Clear Sky Science · en
Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network
Why teaching computers about ancient treasures matters
Cultural treasures in museums and archives are increasingly photographed and put online, but most of these images are poorly labeled or not labeled at all. That makes it hard for visitors, teachers, and researchers to find what they are looking for, and it limits how deeply the public can explore humanity’s shared heritage. This paper explores a new way to automatically recognize and sort such images by combining two ideas that rarely meet: museum collections and quantum computing.
From dusty storerooms to digital collections
Museums today hold millions of objects, from bronzes and lacquerware to embroidered robes. Many institutions are racing to digitize these holdings so that anyone with an internet connection can browse them. Yet once images are online, they must be placed into the right categories—such as enamel, jade, silk, or brocade—if they are to be truly useful. Conventional artificial intelligence tools usually look only at the pixels in each picture. They ignore the rich written descriptions that curators and historians attach to objects, even though these captions often mention materials, colors, and motifs that are not obvious to the eye. As collections grow larger, classical algorithms also struggle with speed, energy use, and complexity.
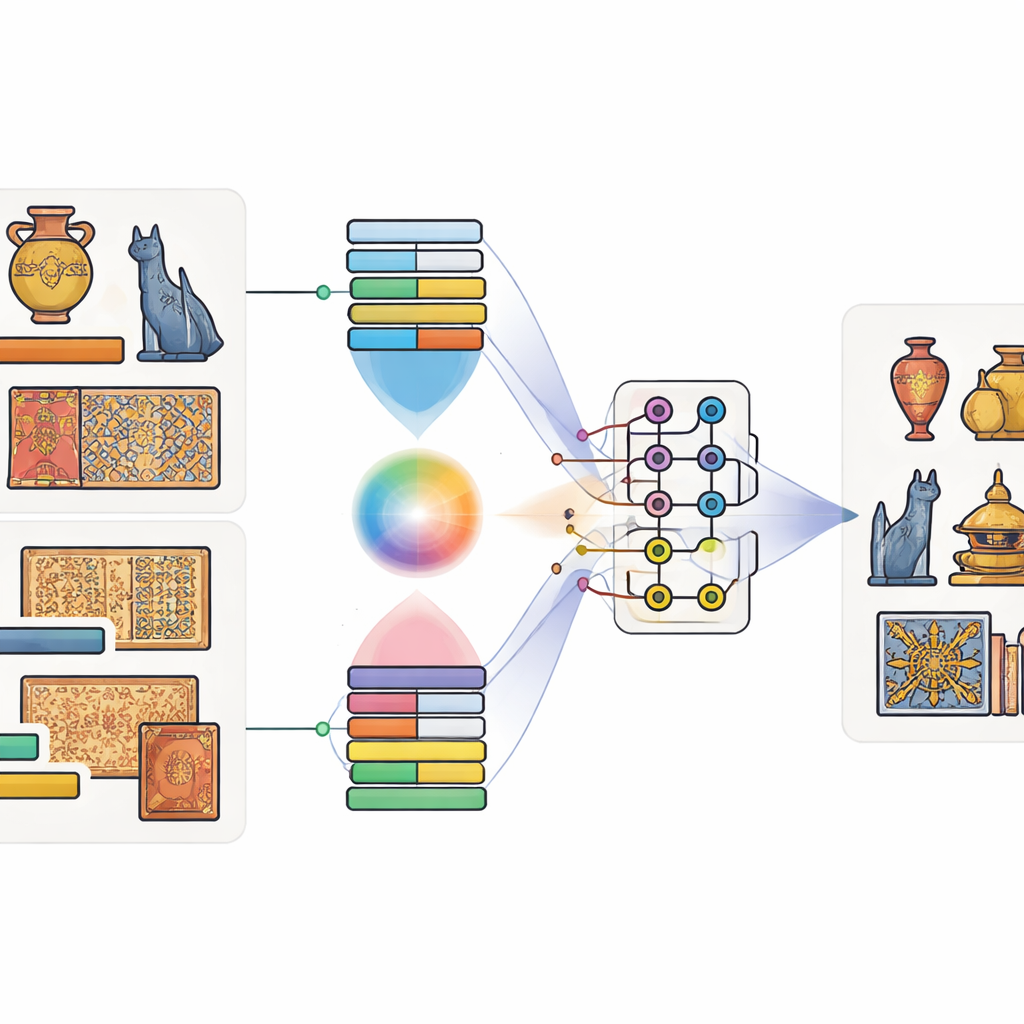
Pairing images with words, and bits with qubits
The authors propose a model they call the Quantum-Classical Multimodal Fusion Model. “Multimodal” simply means that it pays attention to more than one kind of information at once—in this case, both the image of an artifact and its caption. First, well-established tools trained on huge datasets are used: a deep image network to capture shapes and textures, and a language model to capture the meaning of the caption. A special attention mechanism then learns which regions of the image tend to go with which words. For example, when a caption mentions “golden dragon,” the model learns to focus on gold-colored regions shaped like a dragon. This produces a joint description that blends sight and language.
Letting quantum circuits mix the signals
Once the image-and-text features are extracted, the model feeds them into a small simulated quantum circuit. Because present-day quantum hardware has only a modest number of qubits, the authors compress the information using a scheme that packs many classical values into the amplitudes of a few qubits. Inside the quantum part, they design a two-stage circuit that repeatedly applies rotations to individual qubits and then entangles them—forcing their states to become interdependent. This structure is meant to tease out subtle relationships between visual patterns and caption cues that might otherwise be missed. After this quantum processing, the state of the qubits is measured and converted back into ordinary numbers, which are then passed to a final classifier that predicts the object’s category.
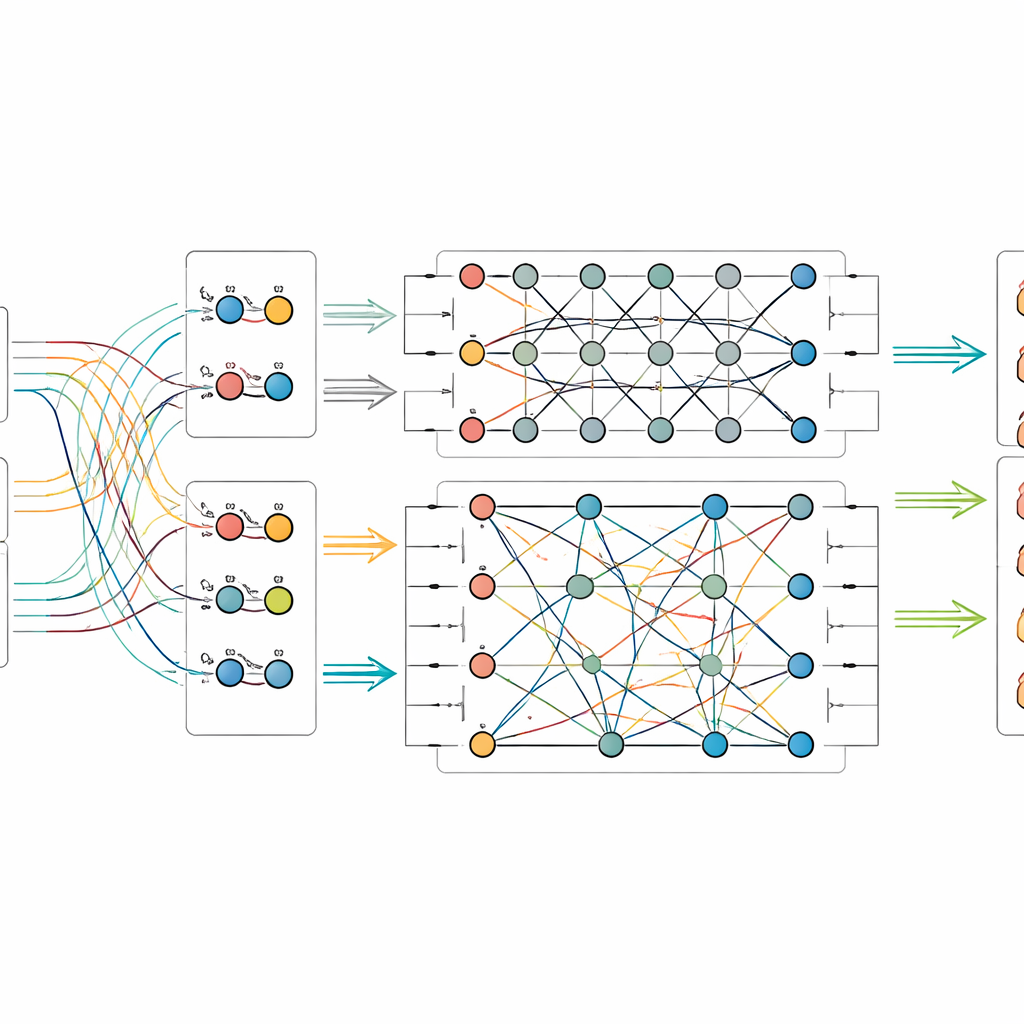
Putting the new approach to the test
To see whether their method offers real benefits, the researchers assembled two new datasets from the Palace Museum: one of physical artifacts such as enamel, gold and silver work, lacquer, bronze, and jade, and another focusing on textiles like silk, satin, brocade, and the intricate weaving style known as kesi. Each image comes with an official caption and a trusted label from the museum’s records. They compared their quantum–classical fusion model against a range of strong rivals, including pure image systems, pure text systems, and other techniques that combine both. Across both datasets, the new model achieved the highest scores in accuracy and related measures, edging out even advanced multimodal and quantum-inspired baselines. Further experiments showed how its performance depends on the number of qubits and circuit depth, and that it remains reliable even when common types of quantum noise are introduced in simulation.
What this could mean for future museum visitors
For non-specialists, the key message is that mixing images, words, and quantum-inspired processing can make computers better at telling different kinds of cultural objects apart. While the quantum parts are currently run on simulators rather than full-scale quantum machines, the study suggests a path toward more efficient and expressive tools as hardware matures. In practical terms, such systems could help museums and archives automatically sort new uploads, clean up old records, and make it easier for people to search for “jade ritual vessels” or “embroidered dragon robes” and actually find them. The work hints that quantum computing may become a useful new route for understanding and preserving cultural heritage in the digital age.
Citation: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Keywords: cultural heritage images, quantum machine learning, multimodal fusion, museum digitization, image recognition