Clear Sky Science · en
Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus
Why Old Chronicles Matter in the Age of AI
For more than two millennia, Chinese historians recorded wars, courts, famines, and everyday life in the massive series known as the Twenty-Four Histories. Today, these classics are being rediscovered not just by scholars, but by computers. This study describes how researchers turned these ancient chronicles and their modern Chinese translations into a carefully labeled language database. That resource can help artificial intelligence read, translate, and analyze historical texts more accurately—and make the distant past far more accessible to the public.
From Dusty Volumes to Digital Text
The project begins with a basic but daunting task: turning millions of printed characters into clean, accurate digital text. The team drew on two sources—a definitive modern edition of the Twenty-Four Histories and a large online collection—to feed an optical character recognition system. They then painstakingly removed garbled passages, fixed misread characters, and stripped away noise such as page headers and footers. The result was a parallel set of files, one in ancient Chinese and one in modern Chinese, that faithfully matched the original books but were ready for computational analysis. 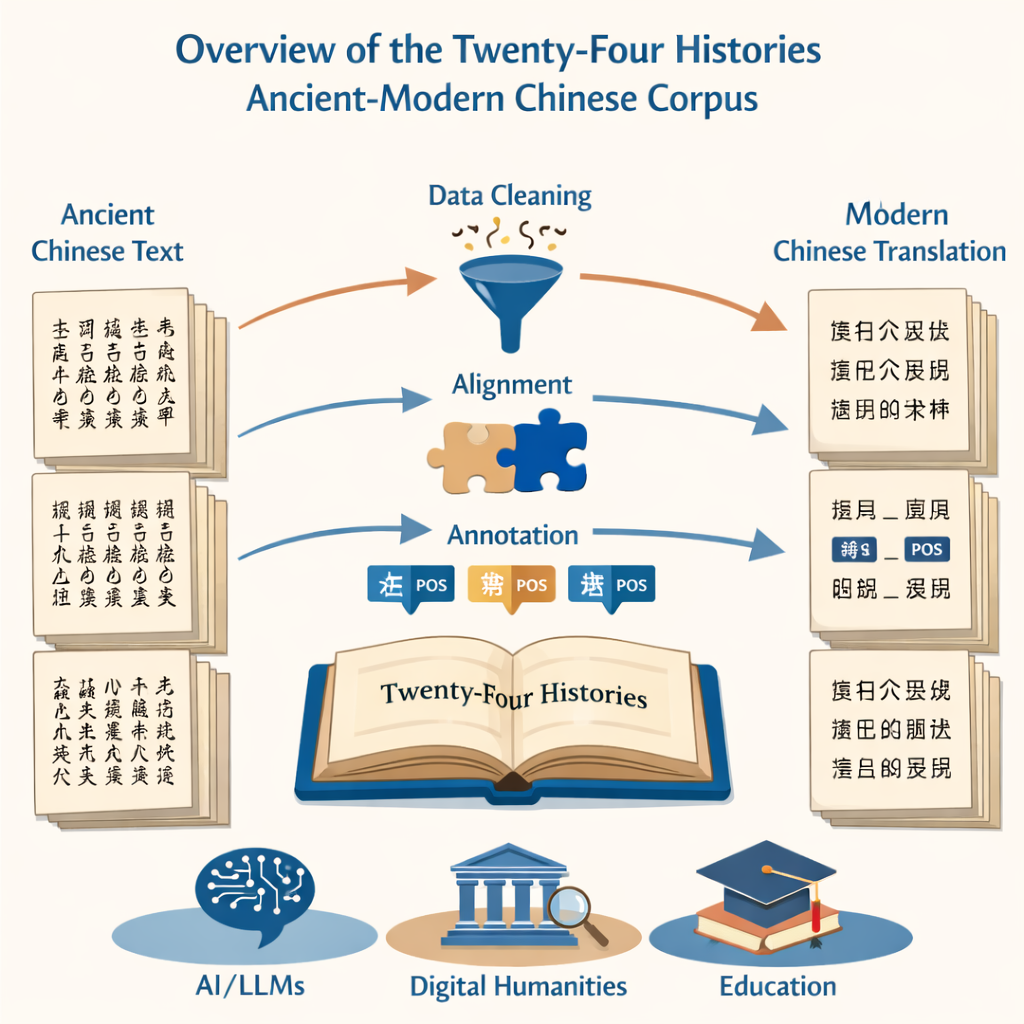
Pairing Ancient Sentences with Modern Ones
Because the aim was to compare how language has changed across time, it was essential to line up the old and new versions sentence by sentence. The researchers used specialized alignment software to first match paragraphs, then break them into corresponding sentences. Automated tools did the heavy lifting, but human experts had to review each suggested pair, since ancient Chinese grammar can be very different from modern Chinese. Where the software stumbled—splitting a thought in the wrong place or misreading a character—annotators checked the original scanned pages and corrected the digital text so that each ancient sentence lined up cleanly with its modern counterpart.
Teaching Computers to See Grammar
Beyond simple transcription, the core of the project is grammatical labeling. Every word in both the ancient and modern texts was marked with a part-of-speech tag, indicating whether it is, for example, a noun, verb, or time word. Because no single standard exists for ancient Chinese, the team anchored their system to modern national guidelines, then adapted them to older usage. They devised a 22-tag scheme that includes a special label for uniquely ancient verb uses such as “cause to live” or “die for the country.” A customized neural network—built on an ancient-text language model and sequence-labeling layers—produced initial tags, which were then checked and corrected by a large team of well-trained graduate students. Strict agreement tests between annotators showed very high consistency, confirming that the final tagged corpus is both large and reliable.
What the New Lens Reveals
With the tagged corpus in place, the authors examined some of the patterns it makes visible. In ancient Chinese, single-character words dominate, reflecting a famously compact writing style, whereas modern Chinese favors two-character words. The most common ancient items are small grammatical particles such as “之” and “以,” while verbs and ordinary nouns together make up about half of all words in both time periods. The data also show which words tend to appear together—for example, structures that describe officials, armies, or diplomatic missions. By comparing tags across the ancient–modern pairings, the team traced how functions have shifted over time: some old prepositions and adverbs now correspond to full modern verbs, and some verbs solidified into fixed titles or legal terms. One case study pulled out all place names and mapped where they cluster in different dynasties, revealing how political and economic centers moved from the northwest to the lower Yangtze region and beyond. 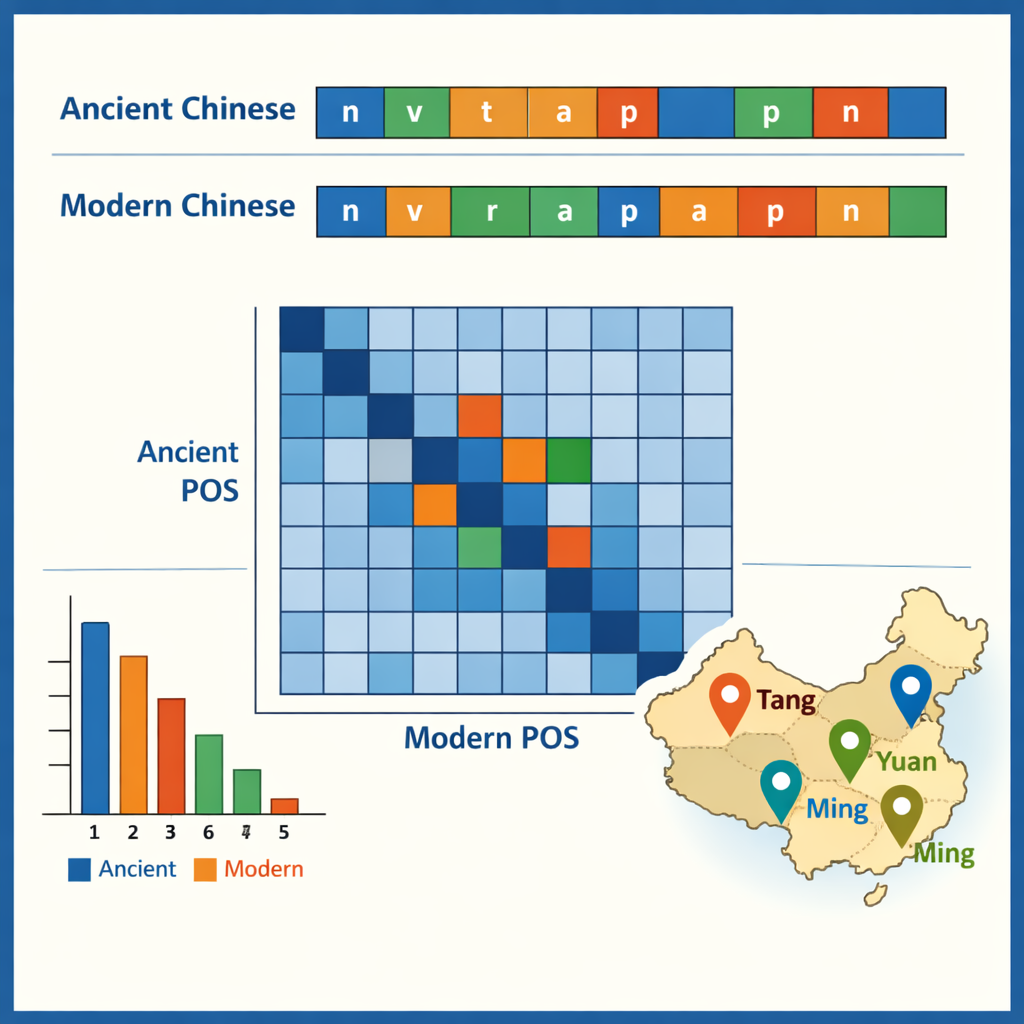
Bringing the Past into the Digital Future
In plain terms, this project turns a towering wall of classical prose into structured data that both humans and machines can navigate. For historians and linguists, it provides a powerful tool to track how words, grammar, and even state boundaries evolved across centuries. For AI developers, it offers high-quality training material to build language models that can actually handle classical Chinese instead of treating it as a jumble of characters. And for students and general readers, the sentence-by-sentence pairing of ancient and modern text lowers the barrier to reading the classics. By carefully labeling and aligning the Twenty-Four Histories, the authors have created a bridge from the handwritten scrolls of the past to the intelligent systems of the present and future.
Citation: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Keywords: ancient Chinese corpus, part-of-speech tagging, digital humanities, parallel texts, historical language change