Clear Sky Science · de
3D-Magischer Spiegel: Rekonstruktion von Kleidung aus einem einzelnen Bild aus kausaler Perspektive
Anprobieren ohne Umkleidekabine
Stellen Sie sich vor, Sie machen mit dem Handy ein einziges Ganzkörperfoto und sehen sich sofort in 3D: Sie können das Bild drehen, Blickwinkel ändern oder sogar Outfits mit einer Freundin tauschen. Dieses Paper adressiert das zentrale technische Problem hinter diesem „3D-Magischen Spiegel“: aus einem gewöhnlichen 2D-Foto einer bekleideten Person ein detailliertes 3D-Modell der Kleidung zu erzeugen, ohne auf teure 3D-Scans oder kontrollierte Studioaufnahmen angewiesen zu sein.
Warum die Umwandlung von 2D zu 3D so knifflig ist
Aus einem flachen Bild ein 3D-Objekt zu machen, ist ein klassisches Rätsel. Bestehende Systeme starten oft mit einer festen digitalen Körpervorlage und verformen diese, um zum Bild zu passen. Das funktioniert recht gut für starre Körperteile wie Arme und Beine, versagt aber bei wallenden Kleidern, umgelegten Mänteln, Haaren oder Handtaschen, die keiner einfachen Standardform folgen. Ein weiteres Problem ist die Datenlage: Es gibt Millionen Modefotos im Netz, aber kaum große Sammlungen präzise vermessener 3D-Kleidungsstücke für das Training. Schließlich verschleiert ein einzelnes Foto wichtige Informationen. Ein kurzer Mantel nahe an der Kamera kann identisch aussehen mit einem größeren Mantel weiter entfernt; Beleuchtung und Stoffmuster können ein Lernsystem zusätzlich täuschen. Solche Mehrdeutigkeiten erschweren es einem neuronalen Netzwerk, die korrekte 3D-Struktur abzuleiten.
Der KI beibringen, Ursache und Wirkung zu trennen
Statt das Problem als Blackbox-Abbildung von Pixeln zu 3D zu behandeln, entlehnen die Autoren Ideen aus der Kausalitätstheorie — der Mathematik von Ursache und Wirkung. Sie betrachten das finale Bild als Ergebnis von vier verborgenen Ursachen: Kameraposition, Kleidungsform, Textur (Farben und Muster) und Beleuchtung. Eine spezielle „strukturelle kausale Karte“ legt dar, wie diese Faktoren zusammenspielen, um das beobachtete Bild zu erzeugen. Angeleitet von dieser Karte nutzt das System vier separate neuronale Encoder, von denen jeder für einen Faktor zuständig ist. Zusammen mit einem physik-inspirierten 3D-Renderer bilden sie einen Zyklus: Bild und Vordergrundmaske gehen rein, ein koloriertes 3D-Mesh kommt raus und wird dann zurück in ein Bild projiziert, das mit dem Original verglichen werden kann.
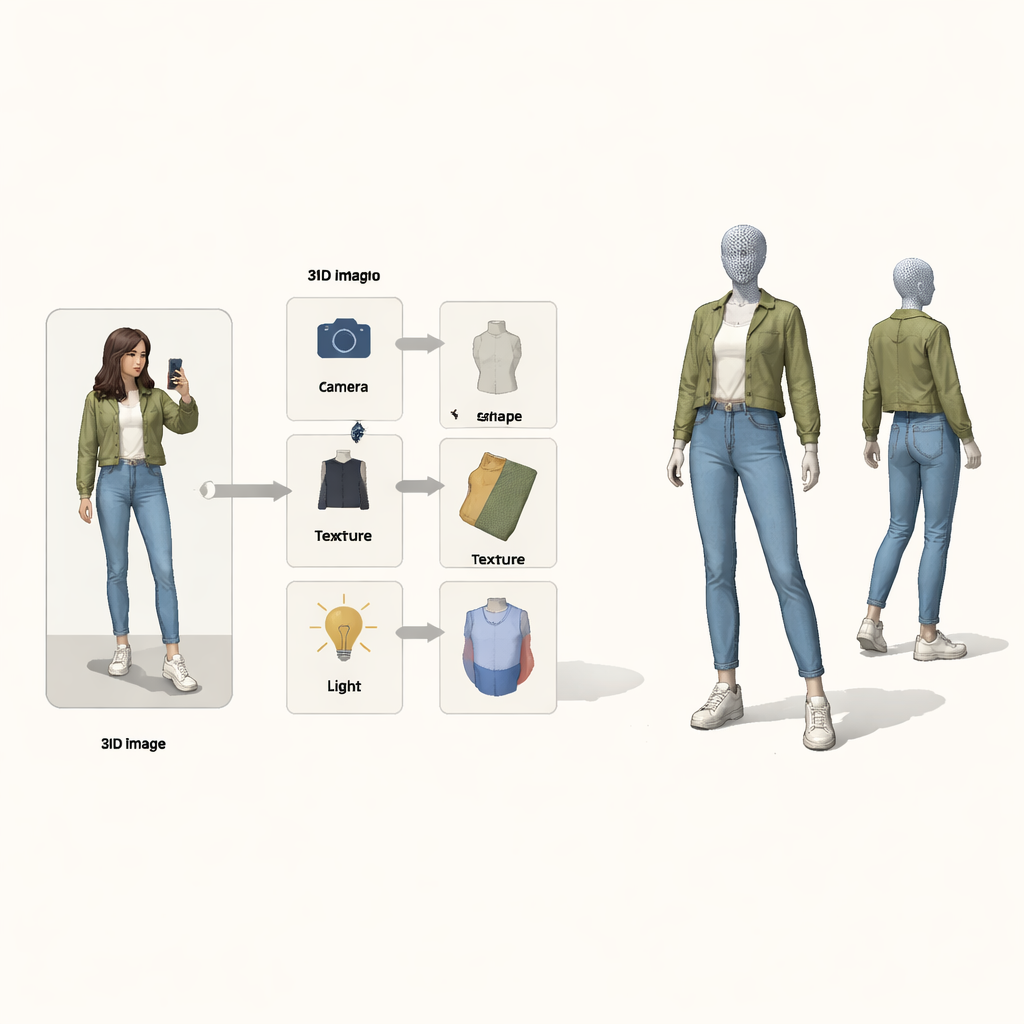
Eine Lernschleife, die jeweils nur ein Problem behebt
Auch mit separaten Encodern kann das Training scheitern. Wenn die Rekonstruktion unvollkommen ist, ist unklar, welcher Encoder schuld ist, und normales Lernen tendiert dazu, alle gleichzeitig anzupassen. Die Autoren sehen hierin ein klassisches „Collider“-Problem der Kausalität, bei dem verschiedene Ursachen sich fälschlich gegenseitig kompensieren können. Ihre Lösung ist, zwei Erwartungs–Maximierungs-Schleifen in das Training einzuflechten. In der ersten Schleife werden drei Encoder vorübergehend eingefroren, während nur der vierte aktualisiert wird, sodass Fehler klar zugeordnet werden und diese Komponente eine sauberere Rolle lernt. In der zweiten Schleife wird eine gemeinsame „Prototyp“-3D-Form — anfangs eine einfache Kugel — schrittweise so angepasst, dass sie zum durchschnittlichen Menschen- bzw. Vogelkörper in den Daten wird. Einzelne Beispiele lernen dann nur kleine Abweichungen von diesem Prototyp, während das Kameramodul die volle Verantwortung dafür übernimmt, wie groß oder nah das Objekt erscheint und damit direkt die Verwechslung zwischen Größe und Entfernung bekämpft.
Von Modefotos zu Vögeln und weiter
Um ihren Ansatz zu testen, trainieren die Forschenden auf zwei großen Modedatensätzen mit gewöhnlichen Straßenfotos und auf einer Standardkollektion von Vogelbildern. Wichtig ist, dass sie nur 2D-Vordergrundmasken verwenden, nicht 3D-Ground-Truth-Meshes. Bei menschlicher Kleidung übertrifft ihr System gängige Methoden mit Körpervorlagen darin, die wahre Silhouette von Kleidungsstücken genauer zu treffen, und geht mit nicht-starren Elementen wie Haaren und Handtaschen fideler um. Bei Vögeln erreicht es die Qualität führender Single-Image-3D-Rekonstruktionsmethoden oder übertrifft diese und erzeugt realistischere neue Blickwinkel. Die 3D-Modelle sind flexibel genug für spielerische Anwendungen, etwa das Tauschen von Stofftexturen zwischen Personen oder das Generieren synthetischer Trainingsdaten zur Verbesserung von Person-Re-Identifikationssystemen in der Überwachungsforschung.
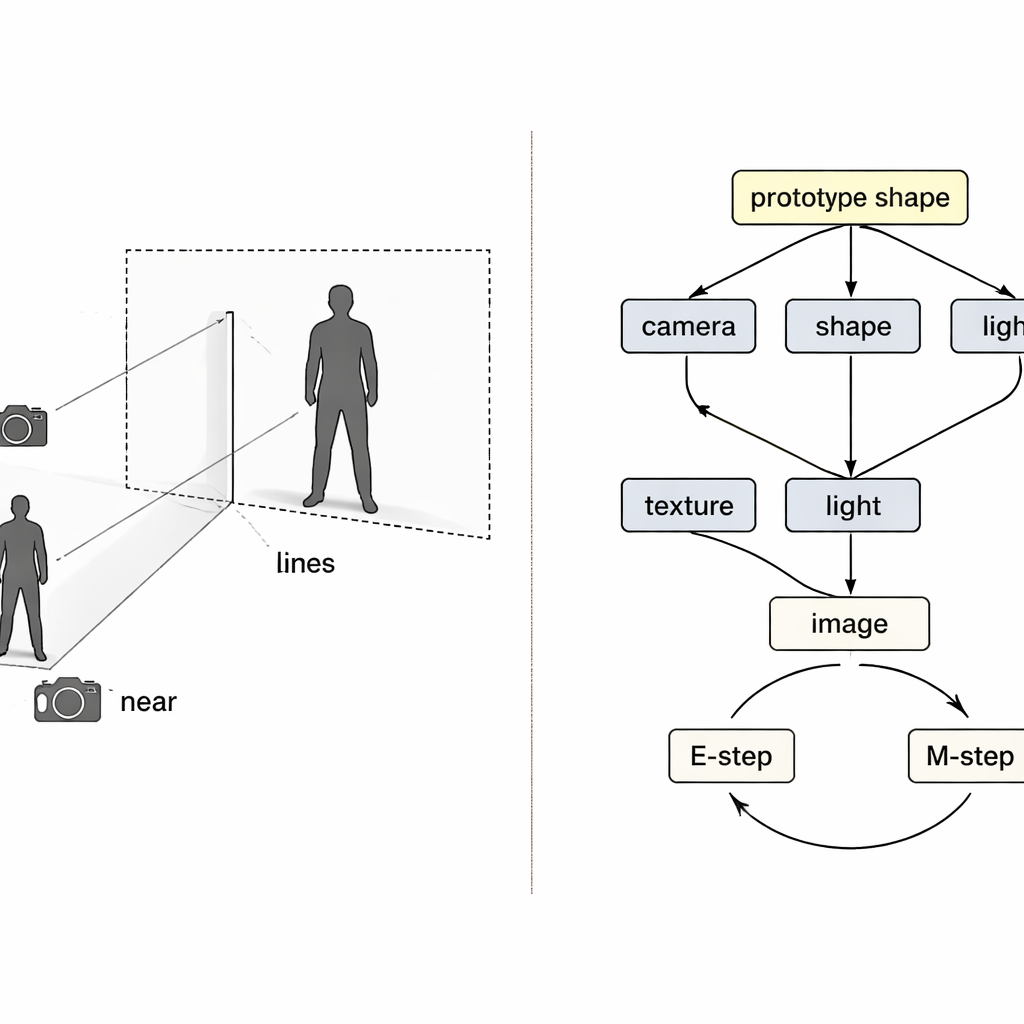
Was das für alltägliche digitale Welten bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft: Überzeugende 3D-Avatare und virtuelle Anproben erfordern nicht länger teure 3D-Scanner oder starre Vorlagen. Indem Ursache und Wirkung explizit modelliert werden — durch Trennung von Kamera, Form, Textur und Licht und Verankerung an einem gemeinsamen Prototyp — zeigen die Autoren, wie ein System ein einzelnes Foto als 3D-Szene „erklären“ kann. Zwar hat die Methode weiterhin Schwierigkeiten mit nie gesehenen Ansichten, etwa dem Rücken einer Person, die nur von vorne fotografiert wurde, doch stellt sie einen wichtigen Schritt hin zu praktischen 3D-Magischen Spiegeln dar, die mit den unordentlichen, realen Bildern funktionieren, die wir tatsächlich aufnehmen.
Zitation: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Schlüsselwörter: virtuelles Anprobieren, 3D-Rekonstruktion, kausales Lernen, Computer Vision, Mode-KI