Clear Sky Science · en
Semantic segmentation of Buddha facial point clouds through knowledge-guided region growing
Reading the Face of History
Buddha statues carved into cliffs and temple walls are more than beautiful works of art—they are three-dimensional records of religious belief, artistic fashion, and cultural exchange across centuries. This study shows how computer scientists and heritage experts can "read" these stone faces in detail by automatically separating the eyes, nose, mouth, and other features from dense 3D measurements, even when there are no example labels to learn from. The goal is to turn silent stone into measurable data that helps historians compare styles, track change over time, and plan careful conservation.
Why Digital Faces Matter
Across famous sites such as Dunhuang, Yungang, and Longmen, Buddha faces differ subtly by dynasty and region—some fuller, some more slender, some with softer eyes or more prominent noses. Traditionally, art historians describe these differences by eye; now, high-precision 3D scans capture the surface of statues as millions of points in space. However, these “point clouds” are messy: they have no color or texture, and they offer no built-in indication of where the eyes end and the cheeks begin. Existing automatic methods either require many hand-labeled training examples, which simply do not exist for heritage statues, or they split surfaces purely by geometry, ignoring the sculptural rules that artists actually followed.

Teaching Algorithms the Rules of the Face
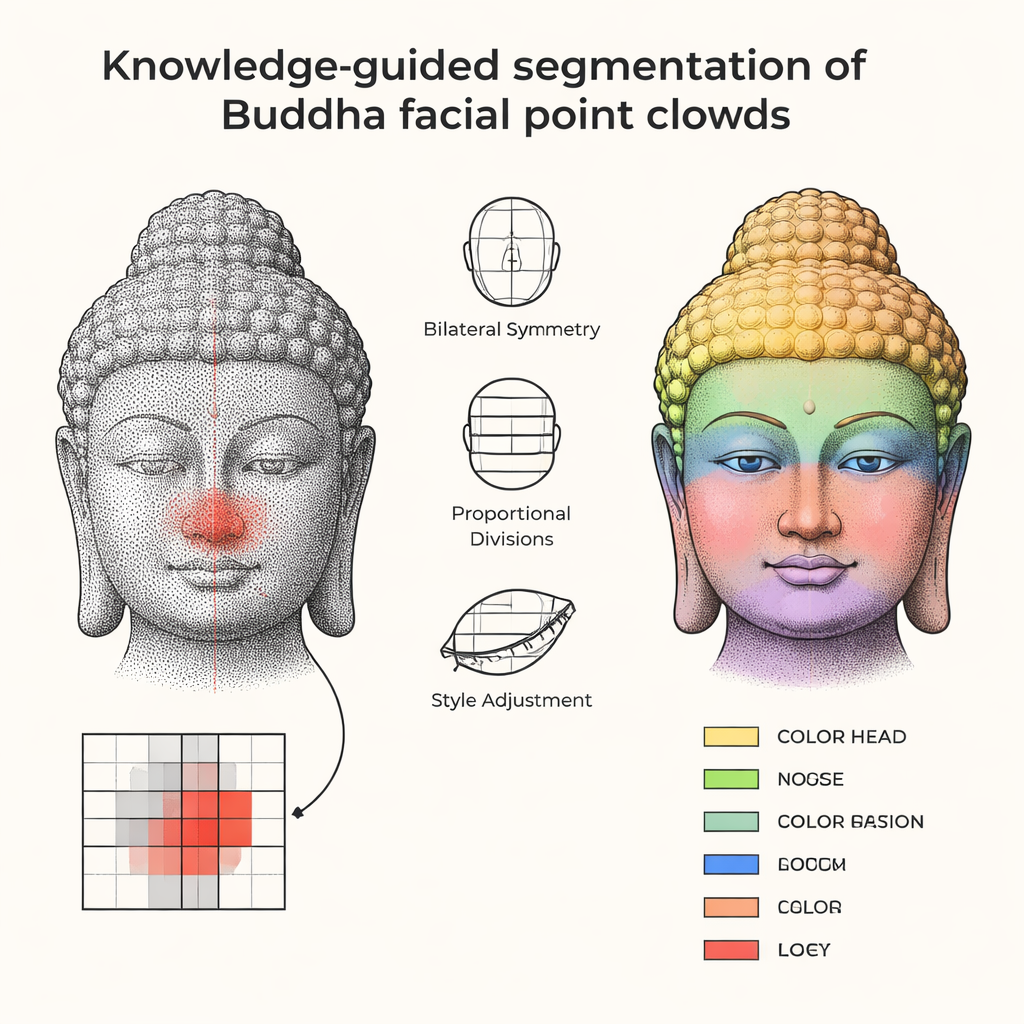
Instead of trying to learn from scarce data, the authors start from knowledge that sculptors themselves used. Traditional Buddhist manuals describe standard facial proportions, such as dividing the face into equal thirds for forehead, nose, and chin, and keeping the features symmetrical around a central axis. The researchers translate this cultural and anatomical know-how into simple geometric rules: a symmetry plane down the middle; a vertical line that runs through the center of the nose; and ratios that relate the positions and sizes of eyes, nose, mouth, ears, and chin. These rules are not rigid templates: they include adjustable parameters so that fuller Tang-style faces and more slender Song-style faces both fit within a flexible, but recognizable, framework.
Growing Regions from Seeds
Working from a cleaned 3D scan, the method first aligns the Buddha face so it looks straight ahead, then projects the surface onto a square grid, turning the 3D shape into something like a shaded height map. Within this grid, the algorithm picks starting "seed" positions for each facial feature, helped by the prior rules: the nose seed lies near the central vertical line and local high point, the eyes are placed at symmetric peaks to either side, the mouth sits below the nose in a shallow hollow, and so on. From each seed, the computer "grows" a region outward, adding neighboring cells only when their height and slope fit what you would expect for, say, a nose ridge rather than a cheek. Extra steps then clean up the result, trimming stray bits, filling small gaps, and gently smoothing outlines so that the segmented eyes, lips, and chin look continuous and plausible to both the computer and a human expert.
Putting the Method to the Test
The team tried their approach on fifteen Buddha faces—nine synthetic models with controlled shapes and six real scans from renowned Chinese heritage sites. They measured quality by how well the automatically segmented regions overlapped with careful hand-drawn outlines from specialists and how closely the computed boundaries matched the experts' contours. Across eyes, eyebrows, ears, nose, mouth, and chin, the method achieved high scores, meaning most of the points were correctly assigned to the right feature. Importantly, the results were stable across different carving styles and levels of surface wear. When the authors compared their approach to a popular deep-learning model trained with only a handful of labeled examples, the data-hungry network struggled badly, while the knowledge-guided method remained accurate without needing large training sets.
What This Means for Heritage
By encoding sculptors’ traditional measurement rules into a modern algorithm, this study shows that computers can segment Buddha faces in 3D with little or no manual labeling, while still respecting the cultural logic of the original artwork. For historians, this opens the door to systematic, quantitative comparisons of facial styles across sites and periods; for conservators, it offers a precise way to monitor damage or guide digital restoration. In essence, the method turns centuries-old conventions about the ideal Buddha face into a practical tool for reading, preserving, and understanding the stone faces that have watched over temples and grottoes for more than a thousand years.
Citation: Wei, S., Hou, M., Yang, S. et al. Semantic segmentation of Buddha facial point clouds through knowledge-guided region growing. npj Herit. Sci. 14, 109 (2026). https://doi.org/10.1038/s40494-026-02377-y
Keywords: Buddha statue 3D scanning, cultural heritage digitization, point cloud segmentation, facial proportions in art, knowledge-guided algorithms