Clear Sky Science · de
Die Lücke zwischen Computermodellen und Experimenten überbrücken: Nutzung großer Sprachmodelle zur Priorisierung von Alzheimer-Therapeutika basierend auf dem Vergleich von Lernmodellen
Warum das für Familien und Patientinnen und Patienten wichtig ist
Die Alzheimer-Krankheit raubt Menschen Erinnerungen, Selbstständigkeit und Lebensqualität, und wirklich wirksame Behandlungen sind nach wie vor rar. Diese Studie untersucht einen schnelleren Weg, neue Therapien mithilfe bereits vorhandener Medikamente zu finden: durch die Kombination leistungsfähiger Computer‑Modelle mit einem großen Sprachmodell — derselben KI‑Art, die inzwischen in Alltags‑Chatbots verwendet wird — um riesige Mengen medizinischer Daten und Forschungsliteratur zu durchforsten. Ziel ist es, eine lange Liste potenzieller Wirkstoffe auf eine kleine, realistische Auswahl zu reduzieren, die Wissenschaftler und Ärztinnen tatsächlich an Patientinnen und Patienten testen können.
Alte Medikamente für einen neuen Zweck nutzen
Die Entwicklung eines völlig neuen Medikaments kann mehr als ein Jahrzehnt dauern und Milliarden kosten, ohne Erfolgsgarantie. Eine Alternative ist die „Wirkstoff‑Repositionierung“, bei der nach neuen Anwendungsgebieten für bereits zugelassene Medikamente gesucht wird, etwa solche, die gegen Parkinson oder Depression eingesetzt werden. Da diese Arzneien bekannte Sicherheitsprofile haben, können sie oft schneller in klinische Studien für Alzheimer überführt werden. Moderne Computerverfahren, die biologische Datenbanken und die medizinische Literatur durchsuchen, erzeugen heute jedoch sehr umfangreiche Kandidatenlisten — weit mehr, als Forschende manuell sinnvoll prüfen können — und schaffen damit einen neuen Engpass im Prozess.
Mehrere intelligente Modelle zusammenbringen
Das Forschungsteam ging dieses Problem an, indem es einen Rahmen für die Alzheimer‑Wirkstoff‑Repositionierung aufbaute, der mit drei unterschiedlichen fortgeschrittenen Computermodellen startet. Jedes Modell untersucht eine große biomedizinische „Landkarte“, einen Wissensgraphen, der Krankheiten, Medikamente, Gene und andere medizinische Konzepte verknüpft, und schlägt Arzneien vor, die bei Alzheimer helfen könnten. Da jedes Modell Muster anders erkennt, überschneiden sich die Listen nicht vollständig. Die Autorinnen und Autoren kombinierten die jeweils 30 besten Vorschläge der Modelle zu einem Pool von 90 Kandidaten und setzten dann ein großes Sprachmodell (LLM) als automatisierten, aber zurückhaltenden Gutachter ein, das veröffentlichte Studien zu jedem Wirkstoff liest und einschätzt, ob die Belege für Alzheimer hilfreich, neutral oder schädlich erscheinen.
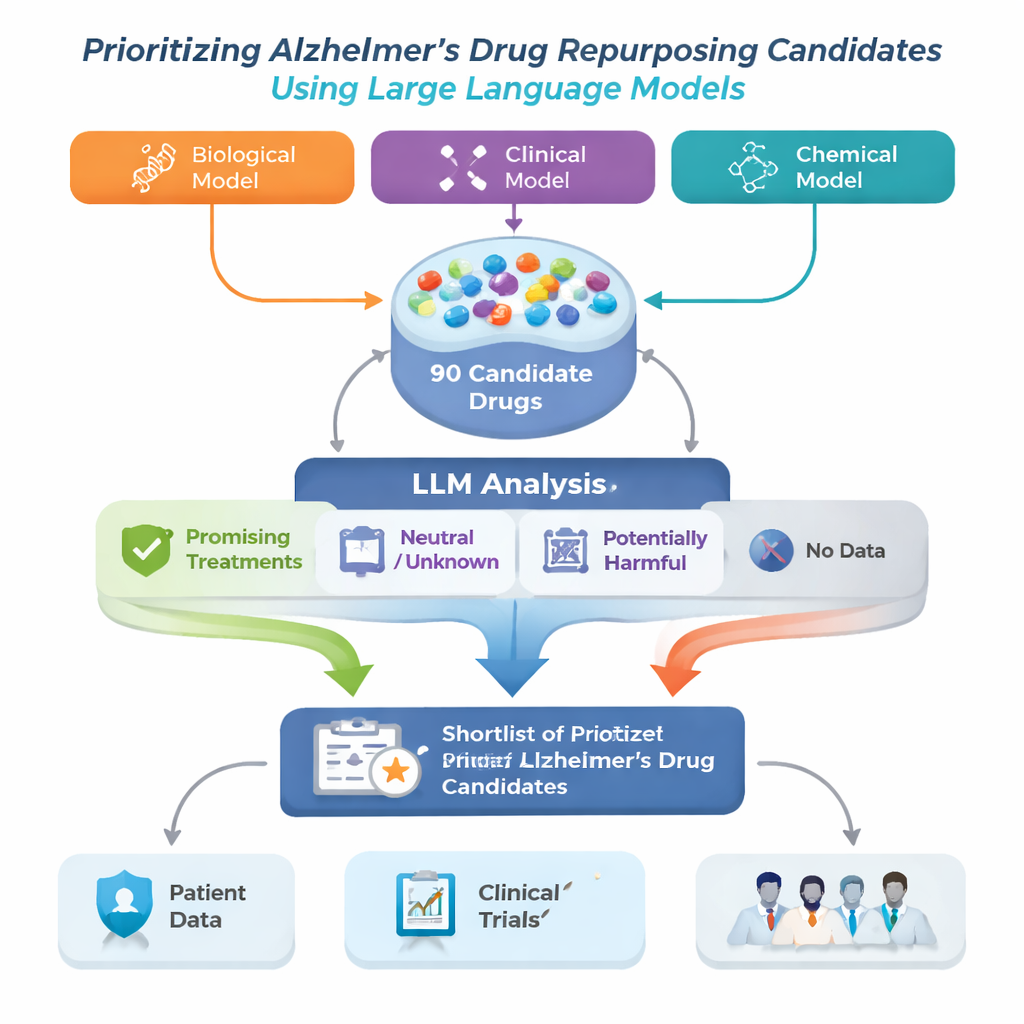
Wie die KI die medizinische Literatur liest
Für jeden Kandidaten zog das System bis zu 200 wissenschaftliche Abstracts aus PubMed sowie detaillierte Arzneibeschreibungen aus einer pharmazeutischen Datenbank heran. Das LLM wurde angewiesen, sein Urteil ausschließlich auf den ihm gezeigten Text zu stützen und jedes Abstract als positiv, neutral oder negativ im Hinblick auf eine Alzheimer‑Behandlung zu kennzeichnen. Diese Labels wurden dann in einfache Scores umgewandelt: der Anteil der Abstracts, die positiv, neutral oder negativ waren. Mithilfe von zwei Regelsets — einem strengeren, das klare positive Belege verlangte, und einem nachsichtigeren, das bereits jeden Hinweis auf Nutzen erfasste — sortierte das Framework die Medikamente in vier Gruppen: vielversprechende Behandlungen, potenziell schädliche, unklare oder neutrale und Medikamente ohne überhaupt vorhandene Alzheimer‑bezogene Publikationen. Letztere Gruppe, obwohl wenig untersucht, könnte besonders neuartige Chancen bergen.
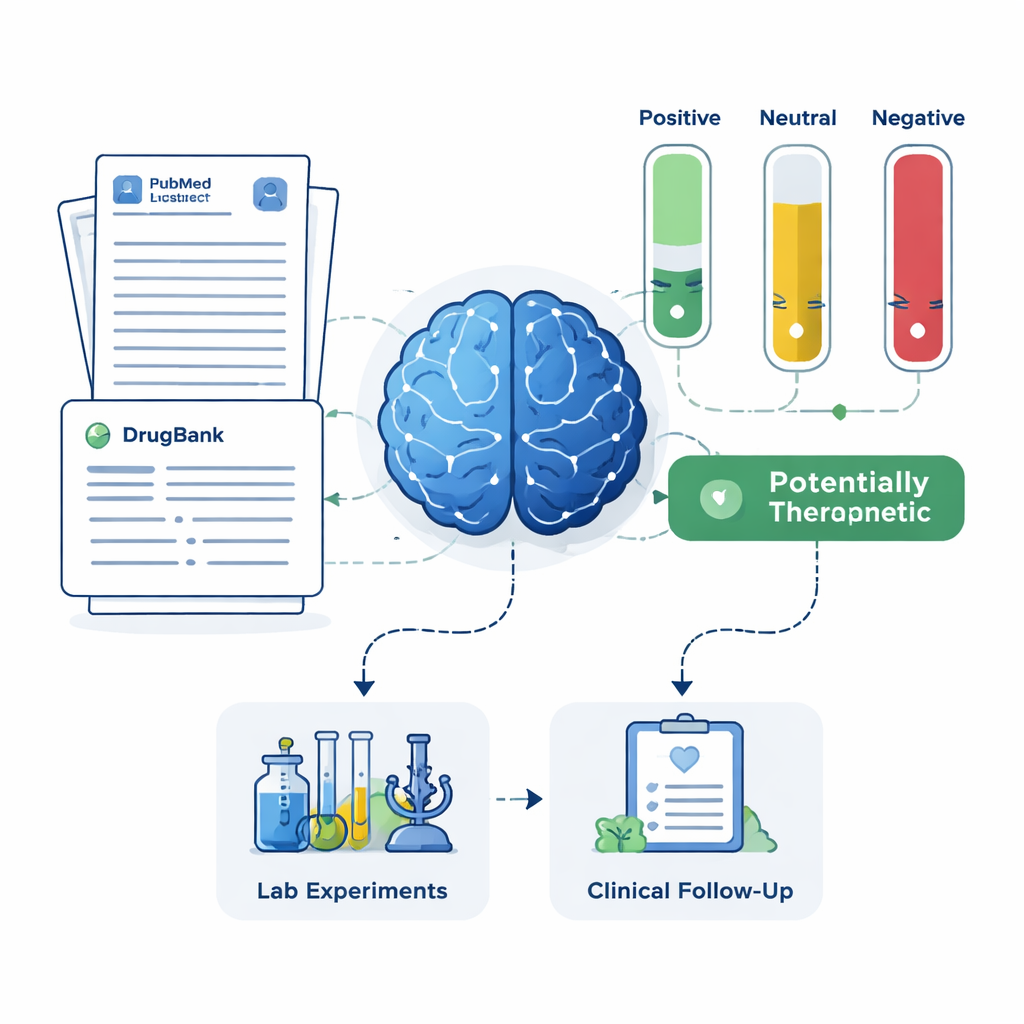
Abgleich mit realen Patientendaten und klinischen Studien
Um zu prüfen, ob die Kurzliste der KI in der Realität Sinn machte, verglich das Team die Ergebnisse mit zwei unabhängigen Quellen: einem großen Alzheimer‑Patientenregister und Aufzeichnungen registrierter klinischer Studien. Das Framework fand erfolgreich Memantin wieder — ein bestehendes Alzheimer‑Medikament mit starken Schutzsignalen in Patientendaten und umfangreicher Studienhistorie — als hochprioritären Kandidaten. Es hob außerdem Wirkstoffe wie Magnesium, Minocyclin, Pimavanserin, Testosteron und Doxycyclin hervor, die unterschiedlich stark durch Forschung gestützt sind, aber von klinischen Expertinnen und Experten als vielversprechend angesehen wurden. Gleichzeitig identifizierte das System Medikamente, deren Literatur auf mögliche Schäden oder fehlenden Nutzen hindeutete, und empfahl, diese zu depriorisieren oder eher auf Nebenwirkungen statt auf Behandlungspotenzial hin zu untersuchen.
Von Computerprognosen zu praktischen nächsten Schritten
Alltagsnah formuliert wirkt dieses Framework wie ein extrem schneller, sorgfältiger Forschungsassistent, der tausende Papers liest, Muster in großen medizinischen Datenbanken kreuzprüft und menschlichen Expertinnen und Experten eine deutlich kürzere, besser strukturierte Liste von Alzheimer‑Medikamentkandidaten übergibt, auf die sie sich konzentrieren können. Die Studie zeigt, dass durch die Kombination unterschiedlicher KI‑Typen — graphbasierte Modelle zur Generierung von Ideen und ein Sprachmodell zur Bewertung der Evidenz — Forschende sowohl gut gestützte Medikamente als auch interessante neue Optionen für Tests schneller finden können. Zwar heilt dieser Ansatz Alzheimer nicht von selbst, doch er bietet eine leistungsfähige neue Methode, computergenerierte Ideen mit der mühsamen Arbeit von Laborversuchen und klinischen Studien zu verbinden und damit den Weg zu wirksameren Behandlungen potenziell zu beschleunigen.
Zitation: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
Schlüsselwörter: Alzheimer-Krankheit, Wirkstoff-Repositionierung, künstliche Intelligenz, große Sprachmodelle, Wissensgraphen