Clear Sky Science · de
Systematische Bewertung und Richtlinien für das Segment Anything Model in der Analyse chirurgischer Videos
Warum intelligente Video‑Werkzeuge im Operationssaal wichtig sind
Moderne Chirurgie wird zunehmend durch Video unterstützt: winzige Kameras blicken in den Körper, während Chirurgen feine Instrumente auf einem Bildschirm steuern. Diese reichen, aber oft unordentlichen Videos in klare, beschriftete Karten von Instrumenten und Geweben zu verwandeln, könnte Operationen sicherer machen, die Ausbildung verbessern und künftige robotische Assistenz zuverlässiger gestalten. Diese Studie nimmt ein leistungsfähiges, allgemein einsetzbares Sehsystem — ursprünglich an Alltagsvideos trainiert — und stellt eine einfache, aber wichtige Frage: Kann es im menschlichen Körper gut genug „sehen“, um in realen Operationen nützlich zu sein, ohne von Grund auf mit teuren medizinischen Daten neu trainiert zu werden? 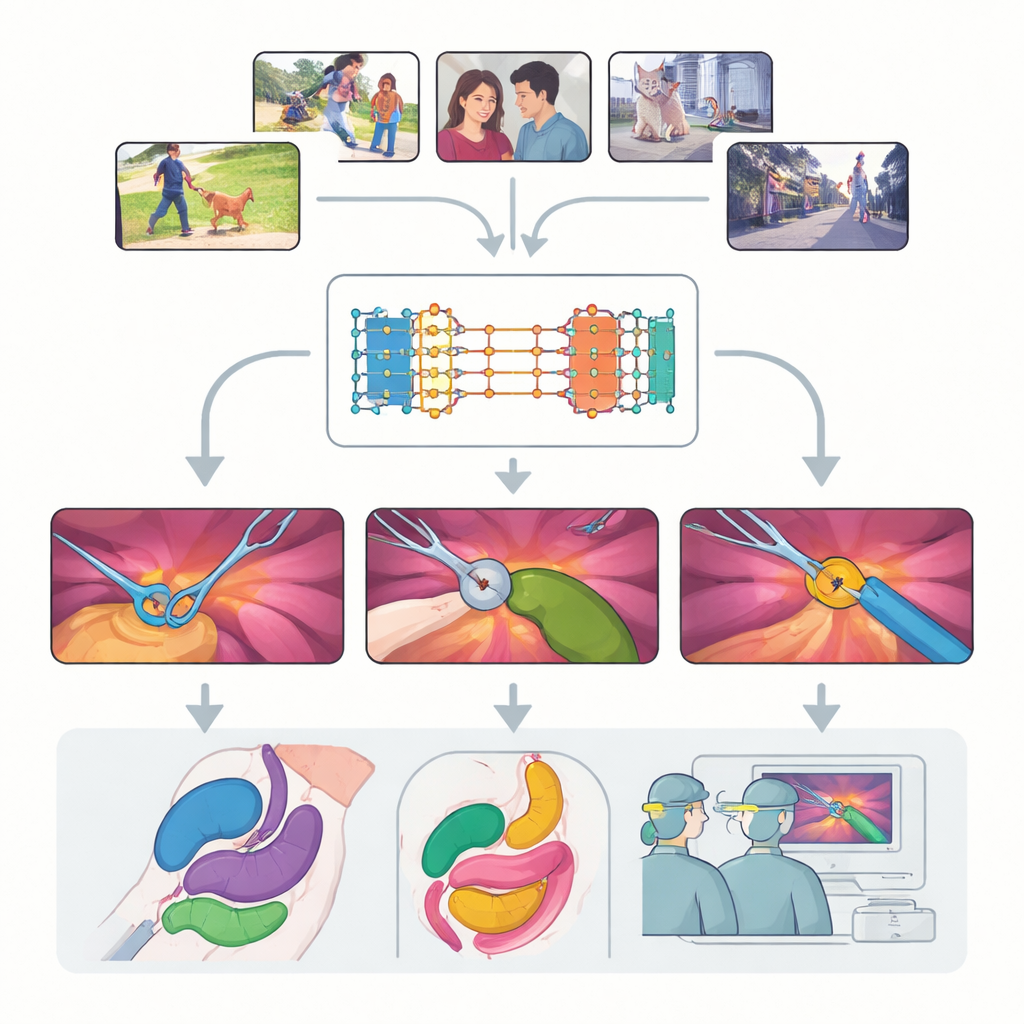
Ein flexibles Sehwerkzeug für jede Szene
Im Mittelpunkt steht das Segment Anything Model 2 (SAM2), ein großes KI‑System, das Objekte in Videos erkennen kann, sobald es einen Hinweis oder „Prompt“ erhält, worauf es achten soll. Anders als traditionelle Modelle, die feste Kategorien lernen, ist SAM2 klassenagnostisch: Es ist gleichgültig, ob ein Objekt ein Hund, ein Auto oder eine chirurgische Zange ist, solange der Nutzer mit einem Punkt, einem Rahmen oder einer Beispielmaske darauf zeigt. Ein entscheidender Fortschritt in SAM2 ist sein Speicher, der sich merkt, wie ein Objekt in früheren Frames aussah, und dieses Gedächtnis nutzt, um es über die Zeit zu verfolgen. Das macht SAM2 besonders vielversprechend für chirurgische Videos, in denen Instrumente ein‑ und ausgehen und Gewebe sich ständig verformt.
Das Modell über viele Operationen hinweg testen
Die Autoren führen eine groß angelegte, systematische Bewertung von SAM2 auf neun unterschiedlichen Datensätzen durch, die siebzehn Operationstypen abdecken — von laparoskopischer Gallenblasenentfernung über robotergestützte Prostatachirurgie bis zur Endoskopie. Sie untersuchen drei zentrale Herausforderungen: das Verfolgen von Instrumenten, die Segmentierung mehrerer Organe und das Verstehen von Szenen, in denen Instrumente und Gewebe gemischt auftreten. Für jede Aufgabe testen sie verschiedene Arten von Prompts — einzelne Punkte, mehrere Punkte, Begrenzungsrahmen und vollständige Masken — und erforschen, wie oft die Prompts während des Videos aktualisiert werden müssen. Außerdem vergleichen sie das einsatzbereite Modell mit mehreren leichten Nachtrainingsverfahren auf chirurgischen Bildern, um zu sehen, wie weit sich die Leistung ohne große neue Datensätze steigern lässt.
Was im Körperinneren am besten funktioniert
Insgesamt erweist sich SAM2 in dieser ungewohnten Umgebung überraschend leistungsstark. Ohne chirurgisches Nachtraining segmentiert es bereits Instrumente und viele Organe wettbewerbsfähig im Vergleich zu spezialisierten medizinischen Modellen, besonders wenn es reichhaltige Prompts wie Rahmen oder Masken erhält. Das periodische „Reinitialisieren“ der Prompts alle 30 Frames — also das regelmäßige Erinnern des Systems daran, was wo ist — verbessert das Tracking über lange, komplexe Clips deutlich. Wenn die Forschenden nur bestimmte Teile von SAM2 feinabstimmen, etwa das Modul, das Prompts in Masken übersetzt, steigt die Genauigkeit bei Multi‑Organ‑Szenen stark an, während der Trainingsaufwand moderat bleibt. Im Gegensatz dazu kann das Anpassen des gesamten Bildkodierers mit begrenzten chirurgischen Daten die Leistung sogar verschlechtern, was darauf hindeutet, dass das meiste von SAM2s allgemeinem visuellen Wissen unangetastet bleiben sollte. 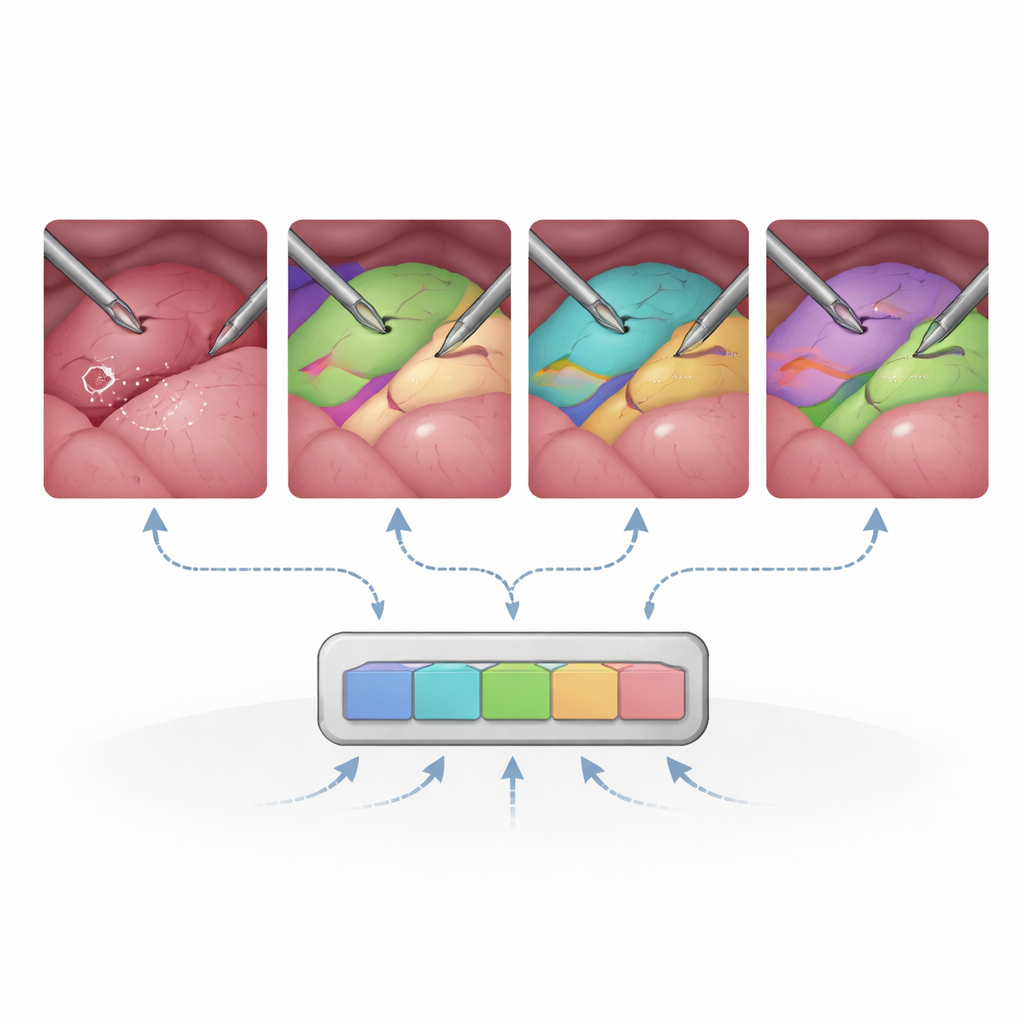
Grenzen bei unordentlichen, schnell wechselnden Szenen
Die Studie zeigt auch deutliche Schwachstellen auf. SAM2 hat Schwierigkeiten, wenn das Kamerabild eng ist, das Bild verrauscht oder schlecht beleuchtet ist oder Gewebe keine scharfen Konturen aufweist, wie es bei einigen endoskopischen Eingriffen der Fall ist. Feine verzweigte Strukturen wie Blutgefäße und Gänge sind schwer zu trennen, wenn sie sich überlappen oder dieselbe grobe Kontur teilen. Die Nutzung des Videogedächtnisses hilft nicht immer: In hochdynamischen Szenen mit schnellen Kamerabewegungen können die zeitlichen Hinweise das Modell eher in die Irre führen als stabilisieren. Diese Befunde unterstreichen, dass ein allgemeines Foundation‑Modell zwar weit kommen kann, manche chirurgischen Realitäten aber domänenspezifisches Tuning und eine bessere Handhabung von Bewegungs‑ und Erscheinungsänderungen erfordern.
Richtlinien für künftige intelligente Chirurgiesysteme
Aus diesen umfangreichen Tests destillieren die Autoren praktische Empfehlungen für Forschende und Kliniker, die SAM2 in chirurgischen Projekten einsetzen wollen. Sie empfehlen, mit Masken‑ oder Box‑Prompts zu beginnen und einfache, bildbasierte Feinabstimmungen zu bevorzugen, die sich auf den Masken‑Decoder konzentrieren, bei langen Videos periodische Prompt‑Aktualisierungen einzuführen und komplexere, videobasierte Trainings nur dann zu verfolgen, wenn die Szenen relativ stabil sind. Sie zeigen, dass selbst spärlich annotierte Clips — nur einige Frames beschriftet — ausreichen können, um das Modell effektiv anzupassen. Kurz gesagt fällt das Fazit ermutigend aus: Ein einziges, breit trainiertes Sehmodell kann viele verschiedene chirurgische Segmentierungsaufgaben übernehmen und reduziert so erheblich den Bedarf, für jedes Verfahren ein neues Werkzeug zu entwickeln. Mit durchdachtem Prompting und leichter Anpassung könnten Systeme wie SAM2 zu leistungsfähigen Bausteinen für die nächste Generation von chirurgischer Navigation, Automatisierung und Trainingswerkzeugen werden.
Zitation: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Schlüsselwörter: Analyse chirurgischer Videos, Bildsegmentierung, Foundation-Modelle, computerunterstützte Chirurgie, medizinische KI