Clear Sky Science · de
Behebung von Multiply-Accumulate‑Rechenfehlern in Processing-in-Memory mit LDPC
Warum die Korrektur von In‑Memory‑Rechenfehlern wichtig ist
Moderne KI‑Chips holen mehr Geschwindigkeit und Effizienz aus der Hardware, indem sie Berechnungen direkt im Speicher ausführen, anstatt kontinuierlich Daten zwischen getrennten Prozessoren hin- und herzuschieben. Dieser „Processing‑in‑Memory“-Ansatz spart Energie, bringt jedoch ein ernstes Problem mit sich: winzige elektrische Unzulänglichkeiten können gespeicherte Bits umkippen oder analoge Signale verzerren und so stillschweigend die Genauigkeit von Aufgaben wie Bilderkennung verschlechtern. Das Papier beschreibt eine neue Methode, diese Fehler automatisch und in Echtzeit zu erkennen und zu korrigieren, wodurch künftige KI‑Hardware sowohl schnell als auch vertrauenswürdig bleibt.
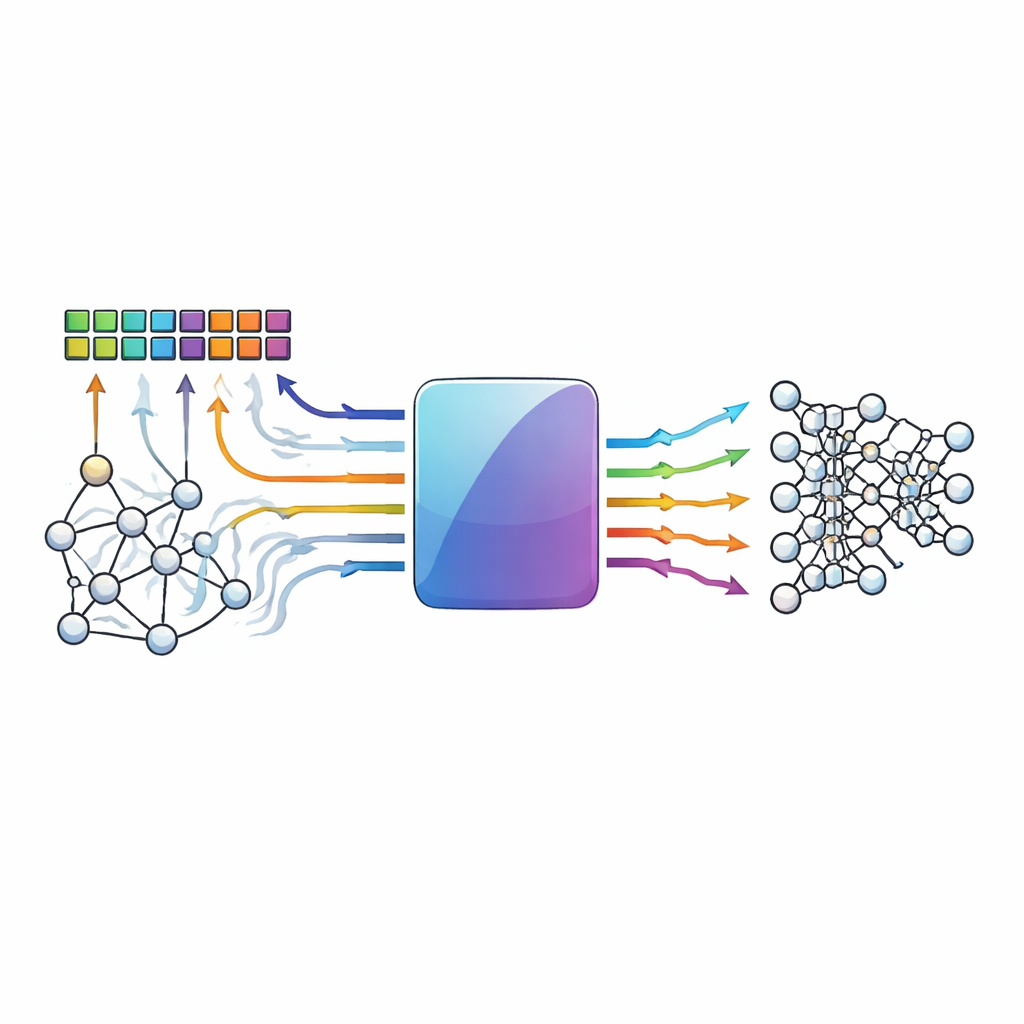
Rechnen dort, wo die Daten liegen
Konventionelle Computer werden durch das Bewegen von Daten zwischen Speicher und Prozessor ausgebremst. Processing‑in‑Memory‑Designs umgehen dieses Nadelöhr, indem sie Multiply‑and‑Accumulate‑Operationen — das Rückgrat neuronaler Netze — innerhalb dichter Speicherzellen‑Arrays ausführen. Emerging Devices wie resistiver RAM und andere memristive Bauelemente sind besonders attraktiv, weil sie viele Werte speichern und analoge Rechenoperationen sehr effizient durchführen können. Genau die analoge Natur und Gerätevariabilität, die sie leistungsfähig machen, machen sie aber auch störanfällig: thermische Fluktuationen, Geräteunterschiede und Spannungsabfälle können gespeicherte Werte oder berechnete Ergebnisse von ihren Sollwerten wegdriften lassen.
Wenn sich winzige Störungen aufsummieren
In diesen In‑Memory‑Arrays werden viele Zeilen von Zellen gleichzeitig aktiviert und ihre Beiträge über gemeinsame Leitungen aufsummiert. Je mehr Zeilen beteiligt sind, desto mehr addieren sich ihre einzelnen Unvollkommenheiten und erzeugen Fehlerbilder, die sowohl häufig als auch komplex sind. Statt eines einzelnen falschen Bits beobachten Entwickler oft mehrere Fehler, die in derselben Spalte einer Matrix gebündelt sind oder sich über mehrere Spalten verteilen, sodass traditionelle Fehlerkorrekturverfahren versagen. Standardcodes gehen meist von einfachen Fehlermustern und kurzen Wortlängen aus; sie übersehen Multi‑Bit‑Störungen oder haben keine Einträge in ihren Nachschlagetabellen für seltene, aber schädliche Kombinationen. Infolgedessen kann die Modellgenauigkeit tiefer neuronaler Netze stark abfallen, sobald die zugrunde liegende Hardware auch nur mäßig unzuverlässig wird.
Ein neues digitales Sicherheitsnetz
Die Autoren stellen einen nicht‑binären Low‑Density Parity‑Check (NB‑LDPC)‑Code vor, der speziell auf Processing‑in‑Memory‑Hardware zugeschnitten ist. Anstatt nur mit Nullen und Einsen zu arbeiten, operiert ihr Schema auf kleinen Bitgruppen, die als Symbole in einer mathematischen Struktur behandelt werden — einem endlichen Körper, der hier auf einer Primzahl (drei) basiert. Dadurch kann derselbe Code sowohl gewöhnlichen binären Speicher als auch mehrstufige oder differentielle Kodierungen schützen, wie sie in analogen Beschleunigern üblich sind. Das System hängt jedem Datenblock eine moderate Anzahl zusätzlicher Symbole — Prüfsymbole — an. Sowohl bei normalen Speicherzugriffen als auch bei In‑Memory‑Multiply‑and‑Accumulate‑Operationen berechnet die Hardware die Ergebnisse für die Daten und die Prüfsymbole gemeinsam, sodass die Fehlererkennung natürlich in die Berechnung eingebettet ist.
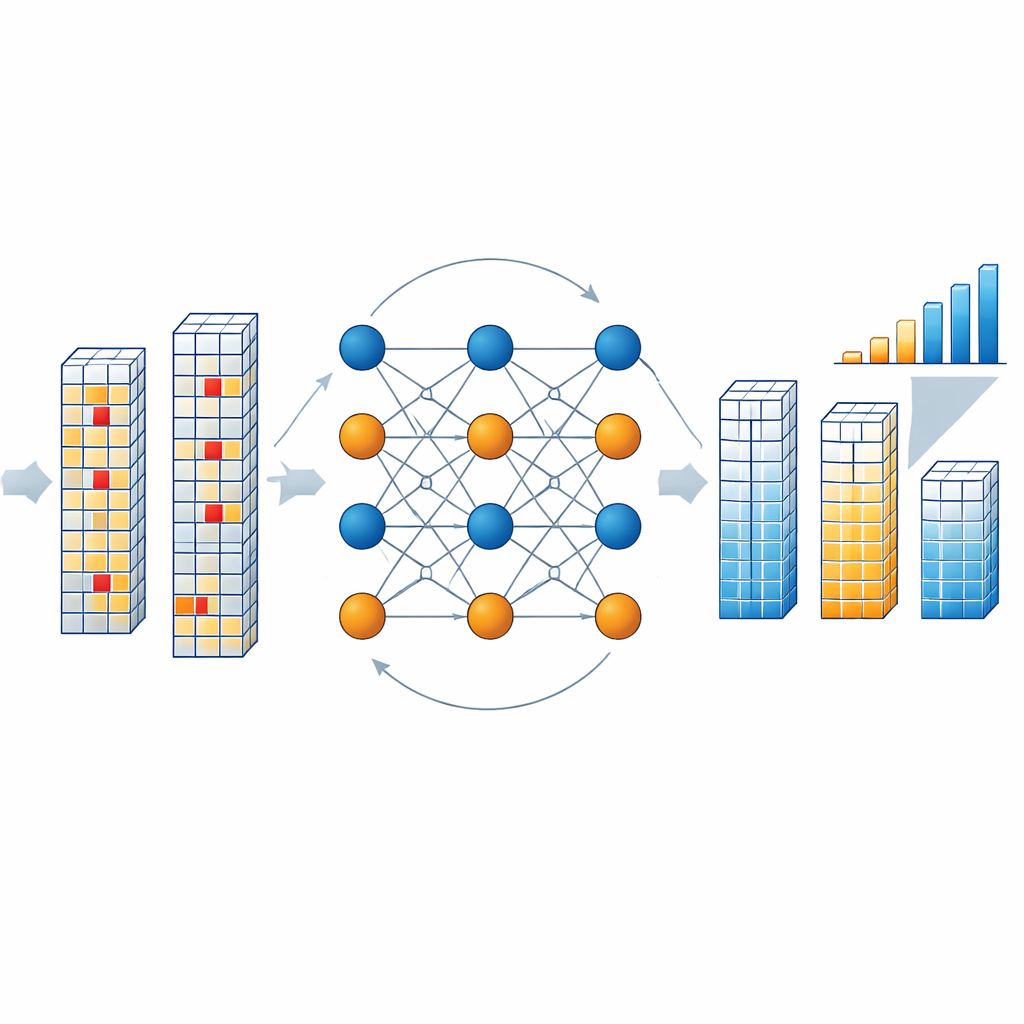
Wie die Korrektur‑Engine im Chip arbeitet
Wenn der Chip einen Ergebnisblock ausliest, prüft ein dedizierter Decoder, ob die kombinierten Daten‑ und Prüfsymbole die vom Code definierten Paritätsbeziehungen einhalten. Falls ja, wird der Block als sauber angenommen. Falls nicht, startet der Decoder einen iterativen Prozess, in dem abstrakte „Variable Nodes“, die jedes Symbol repräsentieren, und „Check Nodes“, die Paritätsbedingungen darstellen, Wahrscheinlichkeitsnachrichten austauschen. Diese Nachrichten schätzen, wie wahrscheinlich jedes Symbol jeden erlaubten Wert annimmt, basierend auf den beobachteten Ausgaben und der erwarteten Bit‑Flip‑Fehlerrate des Speichers. Die Autoren vereinfachen diese mathematikintensive Herleitung mithilfe von Manhattan‑Distanz‑Näherungen, die die Hardwarekosten erheblich senken und zugleich die Leistung hoch halten. Nach wenigen Runden — typischerweise drei — konvergiert der Decoder auf die plausibelste korrigierte Version des Ergebnisvektors, ohne den Speicher erneut auslesen oder den Berechnungsstrom anhalten zu müssen.
Silizium‑Beleg und Auswirkungen auf KI‑Genauigkeit
Um die Idee praktisch zu testen, baute das Team einen Prototyp‑Chip in einem 40‑Nanometer‑Prozess, der ein resistives RAM‑Array, leichte Analog‑zu‑Digital‑Wandler und den neuen NB‑LDPC‑Decoder kombiniert. Mit einer Konfiguration, die 256 Informationssymbole mit 32 Prüfsymbolen schützt, erreicht der Decoder eine hohe Code‑Rate (etwa 0,8), eine gemessene Spitzenenergieeffizienz von ungefähr 88 Terabit korrigierter Daten pro Sekunde und Watt sowie nur einen moderaten Flächenaufwand, der sich weiter verringern lässt, wenn ein Decoder mehrere Memory‑Macros teilt. Simulationen über viele Codegrößen zeigen, dass bei Schutz von 1024 Datensymbolen mit 128 Prüfsymbolen die Methode die Bit‑Fehlerrate nahezu um den Faktor 60 verbessern kann. Bei Anwendung auf ein ResNet‑34‑Bildklassifikationsmodell, das auf Processing‑in‑Memory‑Hardware läuft, stellt die Korrektur unter anspruchsvollen Fehlerbedingungen mehr als 20 Prozentpunkte verlorener Genauigkeit wieder her.
Was das für künftige KI‑Chips bedeutet
Praktisch gesprochen liefert die Arbeit ein robustes „Rechtschreib‑Prüfsystem“ für die Mathematik von Processing‑in‑Memory‑Hardware, das reichere Symbolmengen und komplexe Fehlerbilder versteht, ohne den Datenstrom zu verlangsamen. Indem Schutz für sowohl gespeicherte Daten als auch laufende Berechnungen vereinheitlicht und eine effiziente Silizium‑Implementierung demonstriert wird, zeigt die Studie, dass hochdichte, energiearme In‑Memory‑Beschleuniger nicht zu Lasten der Zuverlässigkeit gehen müssen. Diese Art maßgeschneiderter Fehlerkorrektur könnte zu einer Schlüsselkomponente werden, um künftige neuromorphe und KI‑Beschleuniger sowohl energieeffizient als auch zuverlässig genug für reale Anwendungen zu machen — von mobilen Geräten bis zu groß angelegten Rechenzentren.
Zitation: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Schlüsselwörter: processing-in-memory, Fehlerkorrektur, LDPC‑Codes, resistiver RAM, Hardware für neuronale Netze