Clear Sky Science · en
Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention
Ancient Art Meets Smart Technology
Thangka paintings – the vividly colored scrolls seen in many Tibetan temples – are packed with tiny details and layers of religious meaning. For museum visitors or online viewers without specialist training, much of that symbolism is hard to grasp. This study introduces Geo‑TCAM, an artificial intelligence (AI) system designed to automatically generate rich, accurate descriptions of Thangka images, helping people around the world better understand and preserve this unique cultural heritage.
Why Thangka Pictures Are Hard for Computers
Unlike everyday photos, Thangka works are deliberately dense and symbolic. A single painting may contain a central deity, dozens of smaller figures, patterned borders, and specific hand gestures, objects, colors, and poses that each carry religious significance. Standard image‑captioning programs often cope well with simple scenes like “a dog on a beach,” but they struggle here: they might name the main Buddha yet miss whether he is holding a bowl or a sword, misread his posture, or confuse him with another deity that looks similar. Such mistakes are not trivial – they can flip the story and doctrine the painting is meant to convey, undermining its educational and cultural value.
A New Blueprint for Describing Sacred Images
Geo‑TCAM tackles these problems by combining three ideas: multi‑level visual features, topic knowledge about Thangka art, and geometry‑guided attention to key areas like faces. First, it uses a deep network (ResNet50) to look at each image on several levels at once: mid‑level layers capture edges, textures, and simple shapes, while deeper layers summarize the overall composition. By fusing these levels, the model can notice both fine details such as ornaments and the broad layout of background and figures, giving a richer visual understanding than earlier systems that focused on a single layer. 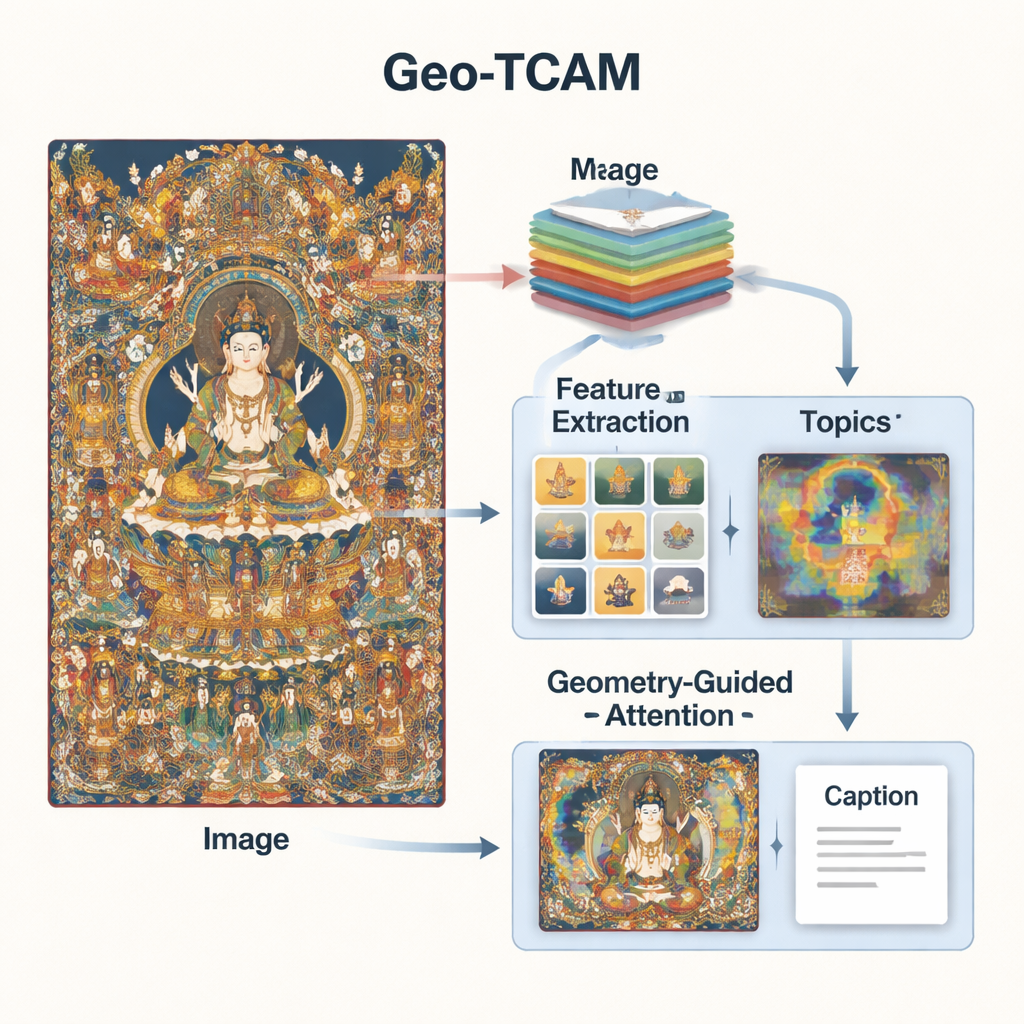
Teaching the Model Thangka “Topics”
Vision alone is not enough; the system also needs some sense of Thangka language and themes. To provide this, the researchers trained a topic model on thousands of expert‑written Thangka descriptions. This model groups words into a handful of common themes – for example, those related to Buddhas, Bodhisattvas, lotus thrones, ritual implements, or protective deities. For each new image, Geo‑TCAM estimates which themes are most relevant and mixes that information with the visual features. An attention mechanism then highlights the image regions that best match the likely topics. In effect, prior knowledge about which objects and symbols tend to appear together nudges the AI toward more meaningful, culturally aware descriptions.
Letting the AI “Look” Where It Matters Most
The third innovation is a geometry‑guided facial spatial attention (GFSA) module. Thangka compositions usually place the main figure’s face in roughly predictable regions of the painting. Geo‑TCAM uses simple edge‑detection tools to home in on this area and its surrounding hands and posture, then applies a dedicated attention mechanism that boosts the influence of these pixels when forming a caption. This “locate first, guide later” strategy helps prevent early misidentification of the central deity, which would otherwise cascade into long chains of textual errors about gestures, attributes, and status. Visual heatmaps show that with GFSA the model concentrates more cleanly on the main figure’s face and key objects while still keeping track of important background motifs. 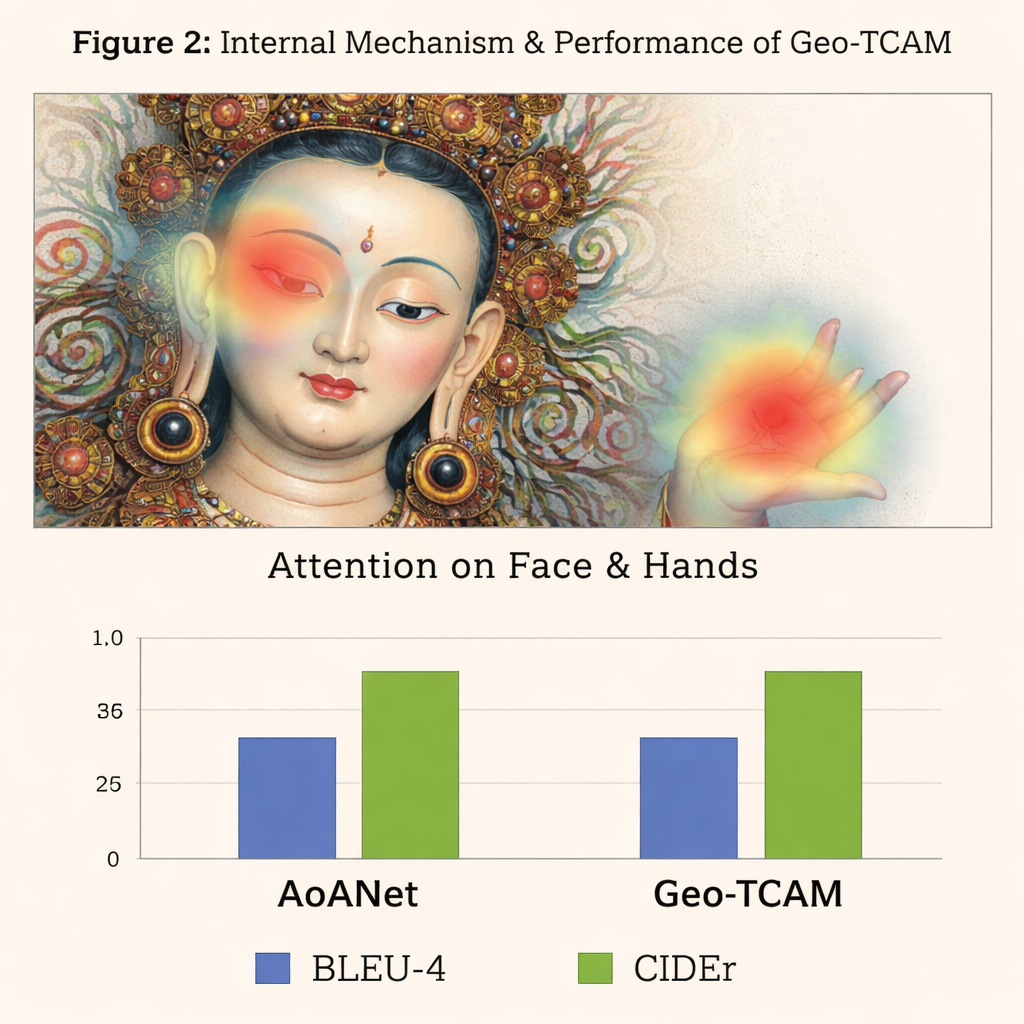
How Well Does Geo‑TCAM Work?
To test their approach, the authors built a specialized D‑Thangka dataset of nearly 4,000 carefully annotated images, each with detailed expert descriptions. On this dataset, Geo‑TCAM clearly outperformed several strong captioning systems, including the popular AoANet and large vision–language models. Depending on the metric, its scores improved by up to about 120% over the baseline, and human evaluators overwhelmingly preferred its captions for accuracy, fluency, and richness of detail. Importantly, when the same model was evaluated on a standard everyday‑photo collection (the COCO dataset), it remained competitive with leading methods, showing that its design is powerful yet still general‑purpose.
What This Means for Heritage and Beyond
For non‑experts, the main takeaway is that Geo‑TCAM can turn visually complex Thangka paintings into clear, informative narratives that highlight who is depicted, what they are doing, and why those details matter. By blending layered visual analysis, learned themes from expert texts, and special attention to faces and gestures, the system aligns its captions much more closely with the way human specialists read these artworks. In the long term, such tools could support digital archives, museum guides, and educational platforms, making esoteric religious art more accessible while helping conservators and scholars document and protect fragile cultural treasures.
Citation: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Keywords: Thangka image captioning, cultural heritage AI, visual attention, topic modeling, art preservation