Clear Sky Science · de
Menschliche und algorithmische visuelle Aufmerksamkeit bei Fahraufgaben
Warum das für den Alltag am Steuer wichtig ist
Wenn Autos immer mehr automatisiert werden, bleibt eine zentrale Frage: Sehen selbstfahrende Systeme die Straße wirklich so wie Menschen? Diese Studie untersucht, wie menschliche Fahrer und künstliche Intelligenz ihre visuelle Aufmerksamkeit im Verkehr fokussieren, und zeigt, dass das gezielte Einfügen eines menschenähnlichen Aufmerksamkeitsanteils Fahralgorithmen sowohl intelligenter als auch sicherer machen kann — ohne riesige, energieintensive KI‑Modelle.
Wie sich menschliche Augen auf der Straße bewegen
Die Forschenden setzten zunächst Anfänger und erfahrene Fahrer in eine simulierte Fahrumgebung und verfolgten ihre Augenbewegungen, während sie drei gängige Sicherheitsaufgaben ausführten: Gefahren erkennen, beurteilen, ob es sicher ist abzubiegen oder die Spur zu wechseln, und ungewöhnliche, fehlplazierte Objekte detektieren. Sie fanden heraus, dass die Aufmerksamkeit der Fahrer einem verlässlichen Dreiphasenrhythmus folgt. In der Scanning-Phase, unmittelbar nachdem eine Szene erscheint, gleiten die Augen weit über das Sichtfeld, vorwiegend gesteuert durch Lageinformationen. In der Examining-Phase fixiert sich die Aufmerksamkeit auf die einzelne informationsreichste Region — etwa einen querenden Fußgänger oder ein blockierendes Fahrzeug — und untersucht deren Details und Bedeutung. Schließlich vergleichen Fahrer in der Reevaluating-Phase dieses Schlüsselllement mit anderen Objekten und verschieben ihren Blick hin und her, um die Entscheidung zu bestätigen.
Wohin Maschinen schauen versus wohin Menschen schauen
Das Team baute dann ein auf Aufmerksamkeit basierendes Deep‑Learning‑Modell für Fahrszenen und verglich dessen interne „Aufmerksamkeitskarten“ mit denen aus menschlichen Augenbewegungen. Ein Training des Modells für allgemeine Objekterkennung machte seine Aufmerksamkeit etwas menschlicher, aber eine Feinabstimmung auf spezifische Fahraufgaben entfernte sie oft von menschlichen Mustern, besonders in der reichhaltigen, bedeutungsorientierten Examining‑Phase. Insgesamt blieben die Korrelationen zwischen menschlicher und algorithmischer Aufmerksamkeit moderat, was darauf hindeutet, dass heutige Fahr‑KI Schwierigkeiten hat, die ordnenden Prinzipien zu entdecken, die erklären, wohin Menschen schauen und warum.
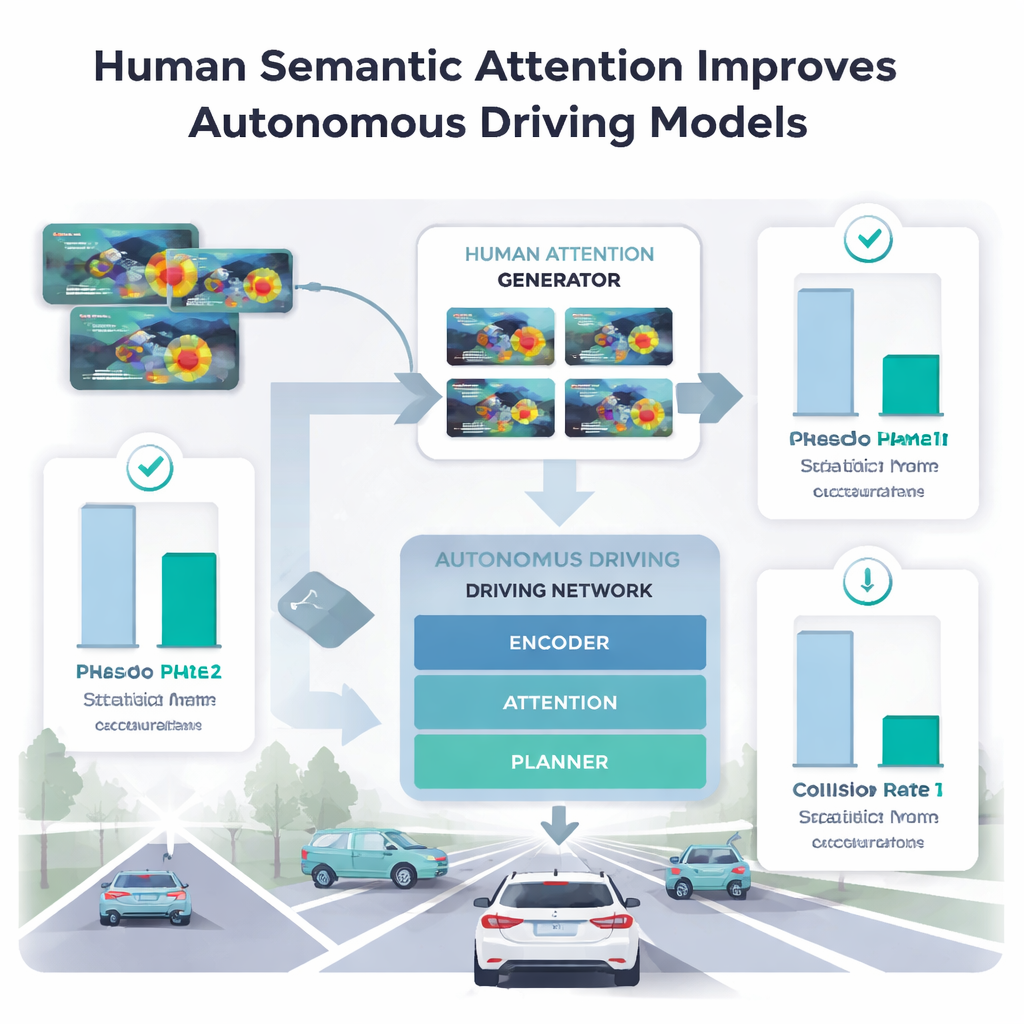
Autos beibringen, menschliche Fokussierung zu übernehmen
Um herauszufinden, welche Teile der menschlichen Aufmerksamkeit Maschinen tatsächlich helfen, fütterten die Autorinnen und Autoren verschiedene Phasen menschlichen Blickverhaltens in ihr Fahrmodell. Direktes Eye‑Tracking für Millionen von Bildern zu sammeln ist unpraktisch, also trainierten sie einen separaten „Human Attention Generator“ auf einer kleinen Stichprobe von nur fünf Fahrern. Dieser Generator lernte, menschenähnliche Aufmerksamkeits‑Heatmaps für neue Szenen vorherzusagen. Wenn das Hauptmodell nur die räumliche, frühe Scanning‑Phase nutzte, verschlechterte sich seine Leistung bei der Anomalieerkennung und Trajektorienplanung oft oder es erzeugte zwar „sicherer“ aussehende Bahnen, die aber kollisionsanfälliger waren. Im Gegensatz dazu verbesserte die Nutzung der Examining‑Phase — in der Menschen sich auf die einzelne bedeutungsvollste Region konzentrieren — die Genauigkeit gegenüber früheren Methoden, die Blickverläufe voller Länge nutzten, und die Kollisionsraten in Planungsaufgaben sanken.
Was große Vision‑Language‑Modelle noch vermissen
Die Forschenden testeten außerdem große Vision–Language‑Modelle, die Fahrfragen beantworten oder dichte Beschreibungen für 3D‑Straßenszenen erzeugen. Bei einer Frage‑Antwort‑Aufgabe, die auf abstraktes, übergeordnetes Denken abzielt, half das Hinzufügen menschlicher Aufmerksamkeit kaum und schadete manchmal sogar, was darauf hindeutet, dass solche Modelle bereits viel des benötigten abstrakten Wissens erfassen. Bei einer anspruchsvollen Captioning‑Aufgabe, die präzise Wörter präzisen Objekten zuordnen muss, lieferte die menschliche Examining‑Phase jedoch weiterhin große Vorteile. Das deutet darauf hin, dass große Modelle zwar generell gut schlussfolgern, aber noch straucheln, wenn es darum geht, Worte eng an exakt bestimmte Stellen einer überladenen visuellen Szene zu binden — eine Lücke, die menschlicher Blick schließen kann.
Was das für sicherere automatisierte Autos bedeutet
Einfach gesagt argumentiert die Studie, dass der Unterschied zwischen Menschen und heutiger Fahr‑KI nicht nur darin liegt, wohin wir schauen, sondern wie wir sofort beurteilen, was wichtig ist in einer Szene. Dieser kompakte Ausbruch semantischer Aufmerksamkeit — wenn wir die eine Region prüfen, die eine Situation sicher oder gefährlich macht — ist genau das Signal, das vielen Algorithmen fehlt. Indem Systeme lernen, diese Phase aus einer kleinen Menge Eye‑Tracking‑Daten nachzuahmen, können Fahr‑Systeme ein menschenähnliches Verständnis von Straßenszenen gewinnen, ohne sich ausschließlich auf immer größere, teurere KI‑Modelle zu stützen. Diese „semantische Abkürzung“ könnte ein effizientes Mittel sein, künftige automatisierte Autos in den chaotischen, unvorhersehbaren Bedingungen des realen Verkehrs zuverlässiger zu machen.
Zitation: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
Schlüsselwörter: autonomes Fahren, visuelle Aufmerksamkeit, menschliches Eye-Tracking, Vision‑Language‑Modelle, Verkehrssicherheit