Clear Sky Science · de
Ein interpretierbares Machine-Learning-Modell zur Vorhersage der Prognose von Medulloblastomen unter Einbindung genetischer und klinischer Merkmale
Warum diese Studie für Familien wichtig ist
Für Familien, die mit einem Medulloblastom konfrontiert sind – einem schnell wachsenden Hirntumor, der vor allem Kinder betrifft – gehört zu den schwierigsten Fragen: „Wie sieht die Zukunft für mein Kind aus?“ Die heutigen Behandlungspläne stützen sich meist auf breite Risikogruppen statt auf die individuelle Kombination aus Krankengeschichte, Tumorbiologie und Bestrahlungsdetails jedes einzelnen Patienten. Diese Studie zeigt, wie ein interpretierbares Machine-Learning-Verfahren diese Informationen zusammenführen kann, um klarere, individualisierte Vorhersagen zur Langzeitüberlebenswahrscheinlichkeit zu liefern und so potenziell eine sicherere und wirkungsvollere Behandlung zu unterstützen.
Ein genauerer Blick auf einen häufigen kindlichen Hirntumor
Das Medulloblastom entsteht im Kleinhirn und macht etwa einen von fünf kindlichen Hirntumoren aus. Viele Kinder überleben inzwischen mindestens fünf Jahre nach der Diagnose, aber die Ergebnisse variieren weiterhin stark, insbesondere bei als hoch riskant eingestuften Fällen. Die Standardbehandlung umfasst meist eine Operation, gefolgt von Bestrahlung von Gehirn und Rückenmark, häufig kombiniert mit Chemotherapie. Solche intensiven Therapien können Leben retten, hinterlassen bei Überlebenden aber oft ernsthafte Langzeitfolgen, etwa Lernschwierigkeiten oder neurologische Beeinträchtigungen. Ärztinnen und Ärzte stehen daher vor dem sensiblen Abwägen: genug Behandlung, um ein Wiederauftreten zu verhindern, aber nicht so viel, dass die Lebensqualität stark leidet.
Verschiedene Informationsbausteine zusammenführen
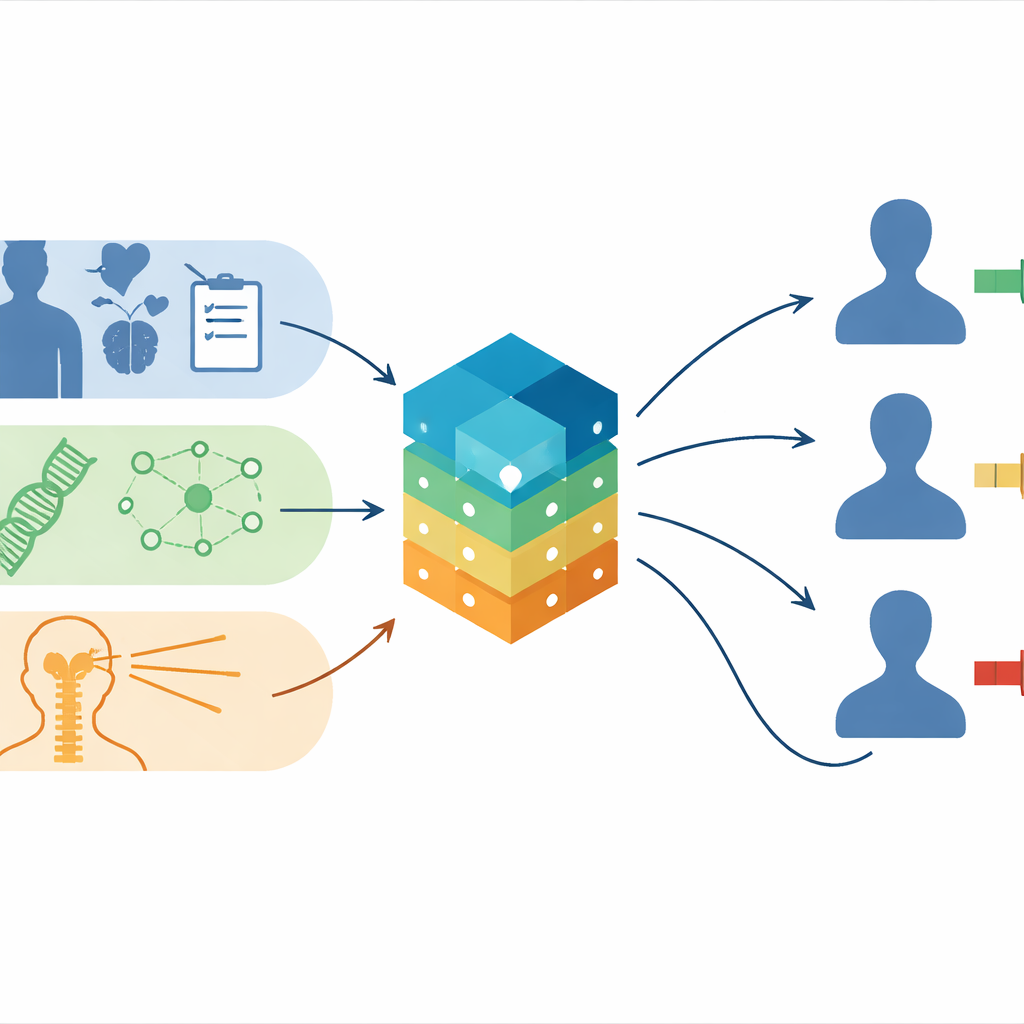
Um Prognoseinstrumente zu verbessern, stellten die Forschenden einen der bisher umfangreichsten Datensätze für diese Erkrankung zusammen. Sie sammelten detaillierte Aufzeichnungen von 729 Personen, die zwischen 2001 und 2023 in chinesischen Zentren behandelt wurden, sowie 201 zusätzliche Patienten aus internationalen Kooperationen. Für jeden Patienten wurden Alter, Geschlecht, Tumorausbreitung bei Diagnosestellung, mikroskopischer Tumortyp, Operationsergebnis, Strahlendosis an Gehirn und Rückenmark, Chemotherapieeinsatz und zentrale genetische Merkmale des Tumors berücksichtigt, einschließlich der Aktivität von Genen wie MYC, MYCN, OTX2 und GFI1. Da nicht alle Kliniken oder Patienten dieselbe Datenqualität liefern können, entwickelten die Forschenden vier Modellversionen: eine mit klinischen, molekularen und Radiotherapie-Daten; eine mit klinischen und molekularen Daten; eine mit klinischen und Radiotherapie-Daten; und eine, die nur grundlegende klinische Informationen nutzt.
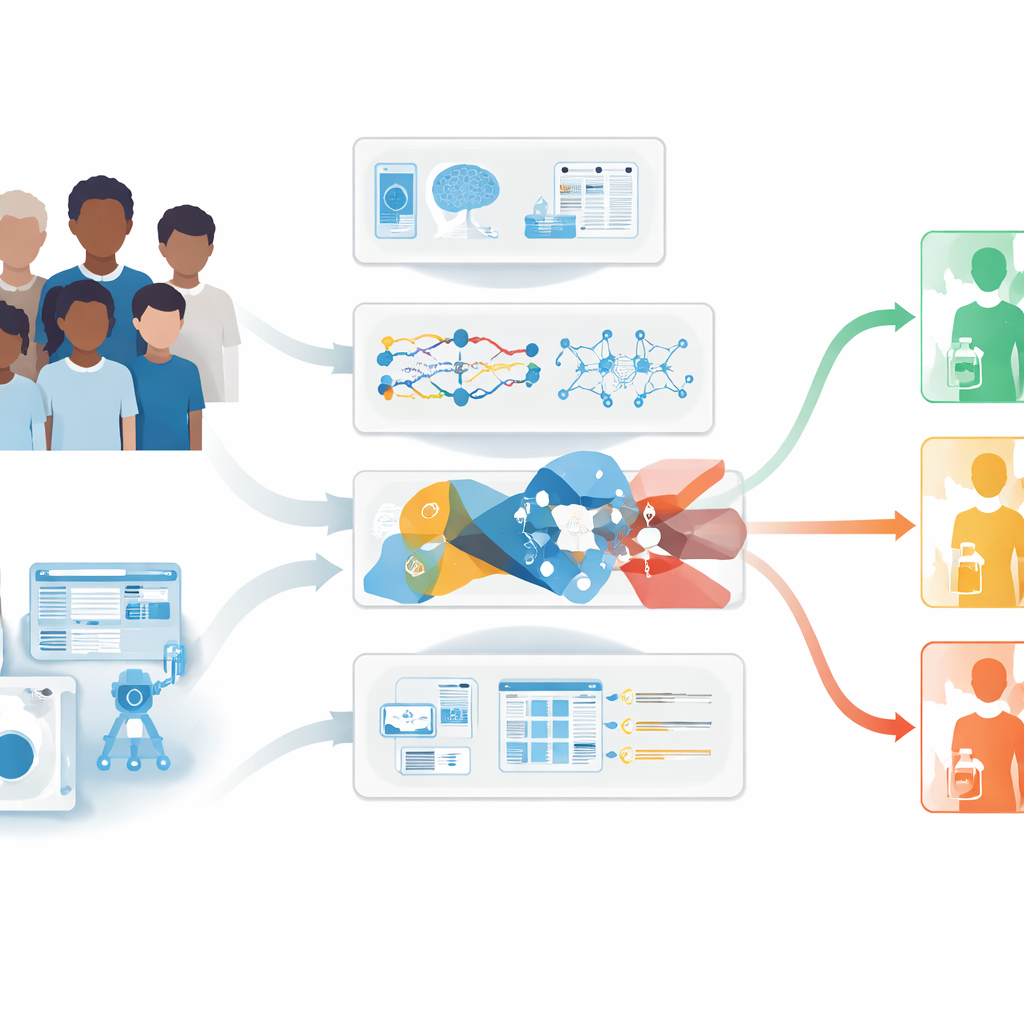
Wie Machine Learning Daten in Vorhersagen verwandelt
Das Team verglich sechs verschiedene Überlebensanalyse-Algorithmen, um zu ermitteln, welche am besten vorhersagen, wie lange Patienten nach der Behandlung leben. Dazu gehörten traditionelle statistische Ansätze ebenso wie moderne Machine-Learning-Methoden wie XGBoost und Gradient-Boosting-Maschinen. Die Modelle wurden an einem Teil des chinesischen Datensatzes trainiert und an den übrigen Patienten getestet; anschließend prüften die Forschenden die Leistung erneut anhand des internationalen Kollektivs. In allen vier Datenszenarien lieferten XGBoost und Gradient-Boosting-Modelle insgesamt die zuverlässigsten Vorhersagen für das Gesamtüberleben nach einem, drei, fünf und zehn Jahren, mit guter Übereinstimmung zwischen vorhergesagten und beobachteten Ergebnissen. Wichtig ist: Wenn molekulare und Strahlendaten verfügbar waren, verbesserten diese Angaben die Modellleistung gegenüber reinen klinischen Daten.
Was für das Ergebnis am wichtigsten ist
Da „Black-Box“-Vorhersagen in der Medizin schwer zu vertrauen sind, nutzten die Forschenden eine Technik namens SHAP, um aufzuzeigen, wie jeder Faktor die Entscheidungen des Modells beeinflusste. Die Analyse hob mehrere besonders einflussreiche Variablen hervor: ob der Krebs bereits im Gehirn oder Rückenmark gestreut hatte, die molekulare Untergruppe des Tumors und die Aktivität bestimmter Gene – insbesondere GFI1, MYC und MYCN. Eine hohe Aktivität einiger dieser Gene und das Vorhandensein von Metastasen standen mit einer schlechteren Überlebensprognose in Zusammenhang. Auf der Behandlungsebene waren höhere Strahlendosen an das Tumorbett im hinteren Bereich des Gehirns mit besseren Ergebnissen verbunden, und in einigen Gruppen reduzierte die Kombination aus Bestrahlung und Chemotherapie das Risiko. Indem das System zeigt, welche Merkmale das Risiko für eine einzelne Person nach oben oder unten treiben, bietet es Ärztinnen, Ärzten und Familien eine transparentere Erklärung dafür, warum eine bestimmte Vorhersage getroffen wird.
Komplexe Modelle in praktische Werkzeuge überführen
Um über die Theorie hinauszugehen, entwickelten die Autorinnen und Autoren interaktive Webanwendungen auf Basis ihrer leistungsfähigsten Modelle. Kliniker können dort Informationen wie Alter des Patienten, Tumorausbreitung, molekulare Untergruppe, Strahlendosis und, falls vorhanden, Genaktivität eingeben. Die Anwendungen zeigen dann personalisierte Überlebenskurven über die Zeit und erläutern, welche Faktoren am stärksten zur Prognose dieses Patienten beitragen. In Situationen, in denen molekulare Daten oder Dosisinformationen fehlen – häufig in ressourcenbeschränkten Umgebungen – können vereinfachte Modellversionen dennoch nützliche Orientierung bieten und so die Inklusivität der Methode sichern.
Was das für Patientinnen, Patienten und Behandlungsteams bedeutet
Im Kern legt diese Arbeit nahe, dass sorgfältig entwickelte, interpretierbare Machine-Learning-Tools helfen können, vorherzusagen, wie Kinder mit Medulloblastom voraussichtlich abschneiden, indem sie ein detaillierteres Bild der Erkrankung nutzen als bisher üblich. Die Modelle ersetzen nicht die klinische Einschätzung und müssen weiter verfeinert werden—insbesondere zur Vorhersage von Tumorrezidiven—, sie bieten jedoch eine Möglichkeit, Risikogespräche individueller zu führen, Bestrahlungspläne gezielter anzupassen und Nachsorge besser an die Situation jedes Kindes anzupassen. Für Familien kann das bedeuten, fundiertere, persönlichere Entscheidungen zu treffen und einen klareren Eindruck von dem Weg vor ihnen zu bekommen.
Zitation: Su, Y., Deng, K., Chen, X. et al. An interpretable machine learning model for predicting prognosis of medulloblastoma integrating genetic and clinical features. Commun Med 6, 134 (2026). https://doi.org/10.1038/s43856-026-01454-4
Schlüsselwörter: Medulloblastom, pädiatrische Hirntumoren, Maschinelles Lernen Prognose, Strahlentherapie-Dosis, Tumorgenetik