Clear Sky Science · en
M3SFormer: multi-stage semantic and style-fused transformer for mural image inpainting
Bringing Faded Wall Art Back to Life
Across temples and caves in China, ancient murals and scroll paintings are slowly crumbling—flaking pigment, missing faces, and entire scenes lost to time. Conservators now increasingly rely on digital tools, both to study these works safely and to imagine how they once looked. This paper introduces M3SFormer, a new artificial intelligence system designed specifically to "inpaint" damaged murals and traditional paintings, filling in missing regions while staying faithful to the original structure, colors, and artistic style.

Why Old Murals Are So Hard to Fix
Restoring historical wall paintings is far more demanding than patching a family snapshot. Murals often contain dense patterns, delicate brushwork, and abrupt color boundaries between figures, clothing, and background. Earlier deep-learning methods, especially those based on standard convolutional neural networks, work well for small scratches but falter when large chunks are missing. They may blur important lines, invent shapes that clash with surrounding imagery, or smooth away the dramatic contrasts that give murals their character. Other approaches compress image information too aggressively, throwing away the very high-frequency details—fine cracks, hairlines, textile textures—that preservationists care about most.
A Three-Stage Digital Restoration Pipeline
M3SFormer tackles these challenges with a coarse-to-fine, multi-stage pipeline. First, a Global Structure Reasoning step divides the image into small patches and uses a transformer—a model originally developed for language—to understand how distant parts of the mural relate to one another. By modeling long-range connections without the usual information loss from heavy quantization, this stage builds a detailed, global blueprint of the mural’s structure. Next, a Semantic–Stylistic Consistency stage brings in two kinds of high-level guidance: it segments the image into meaningful regions (such as faces, robes, or background) and, using a pre-trained network, learns the characteristic textures and colors of each region. Finally, a Flow-Guided Refinement stage treats restoration as a gradual evolution, using a learned “velocity field” to nudge the initial guess toward a visually coherent final result over multiple small steps.
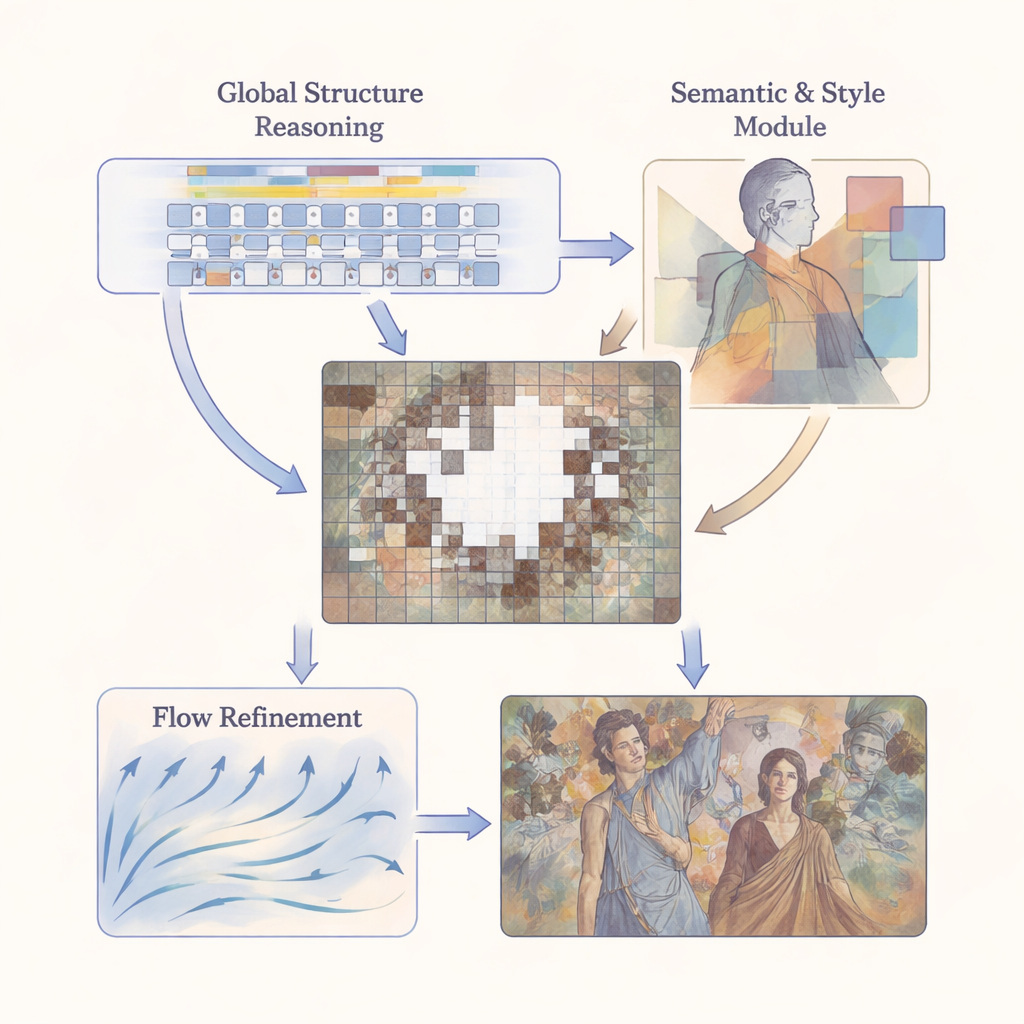
Keeping Structure and Style in Harmony
A central idea of the work is that content and style must be handled together but not confused. The model’s semantic component, based on a powerful segmentation system known as Mask2Former, tells the network where different elements of the scene begin and end. On top of this, the style component measures how closely the restored regions match the original in each semantic area, using a layered comparison of feature patterns (via Gram matrices) across multiple scales. This allows the system to treat a figure’s face differently from a patterned robe or a cloudy sky, instead of applying one global style rule that would wash out local differences. At the refinement stage, semantic masks act like guardrails for the flow field, ensuring that filled-in pixels evolve in ways that remain consistent with both structure and style.
Putting the Method to the Test
To see how well M3SFormer works in realistic settings, the authors assembled two large datasets: one of Chinese murals from several regions and another of traditional landscape paintings. They simulated damage using masks modeled on real cracks and missing fragments, then compared their method to seven state-of-the-art alternatives, including both transformer- and diffusion-based systems. Across standard measures of image quality, structural similarity, and perceptual realism, M3SFormer consistently came out on top, especially when the damaged area was large and complex. Visual comparisons show that it avoids the blurring, odd color patches, and noisy speckles that plague many competing methods, while still running at a practical speed for real-world use.
Limits, Lessons, and Future Possibilities
Despite its strengths, M3SFormer is not a magical cure-all. When confronted with very large missing regions or highly intricate designs, it can still hallucinate details that clash with historical reality—an important warning for conservators who must always keep the line between plausible reconstruction and speculation in mind. The authors suggest that future versions should incorporate explicit prompts, such as sketches or short text descriptions, to keep the model’s imagination anchored. Even with these caveats, the approach offers a powerful new toolkit for museums and researchers: a way to generate detailed, stylistically faithful digital reconstructions, explore “what-if” restorations non-invasively, and help ensure that fragile cultural treasures can be studied and appreciated long after the original pigments have faded.
Citation: Hu, Q., Ge, Q., Zhang, Y. et al. M3SFormer: multi-stage semantic and style-fused transformer for mural image inpainting. npj Herit. Sci. 14, 64 (2026). https://doi.org/10.1038/s40494-026-02325-w
Keywords: digital mural restoration, image inpainting, cultural heritage, transformer models, art conservation