Clear Sky Science · en
Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework
Bringing Hidden Traditions into the Digital Age
Across China, masters of traditional opera, paper-cutting, shadow puppetry, and other living arts safeguard skills passed down for generations. Yet much of what we know about these inheritors exists only in scattered files and images online, making it hard for the public—or even researchers—to find reliable information. This paper presents a new computer framework that automatically reads the "visual business cards" of intangible cultural heritage (ICH) inheritors and then uses advanced language models to answer questions and generate readable reports about them.
From Picture Cards to Structured Knowledge
Many cultural institutions now publish digital cards that combine text, layout, and simple graphics to introduce each inheritor: name, craft, place, biography, and more. Humans can skim these at a glance, but computers struggle because the cards come from many regions, use different designs, and often contain missing or damaged text. The authors build a large dataset of 5,237 such business cards for Chinese ICH inheritors, each carefully labeled with ten key information types, such as project number, project name, region, gender, work unit, and a short description. They first use optical character recognition (OCR) to read the text and record where each snippet appears on the card, then employ large language models to help standardize labels before human experts verify them.
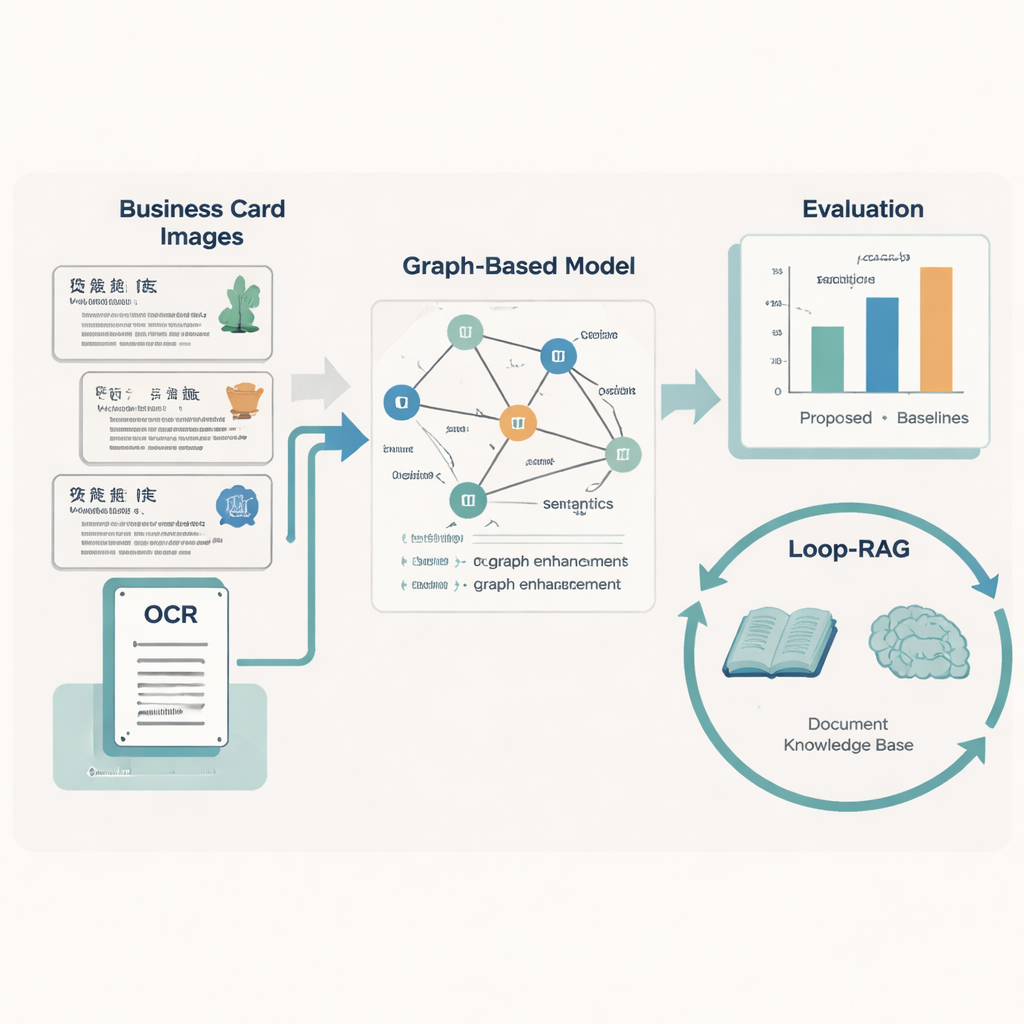
Teaching Machines to Read Layout and Meaning
To turn each card into clean, structured data, the team designs a "Graph-Retrieval" model that mimics how people use both words and layout. Every text fragment on a card becomes a node in a graph, and the spatial relations between fragments—left, right, above, below—form the edges. A language component based on RoBERTa and a bidirectional LSTM learns the meaning of the text, supported by a custom dictionary of nearly 5,000 ICH-specific terms so that unusual craft names or local phrases are handled correctly. On top of this, a graph neural network spreads information across neighboring nodes, improving predictions about what each text fragment represents (for example, deciding whether a place name is a region or a work unit).
Making the System Robust to Real-World Messiness
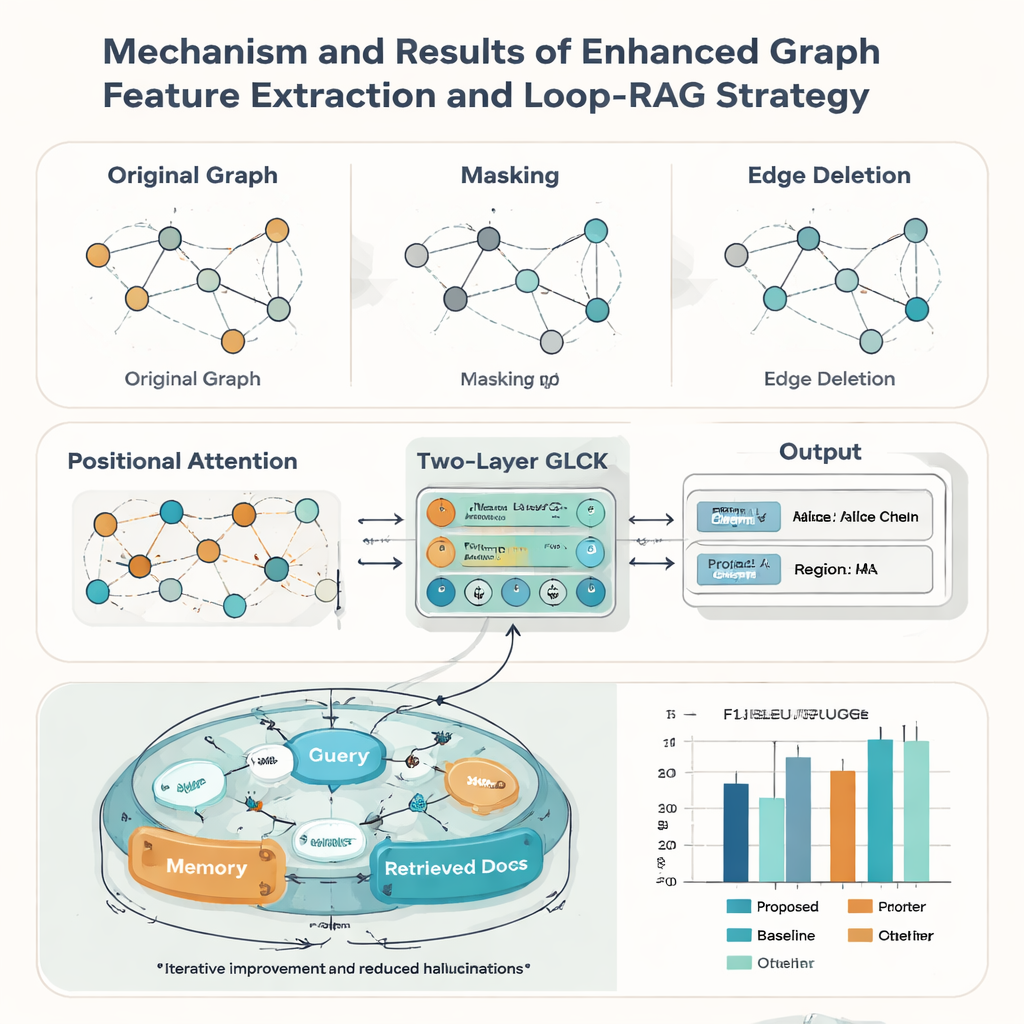
Real heritage records are rarely perfect: cards may be worn, cropped, or poorly scanned. To cope with this, the authors strengthen their graph model with three ideas borrowed from data augmentation. They randomly mask some nodes so the system learns to infer missing information from context; they randomly delete some edges so it can tolerate changes in layout; and they add a positional attention mechanism that captures the overall "reading order" of elements on a card. Together, these tricks help the model generalize to many styles and qualities of documents. In tests against nine well-known rival methods, the new approach achieves the highest macro-average F1 score (0.928) on the ICH card dataset and also leads on five public document benchmarks, suggesting it is broadly useful beyond heritage applications.
Smarter Question Answering with Looping Retrieval
Recognizing the text is only half the story; the paper’s second contribution is a Loop-RAG (Loop Retrieval-Augmented Generation) strategy that works with large language models such as GPT-4, Llama, and ChatGLM. Traditional retrieval-augmented systems fetch background documents once and then generate an answer, which can still be incomplete or wrong. In contrast, Loop-RAG adds an inner loop that repeatedly checks whether the language model has enough information for the current answer and, if not, triggers another targeted search in a vectorized ICH knowledge base. An outer loop then studies many past interactions to learn which retrieval paths and prompt styles work best, gradually reducing wasted searches and factual mistakes.
From Raw Records to Trustworthy Cultural Stories
Using this combined framework, the system can automatically create short reports about an inheritor—summarizing their craft, region, representative works, and status—and answer thousands of factual questions about people and practices. Measured by standard language quality scores such as BLEU, METEOR, and ROUGE, Loop-RAG with GPT-4 outperforms both plain language models and simpler retrieval setups, while also achieving the best accuracy (F1 up to 0.941) in question answering, even when only a few examples are provided. For a lay reader, this means that future cultural heritage platforms could offer interactive, trustworthy explanations of traditional arts on demand, turning scattered digital records into rich, navigable stories that help keep living traditions visible and valued.
Citation: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Keywords: intangible cultural heritage, information extraction, graph neural networks, retrieval-augmented generation, digital humanities