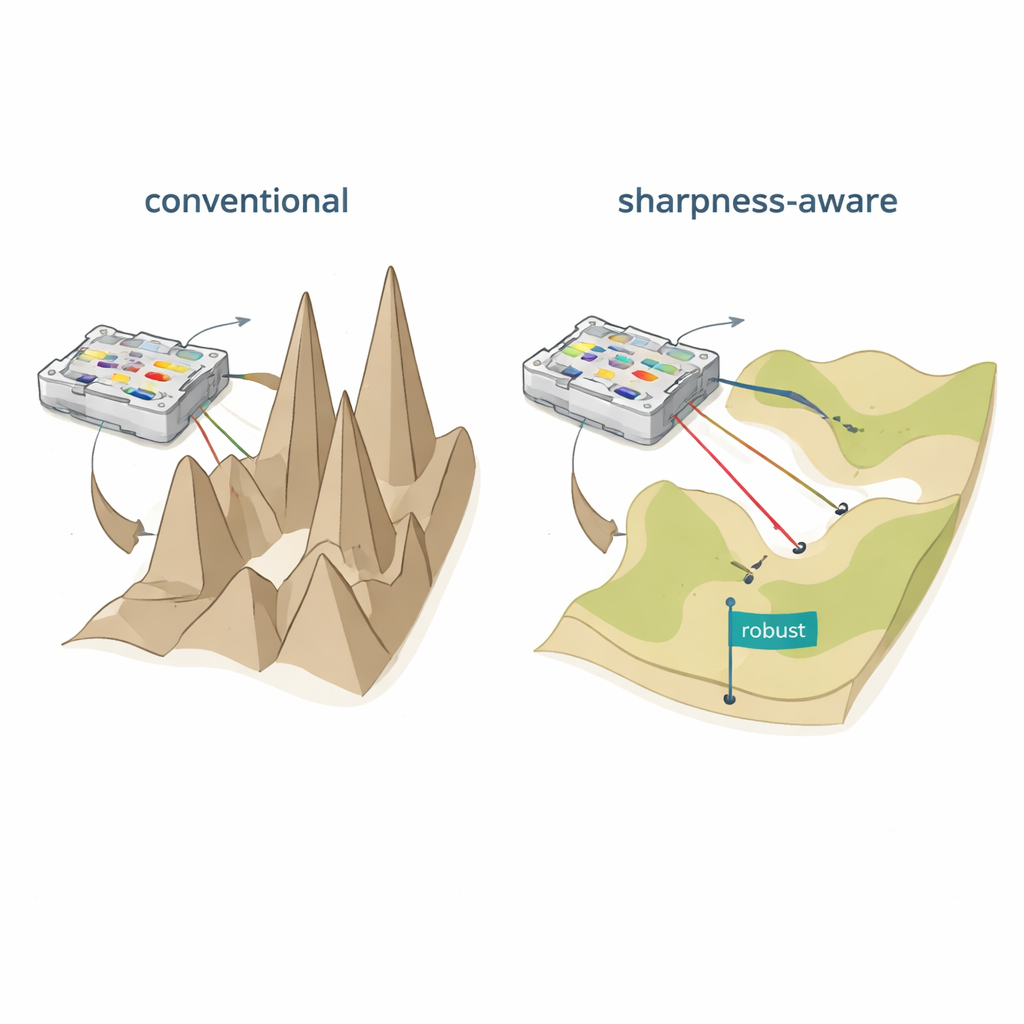
Flattening the learning landscape
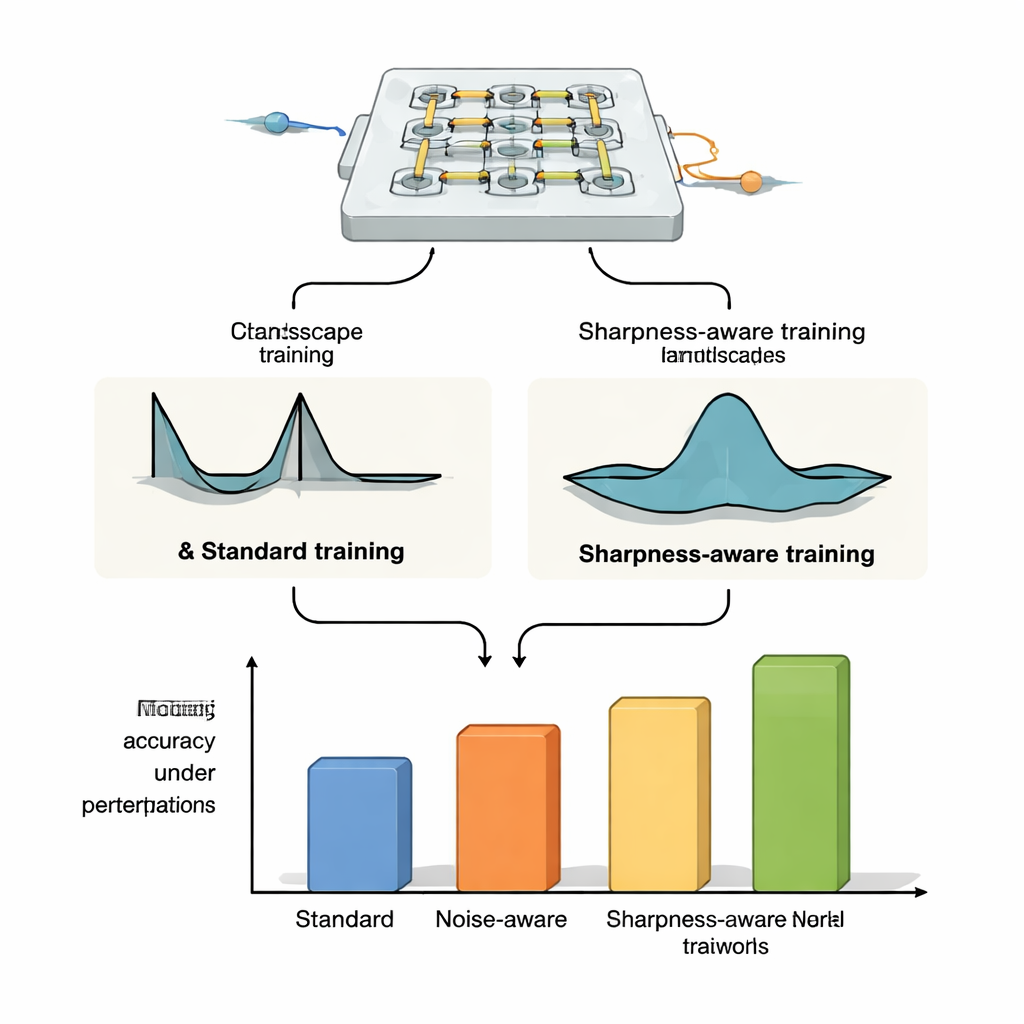
The authors propose sharpness-aware training (SAT), inspired by a machine-learning idea called sharpness-aware minimization. Instead of only finding settings that give low error on the training data, SAT also seeks regions where the error changes slowly when the underlying physical parameters are nudged. In geometric terms, traditional training often finds a deep but narrow valley in the “loss landscape,” where even tiny shifts in currents, phases, or positions cause performance to collapse. SAT deliberately searches for broad, flat valleys where performance remains high under such disturbances. Mathematically, it adds a term to the training objective that penalizes sharp, highly curved regions in parameter space, and it approximates this penalty efficiently using two carefully chosen gradient steps rather than costly second-derivative calculations.
Proving robustness across different optical platforms
To show that SAT is not tied to one specific device, the authors apply it to three distinct optical neural-network platforms. On microring-resonator weight banks—tiny loops of silicon that route light at different wavelengths—they demonstrate that SAT-trained systems maintain high classification accuracy even when the temperature drifts by degrees Celsius, whereas standard training and noise-injection methods fail dramatically. They extend this to more demanding tasks like image classification on CIFAR-10, image compression and reconstruction, and image generation, where SAT keeps performance stable while conventional methods break under modest thermal shifts. In simulations of Mach–Zehnder interferometer meshes, SAT-trained models are far more tolerant to realistic manufacturing errors and, crucially, parameters trained on one device can be transferred to other chips with different imperfections without losing accuracy. Finally, in a free-space diffractive optical setup using an OLED display, lenses, and a spatial light modulator, SAT improves tolerance to physical misalignments such as rotation, pixel shifts, and scaling, even though the exact relationship between these misalignments and the network parameters is not explicitly modeled.
A practical path to reliable physical AI
In plain terms, this work shows how to teach hardware neural networks in a way that “forgives” the inevitable quirks of real devices. By steering learning toward flat, stable regions of the error landscape, sharpness-aware training makes physical neural networks both more accurate and more robust to fabrication variations, temperature changes, and mechanical misalignments. Because it can be used with or without detailed physical models and works across several types of optical hardware, SAT offers a practical recipe for scaling up fast, energy-efficient physical AI systems from laboratory demonstrations to real-world applications.
Citation: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Keywords: physical neural networks, photonic computing, robust training, sharpness-aware optimization, neuromorphic hardware