Clear Sky Science · de
Eine Bewertung der schätzenden Unsicherheit in großen Sprachmodellen
Warum ungenaue Wörter über Risiko wirklich wichtig sind
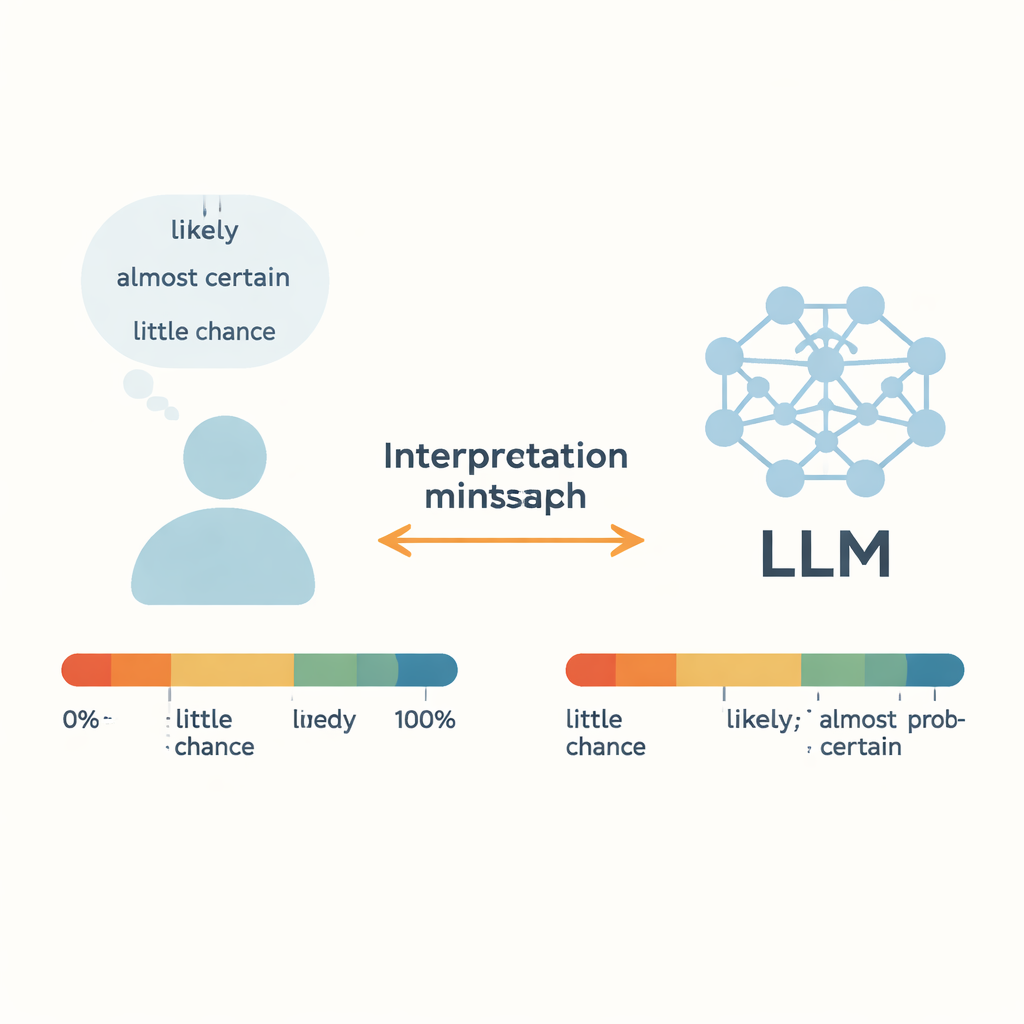
Wenn ein Arzt sagt, eine Behandlung sei „wahrscheinlich“ wirksam, oder ein Meteorologe warnt, es bestehe „geringe Wahrscheinlichkeit“ für einen Hurrikan, verlassen wir uns auf diese unscharfen Wörter, um reale Entscheidungen zu treffen. Heute beginnen große Sprachmodelle (LLMs), etwa Online-Chatbots, dieselbe Wortwahl zu verwenden. Diese Studie stellt eine einfache, aber entscheidende Frage: Bedeutet ein KI‑„wahrscheinlich“ dasselbe wie bei uns — und kann die KI verlässlich Rohzahlen in alltagsverständliche Unsicherheitsbegriffe umwandeln?
Alltägliche Unsicherheit unter dem Mikroskop
Die Autoren konzentrieren sich auf „Wörter schätzender Wahrscheinlichkeit“ (WEPs) — Begriffe wie „fast sicher“, „wahrscheinlich“ und „geringe Chance“, die Menschen anstelle exakter Prozentsätze verwenden. Frühere Arbeiten, die bis zu Geheimdienstanalyse in den 1960er Jahren zurückreichen, versuchten, diese Wörter per Umfragen mit numerischen Wahrscheinlichkeiten zu verknüpfen. Diese Studie vergleicht jene menschlichen Einschätzungen mit den Ausgaben von fünf modernen LLMs, darunter GPT‑3.5, GPT‑4, Metas Llama‑Modelle und ein chinesisches System namens ERNIE‑4.0. Für 17 geläufige Unsicherheitswörter erhielt jedes Modell kurze, erzählerische Eingaben auf Englisch oder Chinesisch und wurde gebeten, mit einer numerischen Wahrscheinlichkeit zwischen 0 und 100 Prozent zu antworten. Durch Wiederholung über viele Kontexte bauten die Autoren vollständige Wahrscheinlichkeitsverteilungen für jedes Wort und jedes Modell auf und verglichen diese dann mit menschlichen Umfragedaten.
Wo Menschen und KIs dieselbe Sprache sprechen
Bei den extremsten Ausdrücken — etwa „fast sicher“ am oberen Ende und „fast keine Chance“ am unteren Ende — stimmen LLMs und Menschen überraschend gut überein. Sowohl Menschen als auch Modelle tendieren dazu, diese Phrasen in engen, hohen bzw. niedrigen Wahrscheinlichkeitsbereichen zu gruppieren, was darauf hindeutet, dass diese starken Begriffe über Kontexte hinweg relativ stabile Bedeutungen haben. Dasselbe gilt für „ungefähr ausgeglichen“, das die meisten Menschen und Modelle als ungefähr 50‑50‑Chance behandeln. Statistische Tests zeigen für diese speziellen Wörter kaum nennenswerte Unterschiede zwischen menschlichen und modellbasierten Verteilungen, was darauf hindeutet, dass LLMs klare Fälle von nahezu Gewissheit oder nahezu Unmöglichkeit mit menschenähnlicher Präzision erfassen können.
Wo Bedeutungen leise auseinanderdriften
Ambivalente, mittlere Ausdrücke erzählen eine andere Geschichte. Für Formulierungen wie „wahrscheinlich“, „vermutlich“, „wir bezweifeln“ und „geringe Chance“ weichen die numerischen Interpretationen der Modelle deutlich von menschlichen Einschätzungen ab. GPT‑4, obwohl insgesamt leistungsfähiger als GPT‑3.5, zeigt oft größere Lücken. Die Autoren vermuten, dass solche Wörter zwei Dinge vermischen: ein Wahrscheinlichkeitsgefühl und die Haltung oder Einstellung des Sprechers. In echten Gesprächen kann „wahrscheinlich“ je nach Ton und Kontext zurückhaltend oder zuversichtlich klingen, und „wir bezweifeln“ kann Skepsis statt einer genauen Wahrscheinlichkeit ausdrücken. Da LLMs auf umfangreichen, genreübergreifenden Internettexten trainiert sind, mitteln sie möglicherweise über viele widersprüchliche Verwendungen hinweg und verwischen diese Feinheiten. Das Ergebnis ist eine versteckte Fehlanpassung: Menschen und KIs können denselben Satz sehen und stillschweigend unterschiedliche Zahlen an dasselbe Wort knüpfen.
Geschlecht, Sprache und kulturelle Echos
Die Forscher prüften außerdem, wie geschlechtsspezifische Formulierungen und verschiedene Sprachen diese Wahrscheinlichkeitswörter formen. Wenn Eingaben sich auf „er“ oder „sie“ statt auf geschlechtsneutrale Subjekte bezogen, produzierten GPT‑3.5 und GPT‑4 oft weniger variable, stärker „festgezurrte“ Wahrscheinlichkeitsabschätzungen, die manchmal auf einen einzelnen Punkt zusammenfielen. Das deutet darauf hin, dass die Modelle starre Muster aus Stereotypen in ihren Trainingsdaten aufgenommen haben könnten, obwohl die Gesamtdurchschnitte für männliche und weibliche Eingaben ähnlich waren. Beim Vergleich englischer und chinesischer Eingaben zeigten die GPT‑Modelle spürbare Verschiebungen in der Interpretation derselben Unsicherheitswörter. ERNIE‑4.0, hauptsächlich auf chinesischen Texten trainiert, kam vielen chinesischsprechenden Menschen bei zahlreichen Begriffen näher, entsprach aber weiterhin bei bestimmten Phrasen nicht genau. Diese Befunde betonen, dass die Art und Weise, wie eine KI über Unsicherheit spricht, nicht nur vom gewählten Wort abhängt, sondern auch von den sprachlichen und kulturellen Mustern in ihrem Training.
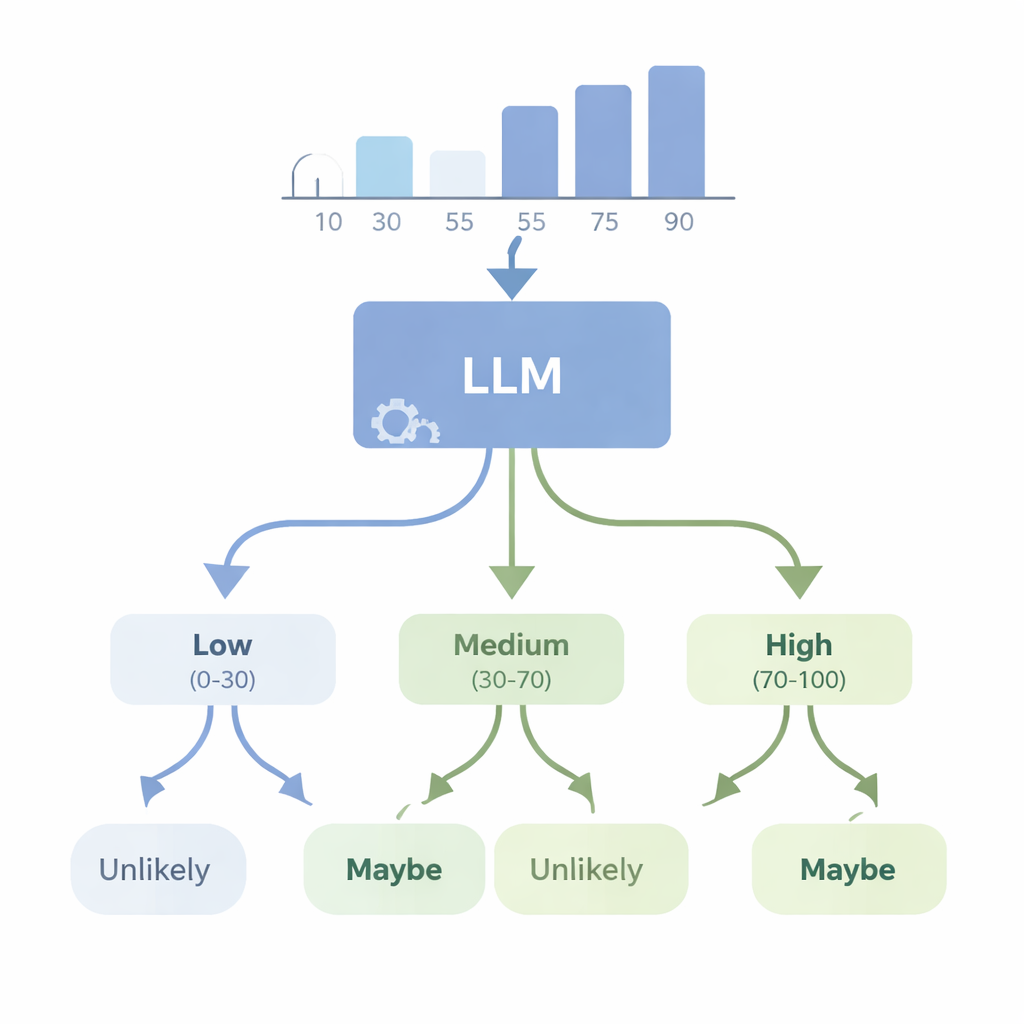
Können KIs Zahlen in alltagssprachliche Zweifel übersetzen?
In einem zweiten Experiment betrachteten die Autoren das umgekehrte Problem: Kann ein fortgeschrittenes Modell wie GPT‑4 aus numerischen Daten starten und ein passendes Unsicherheitswort wählen? Sie fütterten das Modell mit einfachen Datensätzen — etwa Listen von Körpergrößen oder Testergebnissen — und baten es, das am besten passende WEP auszuwählen (zum Beispiel „fast sicher“, „wahrscheinlich“, „vielleicht“, „unwahrscheinlich“ oder „so gut wie ausgeschlossen“) für Aussagen über zukünftige Ergebnisse. Anschließend bewerteten sie GPT‑4 mit vier neuen „Konsistenz“-Punkten, die prüfen, ob seine Wortwahl logisch sinnvoll ist, wenn Wahrscheinlichkeiten steigen oder fallen, wenn komplementäre Ereignisse beschrieben werden und wenn die zugrunde liegenden Zahlen kontrolliert verändert werden. GPT‑4 schnitt deutlich besser als Zufallsraten ab und konnte oft grobe Veränderungen in der Wahrscheinlichkeit verfolgen, blieb aber weit von perfekter Konsistenz entfernt. In einigen Tests antwortete es annähernd gleich über verschiedene Vertrauensebenen hinweg, was darauf hindeutet, dass es diese Wörter manchmal als breite Etiketten statt als fein abgestufte Skala behandelt, die eng an die tatsächlichen Daten gebunden ist.
Was das für reale Entscheidungen bedeutet
Für die Leser ist die Botschaft vorsichtig, aber nicht alarmistisch. LLMs können unsere stärksten Ausdrücke von Gewissheit und Unmöglichkeit bereits nachahmen und oft Daten in angemessene „wahrscheinlich“‑ oder „unwahrscheinlich“‑Aussagen zusammenfassen. Diese Studie zeigt jedoch, dass bei vielen alltäglichen Unsicherheitswörtern ihre interne Kalibrierung nicht vollständig mit menschlicher Intuition übereinstimmt und ihre Zuordnung von Zahlen zu Sprache inkonsequent sein kann. In Bereichen wie Medizin, Politik oder Wissenschaftskommunikation — wo kleine Verschiebungen in der Formulierung von Risiko oder Zuversicht wichtig sein können — ist das „wahrscheinlich“ eines Modells möglicherweise nicht dasselbe wie Ihres. Die Autoren argumentieren, dass wir diese Systeme sicher nutzen können, wenn wir Unsicherheitswörter als gemeinsamen Code betrachten, der noch sorgfältig abgestimmt und getestet werden muss und vielleicht durch explizite numerische Angaben ergänzt werden sollte, anstatt vorauszusetzen, dass Mensch und Maschine automatisch dasselbe meinen.
Zitation: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Schlüsselwörter: Unsicherheit Sprache, große Sprachmodelle, Wahrscheinlichkeitswörter, Mensch-KI-Kommunikation, Risikodeutung