Clear Sky Science · en
Single-view neural illumination estimation and editing for dynamic light field display
Why your virtual world should match your living room
Anyone who has worn a virtual or mixed reality headset has seen it: a digital object that looks oddly out of place, with lighting and shadows that don’t quite match the room you’re in. This paper tackles that problem. The authors present a way for headsets to “understand” the lighting in your real environment from just a single camera view, then use that knowledge to make virtual objects look as if they truly belong in your world—no special light probes, elaborate captures, or heavy recalibration required.
Making light in space easier to handle
In physics and computer graphics, a scene’s appearance is governed by its full “light field”: all the light rays flowing through space in every direction. Reconstructing this field exactly is normally very data-hungry, needing many images and careful measurements. Modern 3D techniques like neural radiance fields can store scenes in neural networks, but they typically “bake in” whatever lighting was present during capture. That means the virtual scene looks right only under those original conditions, and falls apart when the real room’s lighting changes. The authors aim to break this limitation by finding a compact description of real-world illumination from minimal data, then using it to flexibly relight a neural 3D scene.
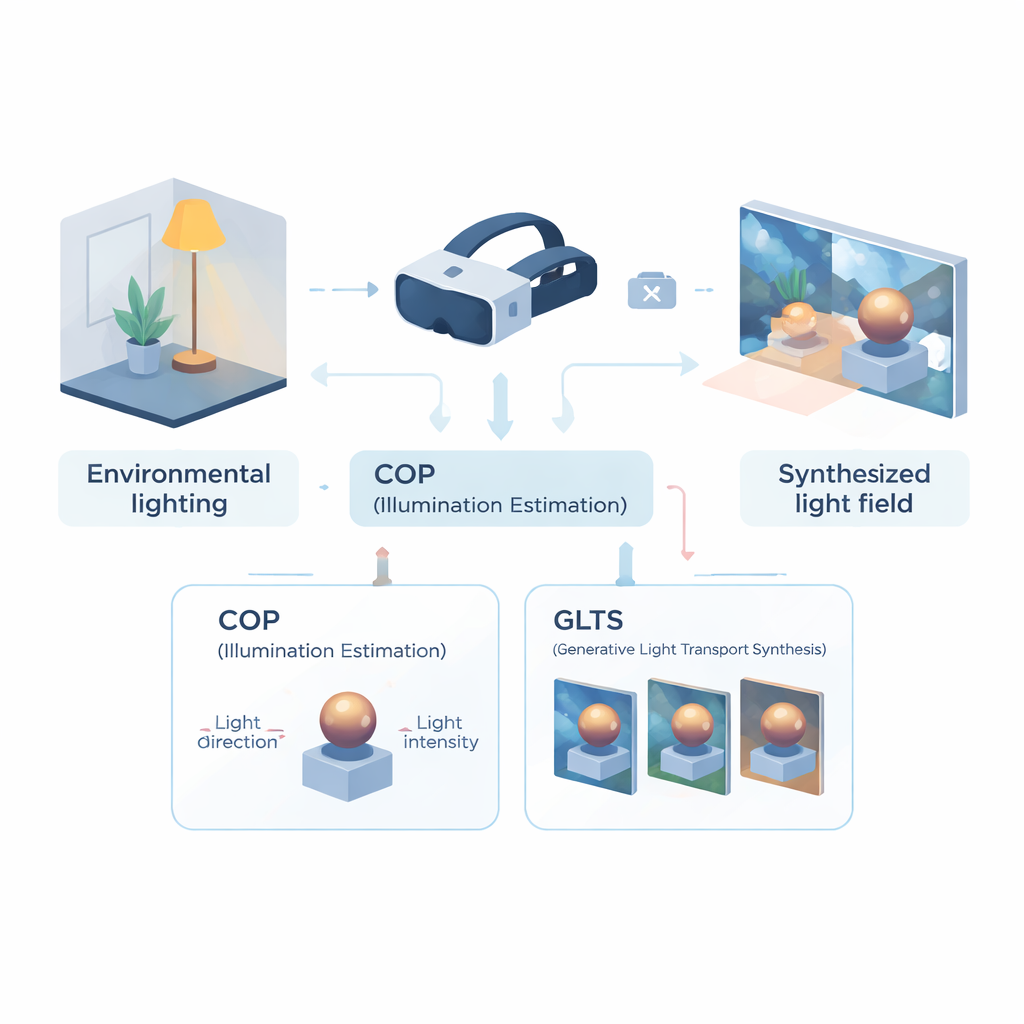
Teaching a headset to read the room
The first part of the framework is a computational optical perception (COP) module, designed to read lighting from a single camera view. Instead of reconstructing the entire light field, COP focuses on the dominant light source: its direction and strength. A multi-scale neural network scans the input image for physically telltale cues—bright reflections, shading gradients, and shadows—while a special interpolation step corrects for the non-linear way cameras compress brightness. This yields numerical estimates of light intensity and direction that are more faithful to real energy in the scene. A second stage, called the semantic interpreter, then refines these numbers and produces a short text-like description of the lighting (for example, that light comes from above and to the right). This combination of numbers and words makes the estimate more stable and easier to use in the next stages.
Repainting objects with new light
Armed with this compact description of illumination, the second module—generative light transport synthesis (GLTS)—takes over. GLTS starts from an existing 3D neural representation of an object or scene, rendered once under its old, baked-in lighting. Guided by the inferred light direction, intensity, and the textual description, a generative network “repaints” this view so that highlights and shadows match the new environment. To keep the result both realistic and specific to the object, GLTS blends two kinds of guidance: global control from the lighting parameters and fine detail drawn directly from the observed image. Through a specialized training process that concentrates solely on how a single object responds to different lights, the model learns to shift reflections and soften shadow edges in physically plausible ways rather than simply applying a generic style filter.
Building a consistent 3D light field from many views
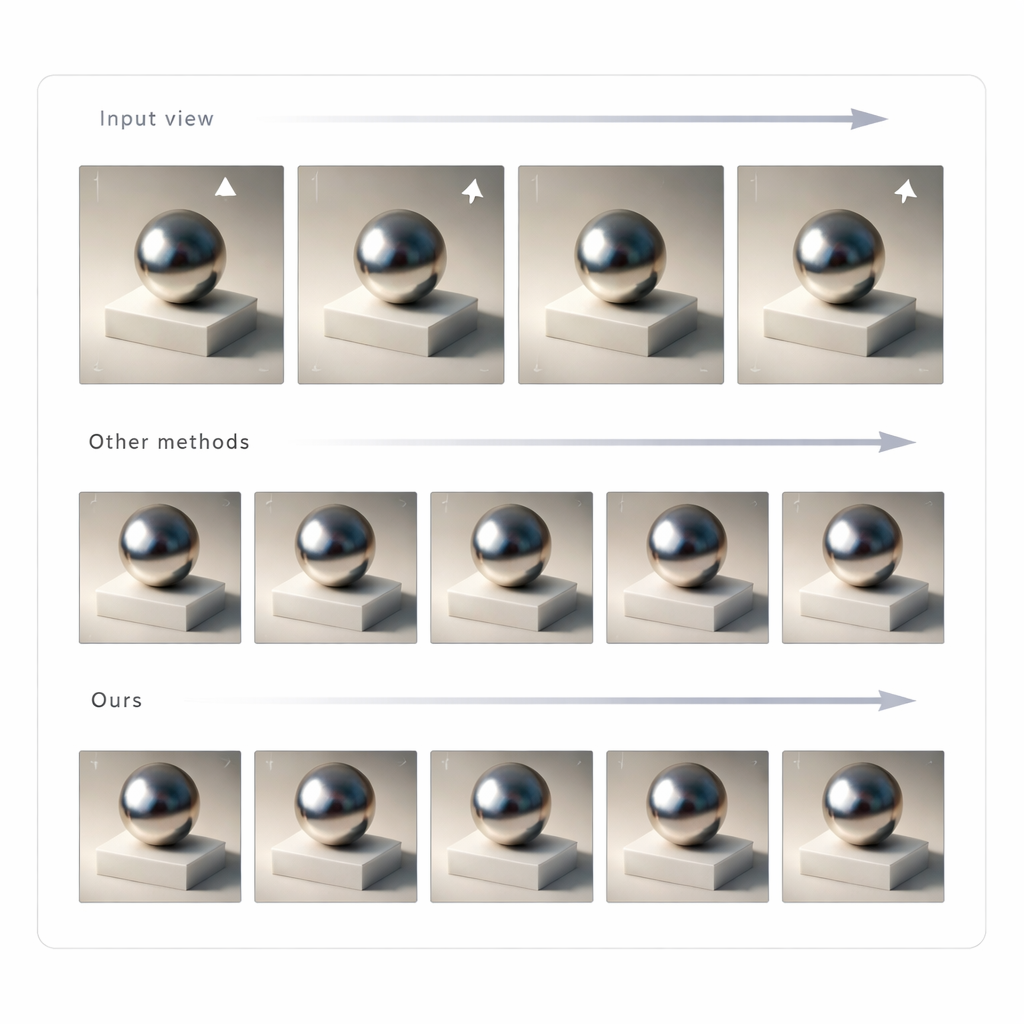
Changing a single image is not enough for convincing mixed reality; the lighting has to stay consistent as you move your head. To achieve this, the authors use GLTS to generate a set of relit images from many viewpoints and then treat these as targets for rebuilding the 3D scene. A joint optimization process simultaneously adjusts the neural 3D representation and the virtual camera positions so that rendering the new model reproduces all the synthesized views. This step corrects subtle distortions introduced by the generative network and produces a coherent 3D asset whose appearance remains stable and believable from any angle. The team tested their method against several state-of-the-art relighting approaches and found that it delivered sharper agreement with ground-truth images and more natural-looking shadows and reflections, as judged by both pixel-level and perception-based metrics.
What this means for future headsets
For non-specialists, the key takeaway is that this work shows how future VR, AR, and mixed reality devices could adapt virtual content to real-world lighting from just a single quick glance through the headset’s camera. Instead of laborious capture setups or retraining bespoke models for each new scene, the system estimates the main lighting conditions, regenerates how the scene should look under those conditions, and rebuilds a consistent 3D representation. The result is virtual objects whose brightness, gloss, and shadows respond to your environment much like real objects do, paving the way for mixed reality experiences that feel less like overlayed graphics and more like genuine additions to the physical world.
Citation: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Keywords: mixed reality lighting, neural light fields, single-view relighting, virtual reality displays, computational imaging