Clear Sky Science · de
Die Rolle großer Sprachmodelle in der Notfallmedizin: eine umfassende Benchmark-Studie
Warum das für alle wichtig ist, die die Notaufnahme aufsuchen könnten
Notaufnahmen sind geschäftiger denn je, mit längeren Wartezeiten und weniger Personal, um die wachsende Zahl kritisch kranker Patienten zu versorgen. Diese Studie stellt eine Frage, die nahezu jeden betrifft: Können moderne KI-Systeme, bekannt als große Sprachmodelle, Ärzten und Pflegekräften sicher dabei helfen, in der Notaufnahme schneller und klüger zu arbeiten? Indem mehrere führende KIs einer Reihe medizinischer Tests und simulierten Notfallfällen unterzogen werden, untersuchen die Forschenden, wie nah diese Werkzeuge daran sind, vertrauenswürdige „Co-Piloten“ in der Akutversorgung zu werden.
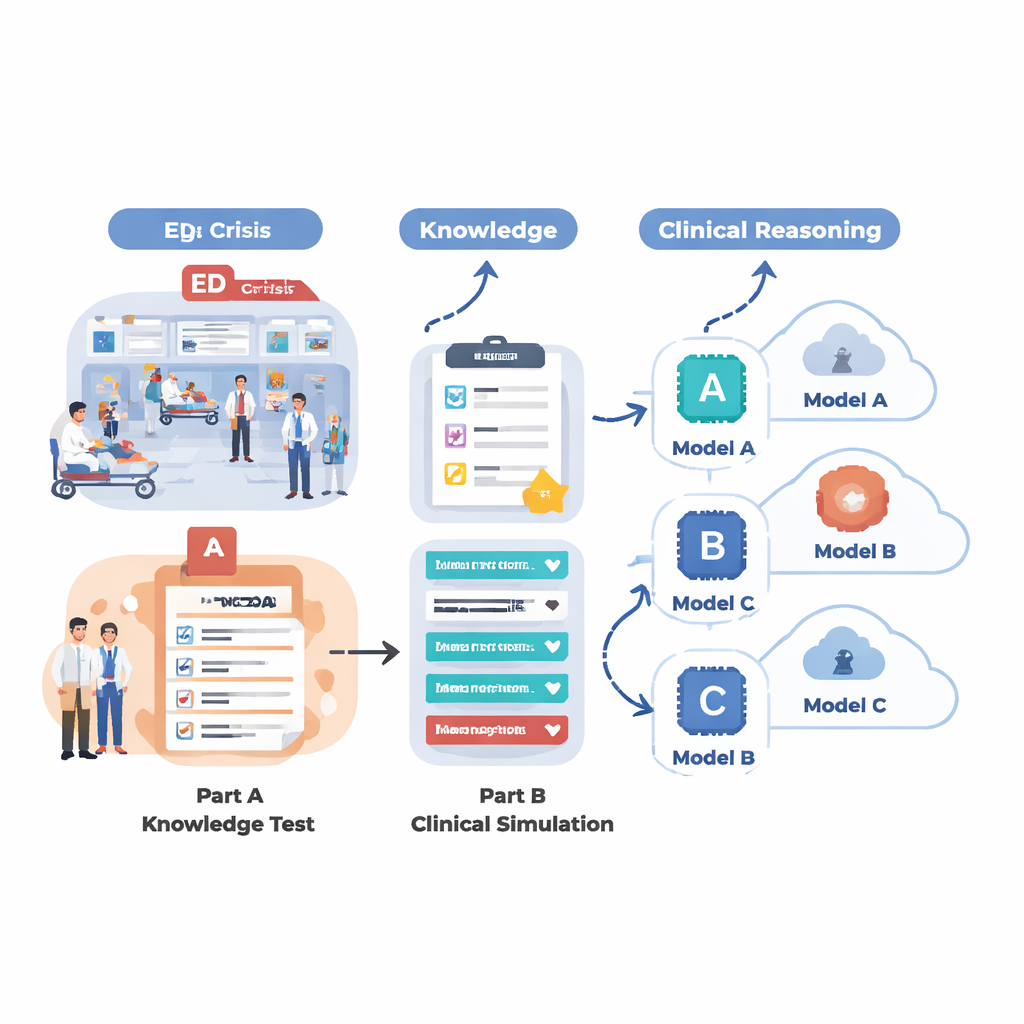
Notaufnahmen unter starkem Druck
Das Paper beginnt mit der Darstellung einer sich zuspitzenden Krise in der Notfallversorgung, insbesondere in den Vereinigten Staaten. Eine alternde Bevölkerung und der Anstieg chronischer Erkrankungen treiben die Rekordzahlen an Notaufnahmebesuchen – allein 2022 waren es rund 155 Millionen. Zugleich sehen sich Krankenhäusern schwere Engpässe bei Pflegekräften und Ärzten gegenüber, und die Zahl der Betten pro Person ist in den vergangenen Jahrzehnten gesunken. Ein fragmentiertes Gesundheitssystem erschwert die Koordination der Versorgung, was das Risiko für Verzögerungen und Fehler erhöht. Vor diesem Hintergrund argumentieren die Autorinnen und Autoren, dass dringend neue Werkzeuge nötig sind, um Klinikpersonal beim Triage-Management, schnellen Entscheidungsfindungen und der Dokumentation zu unterstützen, ohne deren Arbeitslast zu vergrößern.
Wie die Forschenden medizinische KI getestet haben
Um zu prüfen, was heutige KI-Systeme tatsächlich in einer notaufnahmeähnlichen Umgebung leisten können, entwarf das Team eine zweigeteilte Bewertung. Zunächst testeten sie 18 verschiedene Sprachmodelle anhand einer großen Menge Multiple-Choice-Fragen aus MedMCQA, einem prüfungsähnlichen medizinischen Datensatz, der 12 häufige Notfallbeschwerden abdeckt – etwa Brustschmerz, Atemnot, Kopfschmerz und Bauchschmerz. Diese Phase erfasste das grundlegende medizinische Wissen: konnte die KI aus vier Antwortmöglichkeiten die richtige auswählen – über tausende Fragen hinweg? Im zweiten Schritt wählten sie die fünf stärksten Modelle aus dieser Runde aus und ließen sie 12 realistische Notfallfälle schrittweise durchgehen, genauso wie ein Arzt es tun würde. Für jeden Fall musste die KI den Patienten zusammenfassen, eine Dringlichkeits-Triage einstufen, wichtige Anschlussfragen vorschlagen, Behandlungsmaßnahmen empfehlen und wahrscheinliche Diagnosen aufzählen, während nach und nach neue Informationen (Vitalzeichen, Anamnese, Untersuchungsbefunde, Labor- und Bildgebungsdaten) bekannt wurden.
Welche Modelle kannten die Fakten — und welche konnten schlussfolgern
Beim bloßen Faktenwissen lieferten mehrere Modelle beeindruckende Leistungen. Ein spezialisiertes System namens LLaMA 4 Maverick erzielte etwa 91 Prozent Gesamtgenauigkeit bei den medizinischen Fragen, dicht gefolgt von LLaMA 3.1, GPT-4.5, GPT-5 und Claude 4. Diese Spitzenmodelle zeigten durchgehend starke Ergebnisse über verschiedene Hauptbeschwerden hinweg, was darauf hindeutet, dass fortschrittliche AIs beim lehrbuchartigen medizinischen Wissen möglicherweise an eine Grenze kommen. Mittelklassige Systeme lagen deutlich zurück, einige nur bei rund 60 Prozent und zeigten Schwächen in Schlüsselbereichen wie Wundversorgung und Atemwegserkrankungen. Sobald die Aufgabe jedoch vom Beantworten isolierter Fragen auf das schlussfolgernde Durcharbeiten komplexer, sich entwickelnder Patientengeschichten wechselte, wurden die Unterschiede deutlicher. In diesen klinischen Simulationen hob sich GPT-5 klar ab: Es lieferte die genauesten und vollständigsten Zusammenfassungen, stellte die hilfreichsten Anschlussfragen, empfahl sinnvolle und sichere nächste Schritte und bot die ausführlichsten und am besten geordneten Listen möglicher Diagnosen.
Stärken, Schwächen und Sicherheitsbedenken
Klinikerinnen und Kliniker bewerteten die Ausgaben jeder KI sorgfältig hinsichtlich Genauigkeit, Relevanz und Sicherheit. GPT-5 erzielte nicht nur die höchsten Gesamtwerte; es war auch das einzige Modell, dessen Leistung bei zunehmender Komplexität der Fälle stabil blieb oder sich verbesserte, während Halluzinationen und schwerwiegende Fehler unter etwa 2 Prozent blieben. Andere Modelle zeigten charakteristische Schwächen. Einige übersahen Nebendiagnosen oder reihten kleinere Probleme vor gefährlichen ein. Andere wurden übermäßig vorsichtig oder vage, oder fokussierten sich zu schnell auf eine einzelne Diagnose. Insgesamt unterschätzten die meisten Systeme bei der Triage, wie schwer krank Patienten tatsächlich waren – eine konservative Verzerrung, die dringende Versorgung verzögern könnte, wenn sie nicht korrigiert wird. Die Ergebnisse unterstreichen einen zentralen Punkt: Medizinische Fakten zu kennen ist nicht gleichbedeutend damit, diese Fakten zuverlässig in sichere, schrittweise Entscheidungen einzubetten, wenn Informationen unvollständig, unübersichtlich und im Fluss sind.

Was das für künftige Notaufnahmebesuche bedeuten könnte
Die Autorinnen und Autoren kommen zu dem Schluss, dass mehrere moderne AIs inzwischen in medizinischem Wissen miteinander konkurrieren, GPT-5 jedoch insbesondere eine neue Stufe der Schlussfolgerungsfähigkeit zeigt, die es als Entscheidungsunterstützungswerkzeug in Notaufnahmen nützlich machen könnte. Sie betonen, dass diese Systeme nicht bereit sind, klinisches Personal zu ersetzen oder eigenständig zu handeln. Stattdessen sei die vielversprechendste kurzfristige Rolle die eines überwachten Assistenten – etwa zur Unterstützung von Triage-Pflegekräften bei der Einschätzung der Dringlichkeit, zum Entwurf von Patientenzusammenfassungen, zum Vorschlag von Fragen oder Untersuchungen und zur Überprüfung, ob ernsthafte Diagnosen bedacht wurden. Die Studie hebt auch hervor, dass weitere Forschung in realen klinischen Umgebungen nötig ist, begleitet von strengen Sicherheitsprüfungen und klaren Nutzungsregeln. Für Patientinnen und Patienten lautet die Botschaft vorsichtige Zuversicht: KI wird besser darin, medizinische Probleme zu durchdenken, doch ihr sicherer Einsatz in der Notaufnahme wird von sorgfältiger Gestaltung, Aufsicht und dem fortgesetzten Ziel abhängen, das menschliche Urteil von Ärztinnen, Ärzten und Pflegekräften zu unterstützen – nicht zu ersetzen.
Zitation: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Schlüsselwörter: Notfallmedizin, große Sprachmodelle, klinische Entscheidungsunterstützung, Triage, Benchmarking medizinischer KI