Clear Sky Science · en
High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting
Why clearer digital relics matter
Museums and archaeologists around the world are racing to create faithful 3D copies of fragile artifacts, from porcelain vases to temple gateways. These digital stand‑ins allow us to study, share, and preserve cultural treasures without touching the originals. But in the real world, photos of heritage objects are often dim, blurry, or taken from awkward angles, which can cause today’s 3D reconstruction methods to produce warped or incomplete models. This paper introduces a new approach that tackles that problem head‑on by both cleaning up the input photos and stabilizing the 3D modeling process.
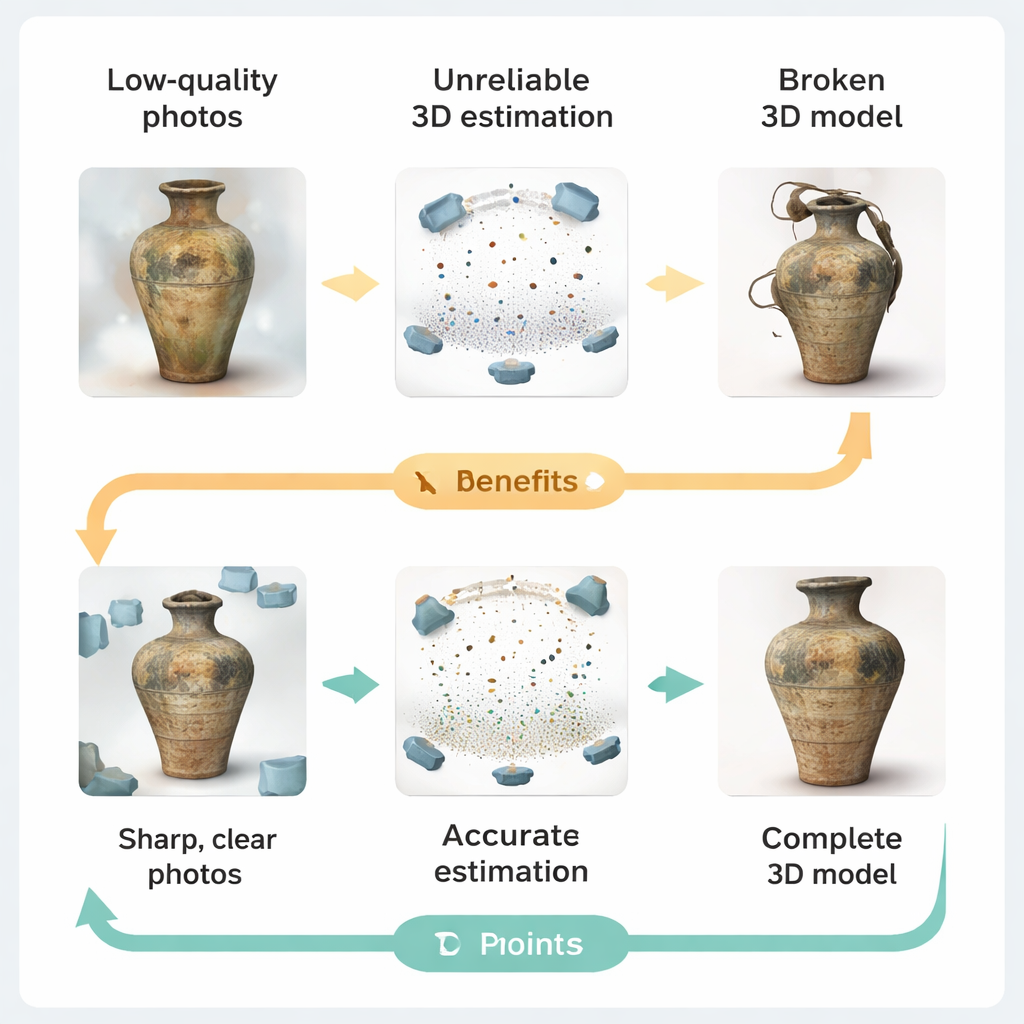
When bad pictures break 3D models
Current 3D capture pipelines typically follow a simple idea: take many photos, estimate where each camera was, infer the object’s shape, and finally render a 3D model. In practice, heritage sites rarely offer studio‑quality conditions. Low light, worn or uneven surfaces, reflections from glass cases, and restrictions on camera placement all degrade the images. The authors show how these flaws ripple through the pipeline. Blurry or low‑resolution photos make it hard for the software to match features across views, leading to camera pose errors and patchy depth estimates. When these unreliable measurements feed into modern "Gaussian splatting" renderers—systems that build scenes from thousands of tiny colored blobs—the result can be unstable optimization, redundant blobs, and visibly distorted geometry.
Sharpening photos with smarter image enhancement
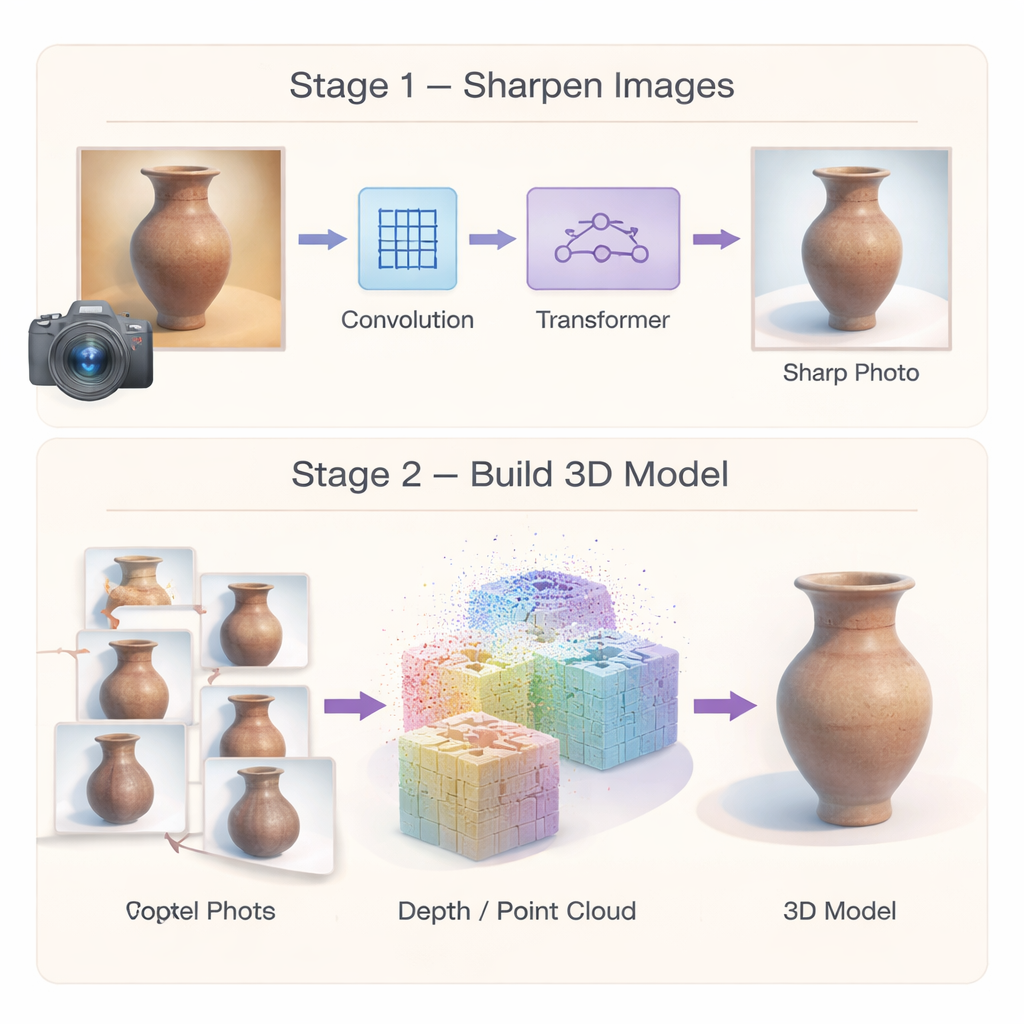
To stop errors at the source, the authors first build a specialized image "super‑resolution" network that turns low‑quality heritage photos into sharper, more detailed ones. Instead of relying on a single type of processing, the network combines two strengths. A multi‑scale convolution module focuses on local details—like cracks, brush strokes, or carved lines—by looking at the image at several neighborhood sizes at once. An efficient Transformer module then captures broader patterns, such as repeating motifs or long curves that run across an object. A third component selectively boosts genuinely similar regions in the image while suppressing noise, so that weak textures are clarified rather than smeared. Together, these elements produce high‑resolution images that preserve both fine ornament and overall structure, giving later 3D stages a far better starting point.
Building steadier 3D shapes from many views
Improved images alone are not enough; the 3D reconstruction itself must also be robust. The second part of the framework rethinks how the 3D model is initialized and optimized. Instead of relying on a sparse set of matched points, the authors use a "dense" matching method that produces rich point clouds and more reliable camera poses from the outset. These dense points act as a strong geometric skeleton for the scene. On top of this, they introduce a hybrid representation: the space around the artifact is divided into coarse 3D cells, and a shared decoder predicts the detailed color and shape of many small blobs within each cell. Because parameters are largely shared rather than duplicated, the method reduces memory use and encourages smooth, coherent surfaces, making the final model less prone to random bumps and holes.
Training in gentle steps instead of all at once
The authors also change how the system is trained. Rather than forcing the model to match both appearance and geometry from the beginning—a recipe for getting stuck in poor solutions—they adopt a three‑step strategy. First, the system learns only to reproduce the colors of the input photos, ensuring global visual consistency. Next, it gradually adds depth information derived from the dense point clouds, which guides the model toward plausible surfaces. In the final stage, it refines small‑scale details by enforcing consistency across overlapping image patches from different views. Tested on a new Cultural‑Relics dataset of porcelain, furniture, handicrafts and textiles, as well as on a standard benchmark of complex outdoor scenes, this staged approach not only improves visual quality but also cuts training time and memory compared with leading alternatives.
What this means for preserving the past
For non‑specialists, the key message is straightforward: this framework helps turn imperfect museum or field photographs into cleaner, more accurate 3D replicas of cultural heritage objects, without physically touching them. By sharpening low‑quality images, starting from a sturdier geometric scaffold, and training the 3D model in carefully controlled stages, the method produces digital artifacts that better capture fine decoration and overall shape while using fewer computing resources. In practical terms, this makes it easier for museums, conservators, and researchers to build trustworthy virtual collections from ordinary photo shoots, helping to safeguard delicate objects and share them widely with scholars and the public.
Citation: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Keywords: cultural heritage digitization, 3D reconstruction, image super‑resolution, Gaussian splatting, digital preservation